Strategy One
Google BigQuery Cost Optimization
Data Storage
After any data is loaded into a Google BigQuery table, the data is stored in active storage. If the table or partition of a table has not been edited for 90 days, the data status is marked as long-term storage and the price of the data stored in the table automatically drops by about 50%. To get the most out of long-term storage, be mindful of any actions that edit your table data, such as streaming, copying, or loading data, including any Data Manipulation Language (DML) or Data Definition Language (DDL) actions. This will bring back your data back to active storage and reset the 90-day timer. To avoid this, you can consider loading the new batch of data to a new table or a partition of a table, if it is appropriate for your use case.
Avoid duplicate copies of data using Google's federated data access model that allows you to query data directly from external data sources like Google Bigtable, Cloud Storage, Google Drive, and Cloud SQL.
Keep data only as long as it is needed. To help you delete expired data, you can leverage Google BigQuery's table expiration feature to expire tables you do not need.
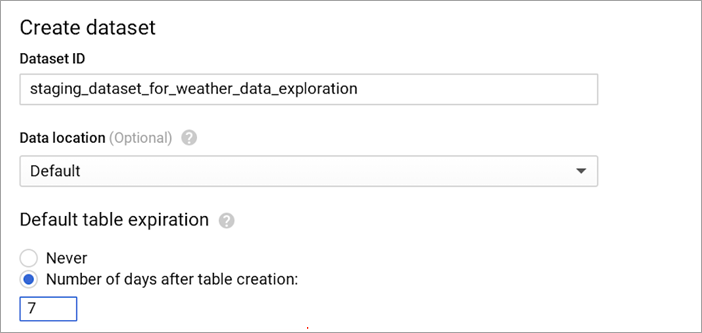

Recommendations for Strategy
When creating temporary tables in Strategy, the temporary tables are often not dropped due to a previous error. If you are not aware of this issue and do not drop the tables manually, the tables remain and you are charged for the storage. You should use the Google BigQuery's expiration feature to ensure temporary tables are expired at a specified time, in the case they are not dropped. For example:
CREATE TABLE `project_id.dataset_name.table_name` (
column[, ...]
)
OPTIONS(
expiration_timestamp = TIMESTAMP "2021-01-01 00:00:00 UTC"
);Data Loading
Unless you need your data for real-time processing and inserted in seconds rather than hours, avoid using streaming inserts into BigQuery, and use batch loading instead. Data streaming is a paid service while batch loading is free. Use streaming inserts only if the data in BigQuery is consumed immediately by a downstream consumer.
Recommendations for Strategy
Strategy should work with the JDBC or ODBC driver vendor to implement batch and streaming data loading into the driver for faster, more reliable, and cost efficient data import. Nowadays, both drivers insert data line by line, which is time inefficient, fails after reaching the table limit (1,500 operations per day), and is more costly in comparison to free batch data loading.
Data Querying
Google BigQuery can provide incredible performance because it stores data as a columnar data structure. This means SELECT * is the most expensive way to query data. This is because it performs a full query scan across every column present in the tables, including the ones you may not need. As shown in the following screenshot, you can reduce eight times the data processed and therefore, your bill.
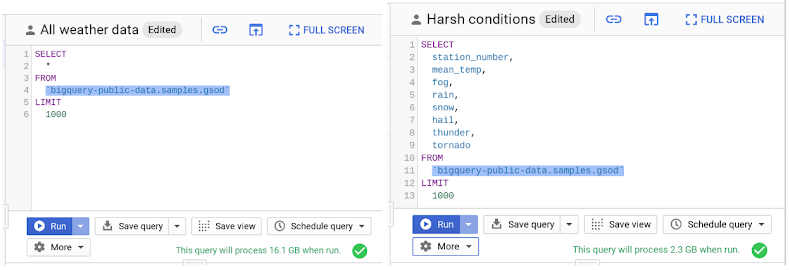
Applying the LIMIT clause to your query doesn't have an effect on cost.
You are charged for bytes processed in the first stage of query execution. See the Google Cloud documentation for more information. You should avoid creating a complex multistage query just to optimize bytes processed in the intermediate stages, since there are no cost implications anyway. Although, you may achieve performance gains.
Partitioning your tables, whenever possible, can help reduce the cost of processing queries, as well as improve performance. See the Google Cloud documentation for more information. Today, you can partition a table based on ingestion time, date, or any timestamp column.
Recommendations for Strategy
To optimize cost and speed of data querying, do not always use SELECT * in data preparation.