MicroStrategy ONE
Connetti ad Amazon S3
Amazon Simple Storage Service (Amazon S3) è un servizio di storage a oggetti che offre scalabilità, disponibilità dei dati, sicurezza e prestazioni leader del settore. MicroStrategy Cloud Object Connector consente di accedere ad Amazon S3 per sfogliare rapidamente cartelle e file e importarli MicroStrategy cubi.
Questa pagina esplora i seguenti argomenti:
Preparare parametri di connessione
Affinché il connettore oggetti cloud possa esplorare il file system di Amazon S3, è necessario un account Amazon Web Service creato con le autorizzazioni adeguate. IAM Le entità, quali utenti, gruppi e ruoli, iniziano senza autorizzazioni e devono essere concesse. Per maggiori dettagli sulla concessione delle autorizzazioni alle entità IAM, fare riferimento a Gestisci autorizzazioni IAM.
MicroStrategy consiglia di creare un utente IAM per Cloud Object Connector. Affinché un utente IAM possa accedere a un bucket e agli oggetti al suo interno, l'autorizzazione Consenti effetti deve essere concessa almeno per le due azioni seguenti:
- s3:GetObject
- s3:ListBucket
-
s3:ListAllMyBuckets
Dopo IAM Creazione dell'utente completata, chiedere a un IAM amministratore per l'ID chiave di accesso e la chiave di accesso segreta.
Creare un ruolo DB
Accedi a Amazon S3 Cloud Object Connector su MicroStrategy Web o Workstation.
- Web
- Workstation
- Scegliere Aggiungi dati > Nuovi dati.
-
Trovare e selezionare il Amazon S3 Connettore oggetto cloud dall'elenco di origini dati.
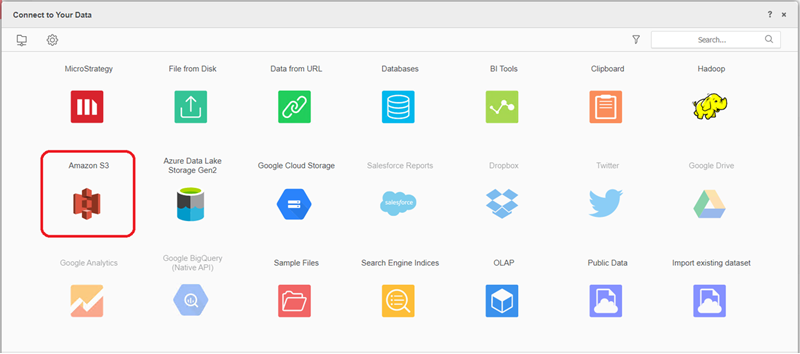
-
Accanto a Origini dati, fare clic su Nuova origine dati
 per aggiungere una nuova connessione.
per aggiungere una nuova connessione. 
-
Immettere le credenziali di connessione.
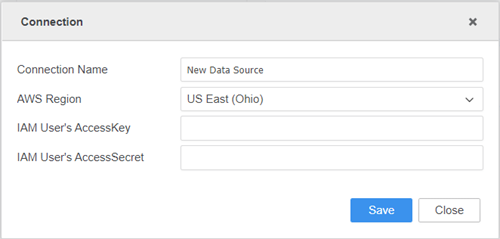
- Nome connessione: Un nome per la nuova connessione.
- AWS Regione: L'oggetto AWS esatto regione in cui si trova il bucket.
- IAM AccessKey dell'utente: L'ID chiave di accesso.
- IAM AccessSecret dell'utente: Chiave di accesso segreta.
-
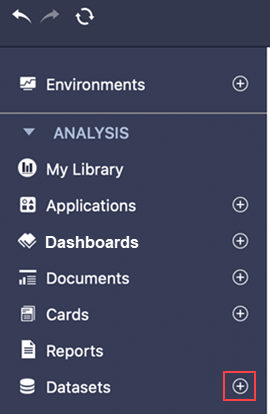
Nel riquadro di sinistra, accanto a Dataset, fare clic su Crea un nuovo dataset
. 
-
Trovare e selezionare il Amazon S3 Connettore oggetto cloud dall'elenco di origini dati.
-
Accanto a Origini dati, fare clic su Nuova origine dati
per aggiungere una nuova connessione.
-
Immettere le credenziali di connessione.
- Nome connessione: Un nome per la nuova connessione
- AWS Regione: L'oggetto AWS esatto regione in cui si trova il bucket
- IAM AccessKey dell'utente: L'ID chiave di accesso
- IAM AccessSecret dell'utente: Chiave di accesso segreta
Importazione di dati
Dopo aver creato il connettore, è possibile importare i dati in MicroStrategy.
- Selezionare la connessione appena creata.
- Nell'elenco a discesa, selezionare il bucket ed esplorare le cartelle o i file.
-
Fare doppio clic sui file o trascinarli nel riquadro di destra.
Nel riquadro Anteprima è possibile visualizzare i dati di esempio e regolare il tipo di colonna.
- Pubblica il cubo in MicroStrategy con i dati selezionati.
Limitazioni
Tipi di file supportati
Sono supportati solo i seguenti tipi di file:
- .json
- .parquet
- .avro
- .orc
- .csv
- Formato delta
Selezionare Cartelle
Quando si seleziona l'intera cartella, la cartella deve soddisfare i seguenti requisiti:
- Tutti i file della cartella devono essere dello stesso tipo. Verrà visualizzata una finestra di dialogo in cui viene chiesto di scegliere il tipo di file
- Tutti i file condividono lo stesso schema
-
Se la cartella contiene sottocartelle, le sottocartelle dovrebbero essere in un formato partizionato valido. Quello che segue è un esempio di struttura di cartelle valida
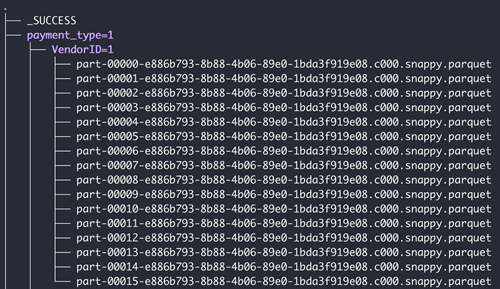
Limiti Spark
- È possibile leggere solo i file JSON con ogni nuova riga come JSON completo
- Impossibile leggere i file parquet che contengono caratteri speciali (, ; { } \ = " .).
- I file parquet con tipi di dati di colonna come INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) non sono supportati
- Impossibile pubblicare le colonne di tipo binario nel cubo
- Impossibile importare i file ORC con nomi di campo preceduti da "_col" (ad es. _col0, _col1), in cui lo schema del file contiene almeno un campo struttura, matrice o mappa annidato
Funzioni
Le seguenti funzioni non sono supportate:
- Caricamento in corso MicroStrategy connessione dei file a Cloud Object Connector
- Data wrangling in Data Import
- Definizione dell'area geografica in Data Import
- Pianificazione avanzata per la pubblicazione del cubo di pianificazione
- Raggruppa le tabelle in Importazione dati