Strategy ONE
データセットを エージェントで有効にするs
で始まるStrategy One(2025 年 3 月)、ボットの機能が強化され、応答とボット作成プロセスが改善されました。機能拡張の詳細については、エージェント: カスタマイズされたスタンドアロンボット。
-
続行できます作成ボットだけでなくを編集と使用古いバージョンで作成されたボット。概要については、Auto Bots: Customized Stand-Alone Bots (2025 年 3 月以前)
-
新しいボットを有効化するには、に問い合わせてください。Strategyサポート。新しいボットの概要については、エージェント: カスタマイズされたスタンドアロンボット。新しいボットの作成手順については、エージェントを作成する。
Strategy One(2025年12月)から開始、Strategy LibraryとWorkstationの両方を使用して、非構造化データファイルをデータソースとして追加できます。手順については、Libraryで非構造化データを追加を参照してください。
Strategy One (2025年11月) から開始、Strategy Library と Workstation の両方を使用して、AI 用の構造化データセットを有効にすることができます。手順については、Library でデータセットを有効にするを参照してください。
Strategy One (2025年3月) から、データセットを使用してエージェントを作成する前に、AI 用に有効にする必要があります。この前処理により、自然言語クエリ、予測分析、高度なインサイトなどの AI 機能に関連するデータのシームレスな統合と処理が保証されます。キューブは、キューブ自体と各列の自動生成された説明で強化され、 エージェントに必要なコンテキストを提供します。データセットを AI 用に有効にすることで、データが適切に整理され、詳細化され、 エージェントの質問に答える準備が整います。
-
Strategy One(2025年10月)から開始、プレビュー機能として、Strategy One(2025年12月)から標準機能として、エージェントのデータソースとしてデータモデルを追加できます。正しいセットアップがあることを確認するには、データモデルからエージェントを作成を参照してください。
-
Strategy One (2025年6月) から、 エージェントのデータ ソースとして非構造化データ ファイルを追加できます。非構造化データには、PDF、Microsoft Word、HTML、マークダウン、およびテキスト ファイルが含まれます。
-
Strategy One (2025年8月) から、カスタム タグを定義し、非構造化データに割り当てることができます。タグは説明的なラベルとして機能し、検索結果を改善します。手順については、非構造化データにタグを追加するを参照してください。
エージェント に関連するデータセットのみを有効にするため、すべてのデータセットを処理することによるシステムの過負荷を回避できます。これにより、ユーザーが関連性があり、安全で、信頼できるソースからの AI 対応データセットで エージェントを構築することも保証されます。
前提条件
-
キューブの管理および非構造化データの作成と構成権限が必要です。
-
Cognitive Search が実行されている必要があります。これにより、Workstation は以下にリストされた要件を満たすデータセットを識別できます。
-
データセットは、MTDI キューブ、In-memory OLAP キューブ、またはプロンプトのないサブセット レポートである必要があります。MTDI キューブには、単一のテーブルまたは複数のテーブルを含むことができます。 Strategy One (2025年6月) から、データセットは非構造化にすることもできます。
-
サブセット レポートは単一のキューブに基づいています。そのキューブは MTDI キューブまたは OLAP キューブである必要があります。
-
-
データセットを有効にする前に、公開されている必要があります。
次の手順のいずれかを選択してください:
-
-
データ モデルを有効にする場合も同じ手順に従います。
-
-
-
データ モデルを有効にする場合も同じ手順に従います。
-
Library でデータセットを有効にする
Strategy One (2025年11月) から開始、データ モデルを含む構造化データセットを Strategy Library を使用して AI 用に有効にすることができます。
- Library で、管理者権限で環境に接続します。
- Library アイコン
 をクリックして、サイドバーを表示します。
をクリックして、サイドバーを表示します。 - サイドバーで、データ
 をクリックします。
をクリックします。データ セクションでは、以下に示すように、データ インポート キューブ、インテリジェント キューブ、ライブ インテリジェント キューブなど、さまざまなタイプのデータセットを簡単にフィルター処理できます:
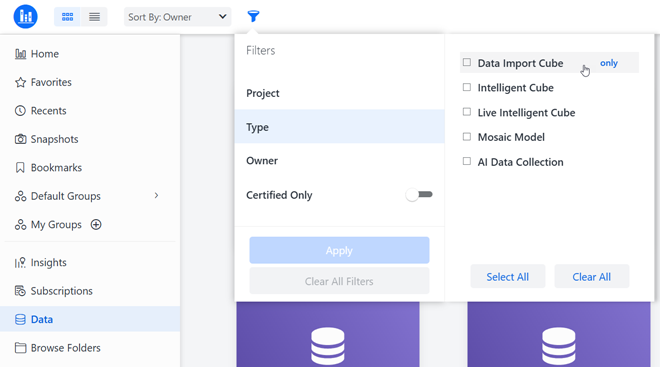
- フォルダーの参照または検索ページからデータセットとレポートを有効にすることもできます。
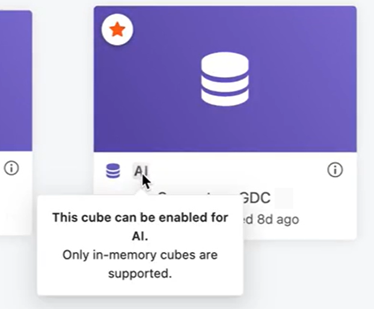
- AI で使用可能
 アイコンを表示するデータセットを右クリックし、AI で有効にする を選択します。
アイコンを表示するデータセットを右クリックし、AI で有効にする を選択します。前処理中、読み込みアイコン
 が表示されます。システムが情報を取り込み、質問に答えるために使用できるように準備します。プロセスが完了すると、データセットに以下に示すように AI で有効 アイコン
が表示されます。システムが情報を取り込み、質問に答えるために使用できるように準備します。プロセスが完了すると、データセットに以下に示すように AI で有効 アイコン  が表示されます:
が表示されます:
-
データセットを有効にできなかった場合、データセットにエラー アイコン
 が表示されます。エラー アイコン にマウスを合わせると、失敗に関するメッセージが表示されます。
が表示されます。エラー アイコン にマウスを合わせると、失敗に関するメッセージが表示されます。 -
エージェントに使用する必要がなくなった場合、データセットの AI を無効にできます。データセットを右クリックし、AI で無効にする を選択します。
Libraryで非構造化データを追加
Strategy One(2025年12月)から開始、Strategy LibraryとWorkstationの両方を使用して、非構造化データファイルをデータソースとして追加できます。新しい非構造化データは次の場合に追加します:
-
AIデータセットコレクションを編集
エージェントの作成中に非構造化データを追加
エージェントを作成するための前提条件を参照してください。
-
Libraryで、管理者権限で環境に接続します。
- 新規作成
 をクリックし、エージェントを選択します。
をクリックし、エージェントを選択します。 - 複数のプロジェクトにアクセスできる場合は、エージェントの作成先ドロップダウン リストから、エージェントを作成するプロジェクトを選択します。
- 非構造化データをクリックします。
- アップロード
 をクリックします。
をクリックします。
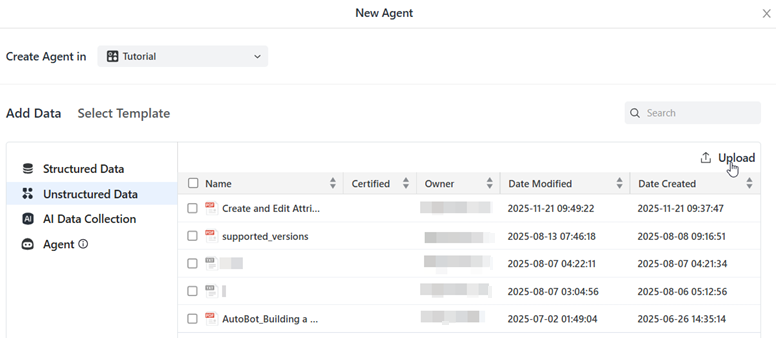
- ファイルをドラッグアンドドロップするか、ファイルを参照をクリックしてファイルを見つけて選択します。複数のファイルを選択できます。
- 追加をクリックします。
- ファイルを保存するフォルダーに移動し、保存をクリックします。
前処理中、以下に示すように、New Agentウィンドウでファイル名の横にローディングアイコン
が表示されます。システムが情報を取り込み、質問に答えるために使用できるように準備します。プロセスが完了すると、ファイルはそのコンテンツタイプに基づくアイコンを表示します。
- データセットおよびエージェントに含めるその他のデータセットを選択します。
- このステップから開始して、エージェントの作成を続けます。
Workstation でデータセットを有効にする
データ モデルを有効にする場合も同じ手順に従います。
- Workstation ウィンドウを開きます。
- 管理者権限で環境に接続します。
- ナビゲーション ペインで、データセット をクリックします。
- データセット タブを選択します。
- データセットを右クリックし、AI で有効にする を選択します。
前処理中、読み込みアイコン
が表示されます。システムが情報を取り込み、質問に答えるために使用できるように準備します。プロセスが完了すると、データセットに以下に示すように AI で有効 アイコン が表示されます: -
データセットを有効にできなかった場合、データセットにエラー アイコン
が表示されます。エラー アイコン
にマウスを合わせると、失敗に関するメッセージが表示されます。 -
エージェントに使用する必要がなくなった場合、データセットの AI を無効にできます。データセットを右クリックし、AI で無効にする を選択します。
Workstationで非構造化データを追加
- Workstation ウィンドウを開きます。
- 管理者権限で環境に接続します。
- ナビゲーション ペインで、データセット をクリックします。
- 非構造化データ タブを選択します。
- ペインの上部にある 非構造化データを追加 をクリックします。
- データセットを追加する プロジェクト を選択します。
- ファイルをドラッグ アンド ドロップするか、ファイルを参照 をクリックしてファイルを見つけて選択します。
- 追加 をクリックします。
前処理中、読み込みアイコン
が表示されます。システムが情報を取り込み、質問に答えるために使用できるように準備します。プロセスが完了すると、ファイルに緑色のチェック マーク  が表示されます。
が表示されます。
非構造化データにタグを追加する
非構造化データ ファイルをプロジェクトに追加した後、カスタム タグを定義してファイルに割り当てます。タグは、ソーシャル メディアのハッシュタグに似た説明的なラベルとして機能し、関連する属性やテーマに基づいてデータを識別、分類、およびグループ化するのに役立ちます。これにより検索結果が改善され、 エージェントが関連アイテムをより簡単に見つけ、大きな非構造化データ コレクション内でターゲット クエリを実行できるようになります。
Strategy Oneから開始、LibraryとWorkstationの両方を使用してタグを追加できます。
Libraryでタグを追加
-
Libraryで、管理者権限で環境に接続します。
-
非構造化データファイルの情報アイコン
 をクリックします。
をクリックします。 -
情報ウィンドウで、タグを追加をクリックします。
- キーを入力し、次にそのキーの少なくとも1つの値を入力します。複数の値はコンマで区切ります。
キーは、国などのコンテキストとグループ化を提供するラベルです。値は、そのキーの特定の要素です。国キーの場合、次の値を追加できます:アフガニスタン、アルバニア、アルジェリア、アンドラ、アンゴラなど。
- 必要に応じてタグを追加します。
- キーまたは値を編集するには、それをクリックして変更を加えます。
- 保存をクリックします。
- Xを閉じて情報ウィンドウを閉じます。
Workstationでタグを追加
- Workstation ウィンドウを開きます。
- 管理者権限で環境に接続します。
- ナビゲーション ペインで、データセット をクリックします。
- 非構造化データ タブを選択します。
- ファイルを右クリックし、プロパティ を選択します。
- 左側のナビゲーション バーで、タグ をクリックします。
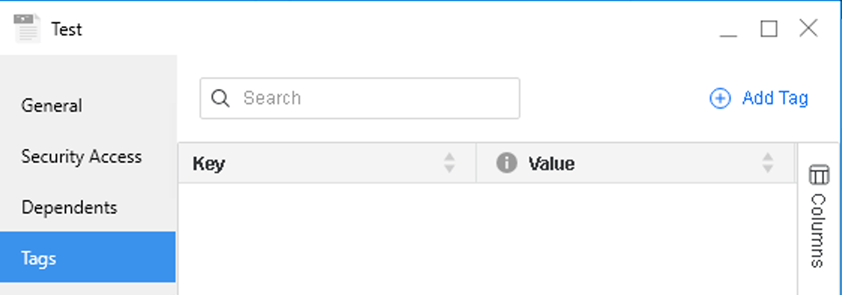
- タグを追加 をクリックします。
- キー を入力してから、そのキーに対して少なくとも 1 つの 値 を入力します。複数の値はコンマで区切ります。
キーは、国などのコンテキストとグループ化を提供するラベルです。値は、そのキーの特定の要素です。国キーの場合、次の値を追加できます:アフガニスタン、アルバニア、アルジェリア、アンドラ、アンゴラなど。
- 必要に応じてタグを追加します。
- キーまたは値を編集するには、それをクリックして変更を加えます。
- OK をクリックしてタグを保存し、Workstation に戻ります。
Libraryで非構造化データを管理
Strategy One(2025年12月)から開始、Libraryを使用して非構造化データファイルを管理できます。次のことができます:
-
サイドバーのデータおよびフォルダーの参照コンポーネントでLibrary Webの非構造化データを表示します。
-
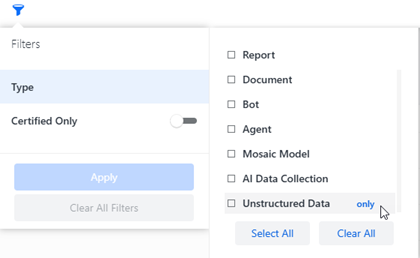
非構造化データをフィルタリングします。
-
メールを除く非構造化データをプレビューするには、ファイルを右クリックしてプレビューを選択します。プレビューは別のブラウザータブに表示されます。
-
名前の変更、削除、置換、情報の表示、移動、ダウンロード、認証、アクセスの管理など、他のオブジェクトと同様に非構造化データファイルを管理します。
-
非構造化ファイルのタグを追加します。手順については、非構造化データにタグを追加するを参照してください。
-
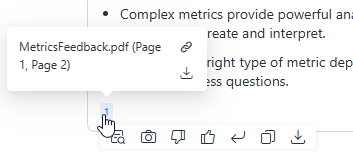
非構造化データファイルがエージェントの応答で参照として表示されるかどうかを決定します。以下の例では、PDFファイルが質問に答えるために使用され、参照として表示されます。ファイルが参照として使用されていない場合、注釈は表示されません。
 手順については、ここをクリックしてください。
手順については、ここをクリックしてください。-
Libraryで、管理者権限で環境に接続します。
-
非構造化データファイルの情報アイコン
をクリックします。 -
情報ウィンドウで、参照として使用しないを選択します。
- Xを閉じて情報ウィンドウを閉じます。
-