MicroStrategy ONE
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 ( ADLS2 ) ist eine Data Lake-Plattform, die vollständig in Azure Blob integriert ist Speicher. Der MicroStrategy Cloud Object Connector bietet Zugriff auf ADLS2, um Ordner und Dateien schnell zu durchsuchen und in MicroStrategy Cubes zu importieren.
Erkunden Sie die folgenden Themen auf dieser Seite:
- Verbindungsparameter vorbereiten
- Erstellen Sie eine Datenbankrolle
- Daten importieren
- Einschränkungen
Verbindungsparameter vorbereiten
Damit der Cloud-Objekt-Konnektor das ADLS2-Dateisystem erfolgreich durchsuchen kann, benötigen Sie ein Speicherkonto mit einem hierarchischen Namespace. Weitere Informationen zum Erstellen eines Speicherkontos finden Sie im Microsoft-Dokumentation.
Nachdem das Speicherkonto erstellt wurde, werden zwei Zugriffsschlüssel gewährt. Beide können zum Erstellen einer Verbindung verwendet werden.
Erstellen Sie eine Datenbankrolle
Greifen Sie in MicroStrategy Web oder Workstation auf den Azure Data Lake Storage Gen2 Cloud Object Connector zu.
- Web
- Workstation
- Wählen Sie Daten hinzufügen > Neue Daten.
-
Suchen und auswählen Azure Data Lake Storage Gen2 Cloud-Objekt-Konnektor aus der Liste der Datenquellen.
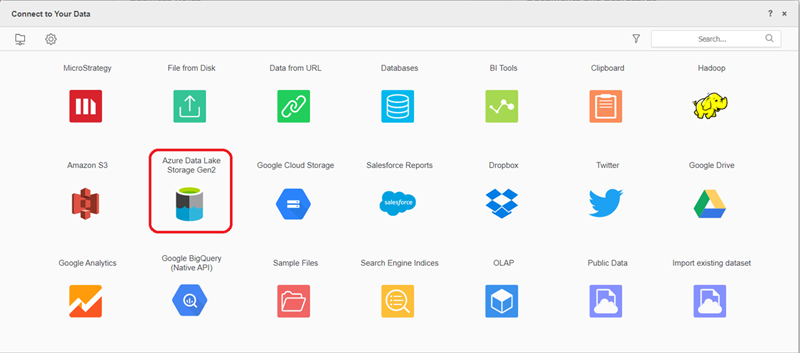
-
Klicken Sie neben Datenquellen auf Neue Datenquelle
 , um eine neue Verbindung hinzuzufügen.
, um eine neue Verbindung hinzuzufügen. 
-
Geben Sie Ihre Verbindungsanmeldeinformationen ein.
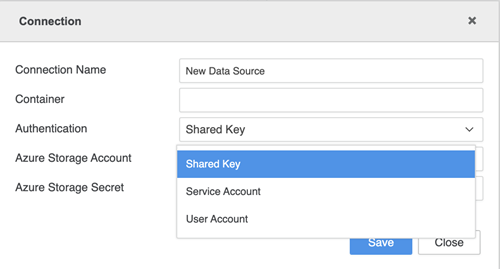
- Verbindungsname: Ein Name für die neue Verbindung
- Container: Der Container, auf den Sie zugreifen möchten
- Authentifizierung: Die Authentifizierungsmethode, die Sie verwenden möchten
- Verzeichnis-ID (Tenant).: Die ID, die jedem Abonnement zugeordnet ist
- Azure Storage-Konto: Das Speicherkonto, das Ihre Azure Storage-Datenobjekte enthält
- Geheimer Azure Storage-Schlüssel: Der mit Azure Storage verknüpfte geheime Schlüssel
-
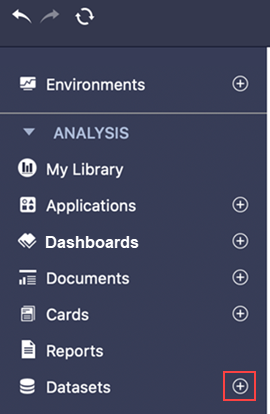
Klicken Sie im Abschnitt links neben Datensätzen auf Neuen Datensatz erstellen
. 
-
Suchen und auswählen Azure Data Lake Storage Gen2 Cloud-Objekt-Konnektor aus der Liste der Datenquellen.
-
Klicken Sie neben Datenquellen auf Neue Datenquelle
, um eine neue Verbindung hinzuzufügen.
-
Geben Sie Ihre Verbindungsanmeldeinformationen ein.
- Verbindungsname: Ein Name für die neue Verbindung
- Verzeichnis-ID (Tenant).: Die ID, die jedem Abonnement zugeordnet ist
- Azure Storage-Konto: Das Speicherkonto
- Container: Der Container, auf den Sie zugreifen möchten
- Client-ID: Die verwendete Client-ID
- Geheimer Clientschlüssel: Der geheime Clientschlüssel, der mit der Client-ID verknüpft ist
Daten importieren
Nachdem Sie den Konnektor erfolgreich erstellt haben, können Sie Daten in MicroStrategy importieren.
- Wählen Sie die neu erstellte Verbindung aus.
- Durchsuchen Sie die Ordner oder Dateien im spezifischen Container,
-
Doppelklicken Sie auf Dateien oder ziehen Sie sie in den rechten Bereich.
Im Vorschaubereich können Sie die Beispieldaten sehen und den Spaltentyp anpassen.
- Veröffentlichen the cube to MicroStrategy with your selected data.
Einschränkungen
Unterstützte Dateitypen
Nur die folgenden Dateitypen werden unterstützt:
- .json
- .parlet
- .vro
- .orc
- CSV
- Dreieck-Format
Wählen Sie Ordner aus
Bei Auswahl des gesamten Ordners muss der Ordner die folgenden Anforderungen erfüllen:
- Alle Dateien im Ordner müssen den gleichen Dateityp haben. In einem Dialogfeld werden Sie aufgefordert, den Dateityp auszuwählen
- Alle Dateien verwenden das gleiche Schema
-
Wenn der Ordner Unterordner hat, sollten die Unterordner in einem gültigen partitionierten Format vorliegen. Unten finden Sie ein Beispiel für eine gültige Ordnerstruktur
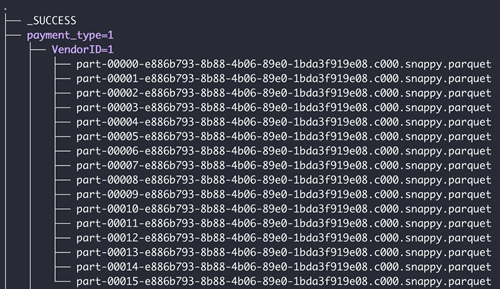
Spark-Einschränkungen
- Nur JSON-Dateien, bei denen jede neue Zeile eine vollständige JSON-Datei ist, können gelesen werden
- Parcat-Dateien, die Sonderzeichen (, ; { } \ = " .) enthalten, können nicht gelesen werden
- Parcat-Dateien mit Spaltendatentypen wie INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(Time_Millis) werden nicht unterstützt
- Spalten des Binärtyps können nicht im Cube veröffentlicht werden
- ORC-Dateien mit Feldnamen mit dem Präfix „_col“ (z. B. _col0, _col1) können nicht importiert werden, wenn das Dateischema mindestens ein geschachteltes Struktur-, Matrix- oder Kartenfeld enthält
Funktionen
Die folgenden Funktionen werden nicht unterstützt:
- Hochladen von MicroStrategy -Dateien, die eine Verbindung mit dem Cloud Object Connector herstellen
- Datenumbau beim Datenimport
- Definieren der Geographie im Datenimport
- Erweiterte Planung für Schedule Cube Veröffentlichung
- Gruppieren Sie Tabellen im Datenimport