MicroStrategy ONE
Se connecter à Google Cloud Storage
Google Cloud Storage est un service en ligne pour stocker et accéder aux données sur la plateforme Google Cloud. Le connecteur d'objets MicroStrategy Cloud permet d'accéder à Google Cloud Storage pour parcourir rapidement les dossiers et fichiers et les importer dans les Cubes MicroStrategy .
Découvrez les sujets suivants sur cette page :
- Préparer les paramètres de connexion
- Créer un rôle de base de données
- Importer des données
- Limitations
Préparer les paramètres de connexion
Pour que le connecteur Cloud Object puisse parcourir avec succès le système de fichiers Google Cloud Storage, vous avez besoin d'un compte de service créé avec les autorisations appropriées. Les combinaisons d'autorisations ne sont pas disponibles à partir d'un rôle de base dans Google Cloud. MicroStrategy recommande de créer un rôle personnalisé pour le connecteur Google Cloud.
Les autorisations suivantes doivent être ajoutées au rôle personnalisé :
- stockage.buckets.get
- stockage.buckets.list
- stockage.objets.get
- stockage.objets.list
Une fois le compte de service créé, veuillez demander la clé à votre administrateur. La clé se présente sous la forme d'un fichier JSON et sera nécessaire pour une utilisation ultérieure.
Créer un rôle de base de données
Accédez au connecteur d'objet Google Cloud Storage Cloud dans MicroStrategy Web ou Workstation.
- Web
- Workstation
- Choisissez Ajouter des données > Nouvelles données.
-
Recherchez et sélectionnez Stockage Google Cloud Connecteur Cloud Object à partir de la liste de sources de données.
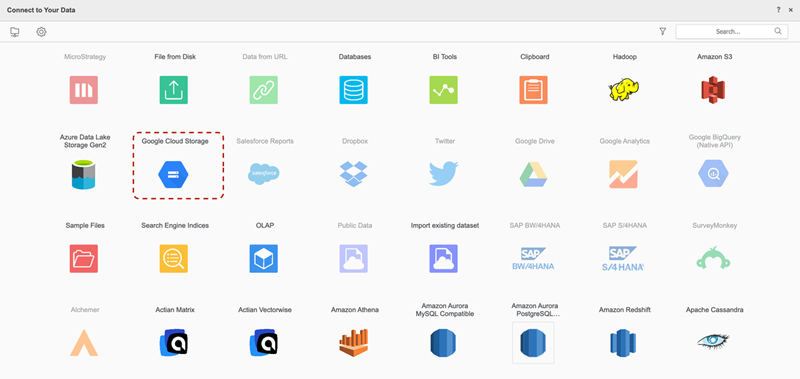
-
À côté de Sources de données, cliquez sur Nouvelle source de données
 pour ajouter une nouvelle connexion.
pour ajouter une nouvelle connexion. 
-
Saisissez vos informations d'identification de connexion.
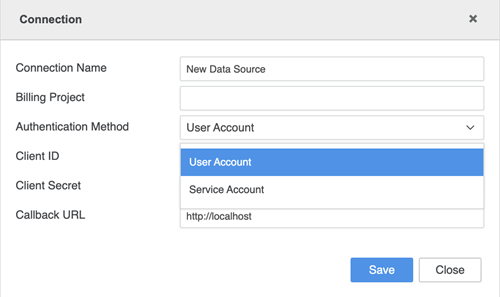
- Nom de connexion: Un nom pour la nouvelle connexion.
- ID du projet: L'ID du projet à partir du fichier JSON de clé du compte de service obtenu de votre administrateur.
- ID client: L'ID client du fichier JSON de clé du compte de service obtenu de votre administrateur.
- Adresse e-mail du client: L'e-mail client à partir du fichier JSON de clé du compte de service obtenu de votre administrateur.
- Clé privée ID: L'ID de clé privée du fichier JSON de clé du compte de service obtenu de votre administrateur.
-
Clé privée: La clé privée du fichier JSON de clé du compte de service obtenue de votre administrateur.
La clé privée doit se trouver entre guillemets doubles (par exemple, "your_private_key").
-
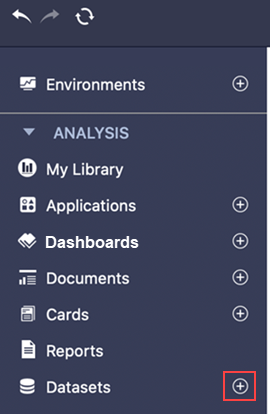
Dans le panneau gauche, à côté de Jeux de données, cliquez sur Créer un jeu de données
. 
-
Rechercher et sélectionner Stockage Google Cloud Connecteur Cloud Object à partir de la liste de sources de données.
-
À côté de Sources de données, cliquez sur Nouvelle source de données
pour ajouter une nouvelle connexion.
-
Saisissez vos informations d'identification de connexion.
- Nom de connexion: Un nom pour la nouvelle connexion
- Projet de facturation: L'ID de projet du fichier JSON de clé du compte de service obtenu de votre administrateur
- Méthode d'authentification: La méthode d'authentification que vous souhaitez utiliser
- ID client: L'ID client du fichier JSON de clé du compte de service obtenu de votre administrateur
- Secret client Le secret du client à partir du fichier JSON de clé du compte de service obtenu de votre administrateur
- URL de rappel: L'URL qui est invoquée après la connexion de l'utilisateur
Importer des données
Une fois que vous avez créé le connecteur, vous pouvez importer des données dans MicroStrategy.
- Sélectionnez la connexion récemment créée.
- Dans le menu déroulant, sélectionnez le compartiment et parcourez les dossiers ou fichiers.
-
Double-cliquez sur les fichiers ou faites-les glisser dans le volet droit.
Dans le volet Aperçu, vous pouvez voir les échantillons de données et ajuster le type de colonne.
- Publiez le Cube sur MicroStrategy avec les données sélectionnées.
Limitations
Types de fichiers pris en charge
Seuls les types de fichiers suivants sont pris en charge :
- .json
- .parquet
- .avro
- .orc
- .csv
- Format Delta
Sélectionner les dossiers
Lors de la sélection du dossier entier, le dossier doit répondre aux exigences suivantes :
- Tous les fichiers dans ce dossier doivent avoir les mêmes types de fichiers. Une boîte de dialogue vous invite à choisir le type de fichier
- Tous les fichiers partagent le même schéma
-
Si le dossier comporte des sous-réseaux, ces derniers doivent être dans un format de partition valide. Voici un exemple de structure de dossier valide
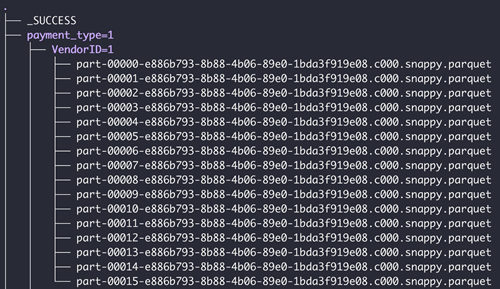
Limitations de Spark
- Seuls les fichiers JSON avec chaque nouvelle ligne comme JSON complet peuvent être lus
- Impossible de lire les fichiers Parquet qui contiennent des caractères spéciaux (, ; { } \ = " .)
- Les fichiers Parquet avec les types de données de colonne INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) ne sont pas pris en charge
- Les colonnes avec le type binaire ne peuvent pas être publiées dans le Cube
- Les fichiers ORC avec des noms de champs avec le préfixe « _col » (par exemple, _col0, _col1), où le schéma de fichier contient au moins une structure imbriquée, un tableau ou un champ de carte, ne peuvent pas être importés
Fonctionnalités
Les fonctionnalités suivantes ne sont pas prises en charge :
- Chargement des fichiers MicroStrategy en se connectant au connecteur Cloud Object
- Gestion des données dans l'importation des données
- Définition de la géographie dans l'importation des données
- Planification avancée pour la publication du Cube de planification
- Regrouper les tables dans l'importation des données