MicroStrategy ONE
Connetti a Google Cloud Storage
Google Cloud Storage è un servizio online per l'archiviazione e l'accesso ai dati in Google Cloud Platform. MicroStrategy Cloud Object Connector consente di accedere a Google Cloud Storage per sfogliare rapidamente cartelle, file e importarli MicroStrategy cubi.
Questa pagina esplora i seguenti argomenti:
Preparare parametri di connessione
Affinché il connettore dell'oggetto cloud possa esplorare correttamente il file system di Google Cloud Storage, è necessario un account di servizio creato con le autorizzazioni adeguate. Non sono disponibili combinazioni di autorizzazioni per un ruolo di base in Google Cloud. MicroStrategy consiglia di creare un ruolo personalizzato per il connettore Google Cloud.
Al ruolo personalizzato devono essere aggiunte le seguenti autorizzazioni:
- storage.bucket.get
- storage.bucket.list
- storage.objects.get
- storage.objects.list
Dopo aver creato l'account di servizio, chiedere la chiave all'amministratore. La chiave è sotto forma di file JSON e sarà necessaria per un uso futuro.
Creare un ruolo DB
Accedi al connettore dell'oggetto cloud di Google Cloud Storage in MicroStrategy Web o Workstation.
- Web
- Workstation
- Scegliere Aggiungi dati > Nuovi dati.
-
Trovare e selezionare il Google Cloud Storage Connettore oggetto cloud dall'elenco di origini dati.
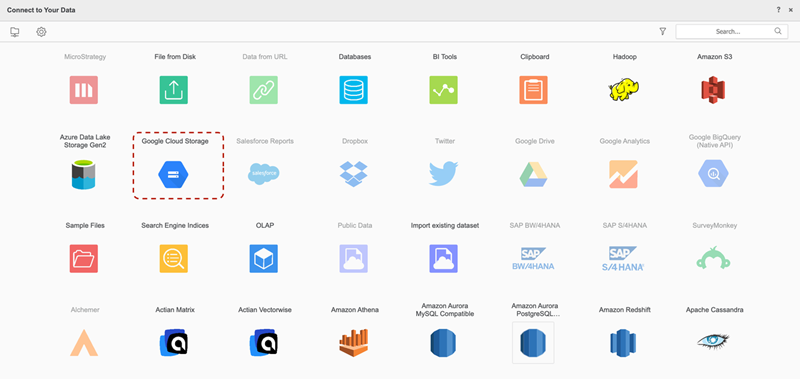
-
Accanto a Origini dati, fare clic su Nuova origine dati
 per aggiungere una nuova connessione.
per aggiungere una nuova connessione. 
-
Immettere le credenziali di connessione.
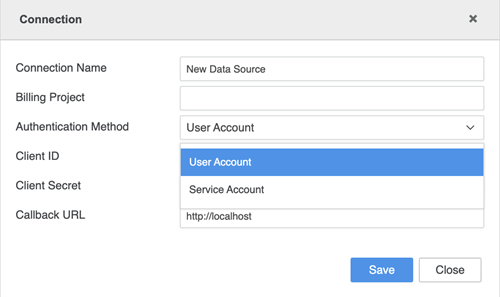
- Nome connessione: Un nome per la nuova connessione.
- ID progetto: L'ID progetto dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore.
- ID client: L'ID client dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore.
- E-mail client: L'indirizzo e-mail del client contenuto nel file JSON della chiave dell'account di servizio ottenuto dall'amministratore.
- Chiave privata ID: L'ID chiave privata dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore.
-
Chiave privata: La chiave privata dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore.
La chiave privata deve essere inclusa tra virgolette (ad es. "your_private_key").
-
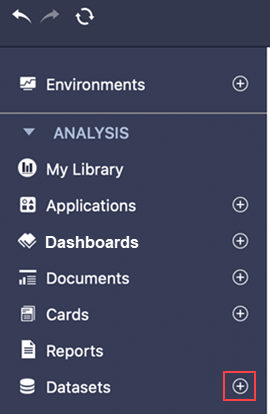
Nel riquadro di sinistra, accanto a Dataset, fare clic su Crea un nuovo dataset
. 
-
Trova e seleziona Google Cloud Storage Connettore oggetto cloud dall'elenco di origini dati.
-
Accanto a Origini dati, fare clic su Nuova origine dati
per aggiungere una nuova connessione.
-
Immettere le credenziali di connessione.
- Nome connessione: Un nome per la nuova connessione
- Progetto di fatturazione: L'ID progetto dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore
- Metodo di autenticazione: Il metodo di autenticazione che si desidera usare
- ID client: L'ID client dal file JSON della chiave dell'account di servizio ottenuto dall'amministratore
- Segreto client Il segreto del client contenuto nel file JSON della chiave dell'account di servizio ottenuto dall'amministratore
- URL callback: L'URL richiamato dopo l'accesso dell'utente
Importazione di dati
Dopo aver creato il connettore, è possibile importare i dati in MicroStrategy.
- Selezionare la connessione appena creata.
- Nell'elenco a discesa, selezionare il bucket ed esplorare le cartelle o i file.
-
Fare doppio clic sui file o trascinarli nel riquadro di destra.
Nel riquadro Anteprima è possibile visualizzare i dati di esempio e regolare il tipo di colonna.
- Pubblica il cubo in MicroStrategy con i dati selezionati.
Limitazioni
Tipi di file supportati
Sono supportati solo i seguenti tipi di file:
- .json
- .parquet
- .avro
- .orc
- .csv
- Formato delta
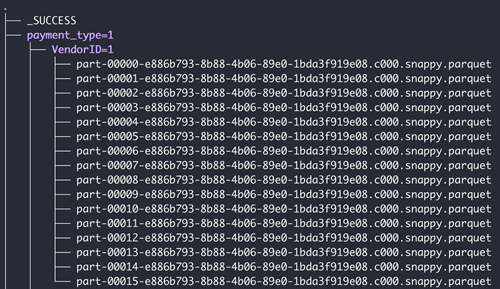
Selezionare Cartelle
Quando si seleziona l'intera cartella, la cartella deve soddisfare i seguenti requisiti:
- Tutti i file della cartella devono essere dello stesso tipo. Verrà visualizzata una finestra di dialogo in cui viene chiesto di scegliere il tipo di file
- Tutti i file condividono lo stesso schema
-
Se la cartella contiene sottocartelle, le sottocartelle dovrebbero essere in un formato partizionato valido. Quello che segue è un esempio di struttura di cartelle valida
Limiti Spark
- È possibile leggere solo i file JSON con ogni nuova riga come JSON completo
- Impossibile leggere i file parquet che contengono caratteri speciali (, ; { } \ = " .).
- I file parquet con tipi di dati di colonna come INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) non sono supportati
- Impossibile pubblicare le colonne di tipo binario nel cubo
- Impossibile importare i file ORC con nomi di campo preceduti da "_col" (ad es. _col0, _col1), in cui lo schema del file contiene almeno un campo struttura, matrice o mappa annidato
Funzioni
Le seguenti funzioni non sono supportate:
- Caricamento in corso MicroStrategy connessione dei file a Cloud Object Connector
- Data wrangling in Data Import
- Definizione dell'area geografica in Data Import
- Pianificazione avanzata per la pubblicazione del cubo di pianificazione
- Raggruppa le tabelle in Importazione dati