Strategy One
Google Cloud Storage に接続
Google Cloud Storage は、Google Cloud Platform にデータを保存し、アクセスするためのオンライン サービスです。MicroStrategy Cloud Object コネクタは、Google Cloud Storage にアクセスし、フォルダーとファイルを素早く参照してインポートすることができます。Strategyキューブ。
このページでは以下のトピックについて説明します。
接続パラメーターを準備
Cloud Object コネクターで Google Cloud Storage ファイル システムを正常に参照できるようにするには、適切な権限で作成されたサービス アカウントが必要です。権限の組み合わせは、Google クラウドの基本ロールからは利用できません。Strategyは、Google Cloud コネクター用のカスタム ロールを作成することを推奨します。
以下の権限をカスタム ロールに追加する必要があります。
- storage.buckets.get
- storage.buckets.list
- storage.objects.get
- storage.objects.list
サービス アカウントが正常に作成されたら、管理者にキーを要求します。キーは JSON ファイル形式で、今後使用する際に必要となります。
DBRoleを作成
で Google Cloud Storage Cloud Object コネクタにアクセスStrategy Web または Workstation。
- Web
- Workstation
- [データを追加] > [新規データ] を選択します。
-
データ ソース リストから Google Cloud Storage Cloud Object コネクターを検索して選択します。
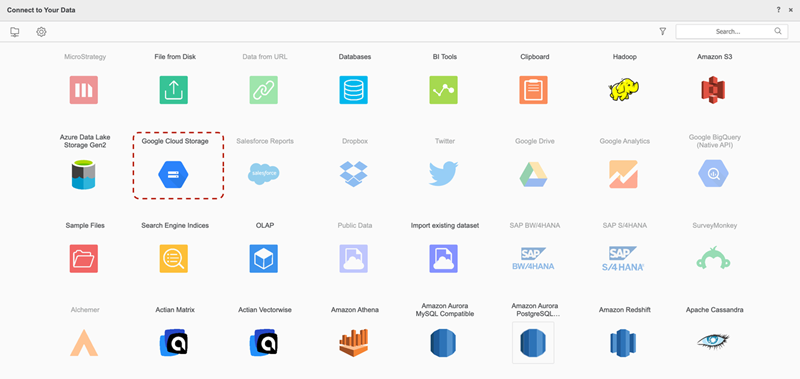
-
[データ ソース] の横にある をクリックします 新しいデータ ソース
 新しい接続を追加します
新しい接続を追加します 
-
接続の資格情報を入力します。
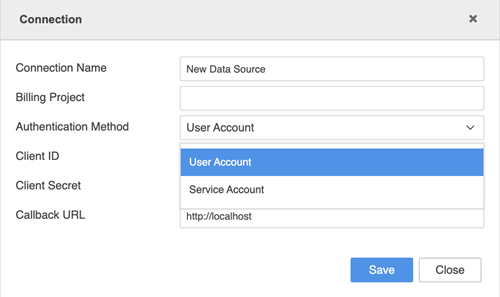
- [接続名]:新しい接続の名前。
- [プロジェクト ID]:管理者から取得したサービス アカウント キー JSON ファイルに記載されているプロジェクト ID。
- [クライアント ID]:管理者から取得したサービス アカウント キー JSON ファイルに記載されているクライアント ID。
- [クライアント メール]:管理者から取得したサービス アカウント キー JSON ファイルに記載されているクライアント メール。
- 秘密キー ID :管理者から取得したサービス アカウント キー JSON ファイルに記載されている秘密キー ID。
-
[秘密キー]:管理者から取得したサービス アカウント キー JSON ファイルに記載されている秘密キー。
秘密キーは、二重引用符で囲まれている必要があります (例: "your_private_key")。
-
左パネルで、データセットの隣の [新規データセットの作成]
をクリックします。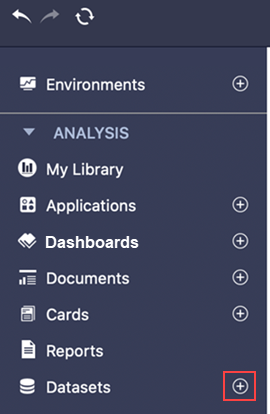
-
データ ソース リストから Google Cloud Storage Cloud Object コネクターを検索して選択します。
-
[データ ソース] の横にある をクリックします 新しいデータ ソース
新しい接続を追加します
-
接続の資格情報を入力します。
- [接続名]:新しい接続の名前
- [Billing Project]:管理者から取得したサービス アカウント キー JSON ファイルに記載されているプロジェクト ID
- [認証方法]:使用したい認証方法
- [クライアント ID]:管理者から取得したサービス アカウント キー JSON ファイルに記載されているクライアント ID
- [クライアント シークレット]: 管理者から取得したサービス アカウント キー JSON ファイルに記載されているクライアントのシークレット
- [コールバック URL]:ユーザー ログインの後で呼び出される URL
データのインポート
コネクターを作成すると、データをStrategy。
- 新たに作成した接続を選択します。
- ドロップダウンで、バケットを選択し、フォルダーまたはファイルを参照します。
-
ファイルをダブルクリックするか、右ペインにドラッグします。
[プレビュー] ペインで、サンプル データを表示し、列タイプを調整できます。
- にキューブを公開Strategy選択したデータが現れます
制限
サポートされるファイル タイプ
以下のファイル タイプのみがサポートされます。
- .json
- .parquet
- .avro
- .orc
- .csv
- デルタ形式
フォルダーの選択
フォルダー全体を選択する場合、以下の要件を満たす必要があります。
- フォルダーの下にある全ファイルのファイル タイプが同じでなければなりません。ファイル タイプを選択するダイアログが表示されます。
- 全ファイルが同じスキーマを共有する必要があります。
-
フォルダーにサブフォルダーがある場合、サブフォルダーは有効なパーティション形式である必要があります。有効なフォルダー構造の例を示します。
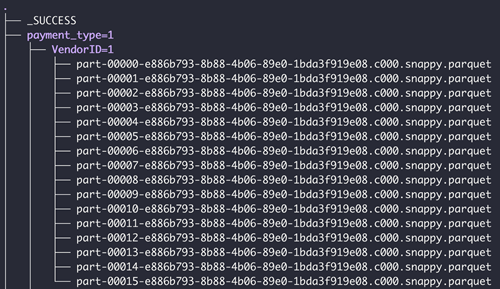
Spark の制限
- 各改行が完全な JSON である JSON ファイルのみを読み込むことができます。
- 特殊文字 (, ; { } \ = " .) を含む Parquet ファイルは読み込めません。
- 列データ タイプが INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) の Parquet ファイルはサポートされていません。
- バイナリー タイプの列はキューブで公開できません。
- フィールド名の先頭に「_col」を持つ ORC ファイル (例: _col0、_col1) で、ファイル スキーマに少なくとも 1 つの入れ子構造、配列、マップ フィールドが含まれる場合はインポートできません。
機能
次の機能はサポートされていません。
- アップロード中Strategyファイルを Cloud Object コネクタに接続
- データ インポートでのデータ ラングリング
- データ インポートでの地理の定義
- キューブ公開スケジュールの高度なスケジュール
- データ インポートでのグループ テーブル