Strategy One
Python データ ソース スクリプトを記述
MicroStrategy ONEから開始 Update 11, Python データ ソースを使用するには、データ ソースの接続として使用される Python スクリプトを記述する必要があります。
データ ソース スクリプト関数
データ ソース スクリプトでは、次の 3 つの関数を使用する必要があります:
-
browse()コピーdef browse():
"""
Description: retrieve the catalog information.
Input: no input is needed for this function.
Return: the result is returned as a dict object.The keys of the dict should be
table names of the python data source, and the values are normalized in Pandas
DataFrame format. Each DataFrame value will contain a table's column infos.
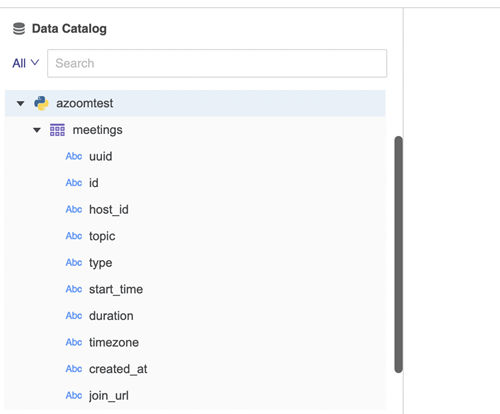
"""このブラウズ機能は、ユーザーが Python コネクターを介してデータ ソースに接続しようとしたときにトリガーされます。データ ソースが接続すると、データ ソースのすべてのカタログ情報が返されます。テーブル名と列はデータ ソースの下に表示されます。
-
preview()コピーdef preview(table_name, row_limit):
"""
Description: get partial data for preview, data refine and schema change
Input: there are 2 parameters for preview.
- table_name: a table name should be selected if someone want to preview
the table.
- row_limit: the row limitation is used to define the scale when only
partial data is retrieved during the preview.
Return: the result is returned as a Pandas DataFrame format object. Only the
"row_limit" rows would be returned in the DataFrame object.
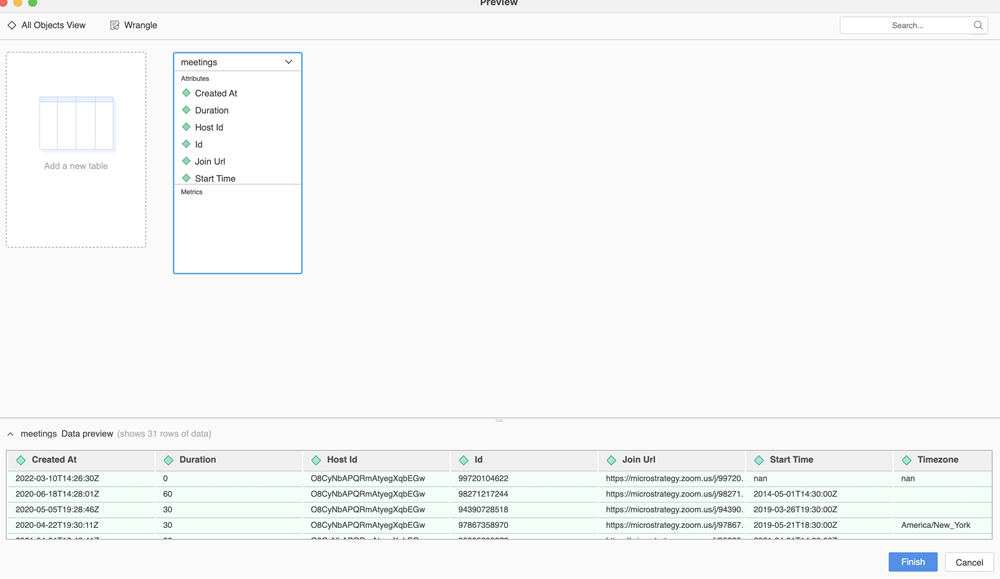
"""プレビュー機能は、ダブルクリックしてテーブルを追加するか、 をクリックしてテーブルをプレビューしたときにトリガーされます。
-
publish()コピーdef publish(table_name):
"""
Description: get the data published and stored the data into the cube
Input: the table_name parameter is needed to define witch table should
be published.
Return: the result is returned as a Pandas DataFrame format object. All
data needs to be returned for publishing.
"""ユーザーが [保存] をクリックしてキューブを公開したときに、公開関数がトリガーされます。テーブルのすべてのデータは、ユーザーが使用できるように取得されます。
Pandas データフレームの詳細については、アップグレードまで 10 分。
データ ソース スクリプト例
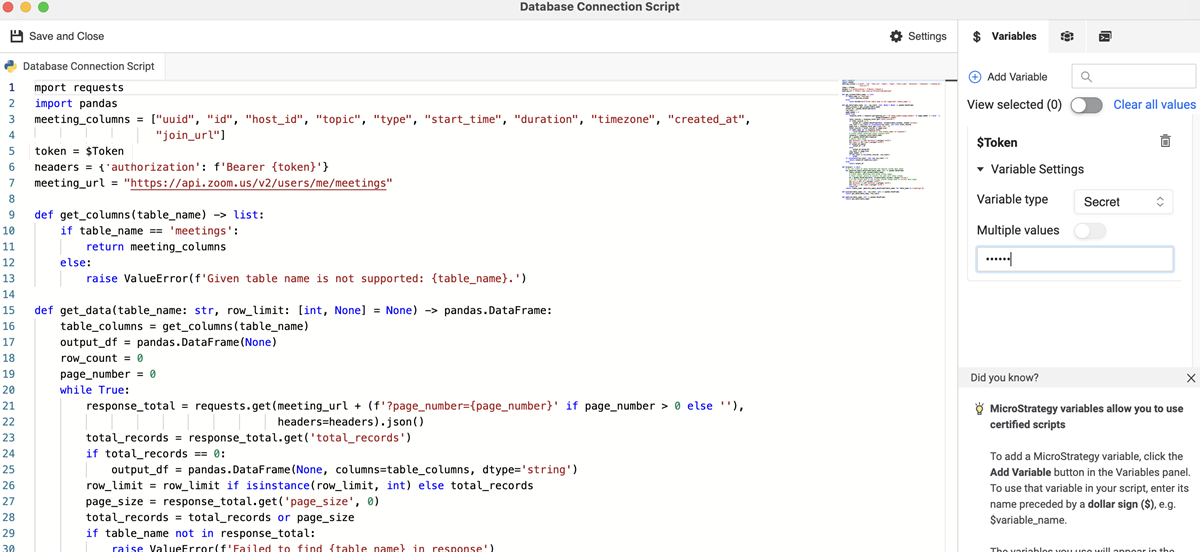
以下のズーム コネクターの例を参照してください。ユーザーは、Python データ ソースの API を使用してズーム リソースに接続し、必要なデータを取得できます。この例では、認証用のデータ ソース スクリプトにトークンという変数が含まれています。
import requests
import pandas
meeting_columns = ["uuid", "id", "host_id", "topic", "type", "start_time", "duration", "timezone", "created_at",
"join_url"]
token = $Token
headers = {'authorization': f'Bearer {token}'}
meeting_url = "https://api.zoom.us/v2/users/me/meetings"
def get_columns(table_name) -> list:
if table_name == 'meetings':
return meeting_columns
else:
raise ValueError(f'Given table name is not supported: {table_name}.')
def get_data(table_name: str, row_limit: [int, None] = None) -> pandas.DataFrame:
table_columns = get_columns(table_name)
output_df = pandas.DataFrame(None)
row_count = 0
page_number = 0
while True:
response_total = requests.get(meeting_url + (f'?page_number={page_number}' if page_number > 0 else ''),
headers=headers).json()
total_records = response_total.get('total_records')
if total_records == 0:
output_df = pandas.DataFrame(None, columns=table_columns, dtype='string')
row_limit = row_limit if isinstance(row_limit, int) else total_records
page_size = response_total.get('page_size', 0)
total_records = total_records or page_size
if table_name not in response_total:
raise ValueError(f'Failed to find {table_name} in response')
# Create pandas dataframe using response data
response = response_total[table_name]
df = pandas.DataFrame(response)
# Adjust data types
df['duration'] = df['duration'].astype('int32')
df['type'] = df['type'].astype('int32')
if output_df.empty:
output_df = df
else:
output_df.merge(df)
row_count += page_size
page_number += 1
if row_count >= min(total_records, row_limit):
break
if isinstance(row_limit, int) and row_limit > 0:
return output_df.head(row_limit)
else:
return output_df
def browse() -> dict:
# You can create an empty dataframe and specify column data types.
def generate_empty_dataframe(table_name: str) -> pandas.DataFrame:
table_columns = get_columns(table_name)
# Create empty dataframe with given column names.
# These columns should be exactly the same with table schema.
df = pandas.DataFrame(None, columns=table_columns, dtype='string')
# If the column data is not string, please change them to correct data types.
df['id'] = df['id'].astype('int64')
df['duration'] = df['duration'].astype('int32')
df['type'] = df['type'].astype('int32')
return df
return {table_name: generate_empty_dataframe(table_name) for table_name in ['meetings']}
def preview(table_name: str, row_limit: int) -> pandas.DataFrame:
return get_data(table_name, row_limit)
def publish(table_name: str) -> pandas.DataFrame:
return get_data(table_name)