Strategy One
Join Across Datasets
The Join Across Datasets VLDB property determines how values for metrics are calculated when unrelated attributes from different datasets of a dashboard are included with metrics. For example, consider a dashboard with two separate datasets that include the following data:
The datasets are displayed below as simple grid visualizations within a dashboard.

Notice that one dataset includes the Region attribute, however the other dataset only includes Category. The Region attribute is also not directly related to the Category attribute, but it is included with Category in one of the two datasets.
On this dashboard, you choose to create a new grid visualization with Region and Sales. These objects are not on the same dataset, so this requires combining the data from different datasets. By default, data is not joined for the unrelated attributes Category and Region, and the following data is displayed:
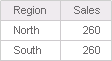
The data for Sales is displayed as $260 for both Regions, which is the total sales of all regions. In most scenarios, this sales data should instead reflect the data for each region. This can be achieved by allowing data to be joined for the unrelated attributes Category and Region.
Now the data for Sales displays $185 for North (a combination of the sales for Books and Electronics, which were both for the North region) and $85 for South (sales for Movies, which was for the South region).
The following settings define join behavior:
- Disallow joins based on unrelated common attributes: By default, data is not joined for unrelated attributes that are included on the same dataset. This option is to support backward compatibility.
- Allow joins based on unrelated common attributes: Data is joined for unrelated attributes that are included on the same dataset. This can allow metric data to consider unrelated attributes on the same dataset to logically combine the data, and thus provides results that are more accurate and intuitive in most cases.