MicroStrategy ONE
Conectar ao Armazenamento do Goocle Cloud
O Google Cloud Storage é um serviço online para armazenar e acessar dados no Google Cloud Platform. O MicroStrategy Cloud Object Connector fornece acesso ao Google Cloud Storage para navegar rapidamente por pastas e arquivos e importá-los para os cubos MicroStrategy .
Explore os seguintes tópicos nesta página:
Preparar parâmetros de conexão
Para que o Cloud Object Connector navegue com sucesso no sistema de arquivos do Google Cloud Storage, você precisa de uma conta de serviço criada com as permissões apropriadas. Combinações de permissão não estão disponíveis a partir de uma função básica no Google Cloud. A MicroStrategy recomenda a criação de uma função personalizada para o conector do Google Cloud.
As seguintes permissões devem ser adicionadas à função personalizada:
- armazenamento.buckets.get
- armazenamento.buckets.list
- armazenamento.objetos.get
- storage.objects.list
Depois que a conta de serviço for criada com êxito, solicite a chave ao administrador. A chave está no formato de um arquivo JSON e será necessária para uso futuro.
Criar uma DBRole
Acesse o conector de objeto em nuvem do Google Cloud Storage no MicroStrategy Web ou Workstation.
- Web
- Workstation
- Selecione Adicionar Dados > Novos Dados.
-
Encontre e selecione o Google Cloud Storage Conector de objeto em nuvem da lista de fontes de dados.
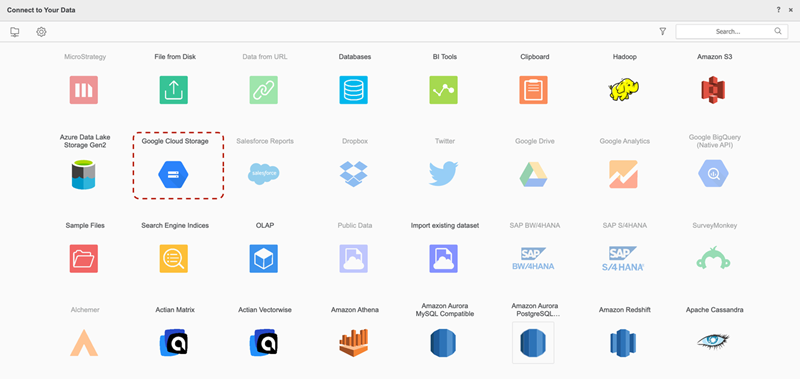
-
Ao lado de Fontes de dados, clique em Nova fonte de dados
 para adicionar uma nova conexão.
para adicionar uma nova conexão. 
-
Insira suas credenciais de conexão.
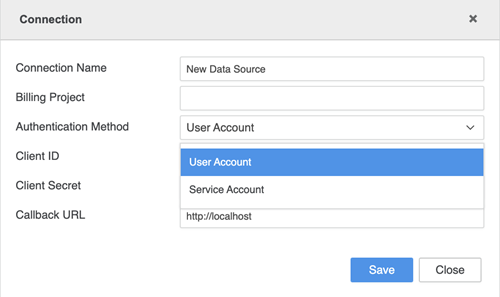
- Nome da conexão: Um nome para a nova conexão.
- Código do projeto: O código do projeto do arquivo JSON da chave da conta de serviço obtido do seu administrador.
- ID de cliente: O ID de cliente do arquivo JSON da chave da conta de serviço obtido do seu administrador.
- E-mail de cliente: O e-mail de cliente do arquivo JSON da chave da conta de serviço obtido do seu administrador.
- Chave privada Código: O ID de chave privada do arquivo JSON da chave da conta de serviço obtido do seu administrador.
-
Chave privada: A chave privada do arquivo JSON da chave da conta de serviço obtida do seu administrador.
A chave privada deve estar entre aspas duplas (por exemplo, "your_private_key").
-
No painel esquerdo, ao lado de Conjuntos de dados, clique em Criar um novo conjunto de dados
de .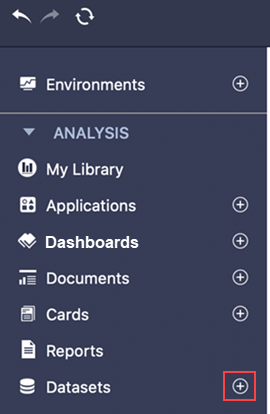
-
Localizar e selecionar Google Cloud Storage Conector de objeto em nuvem da lista de fontes de dados.
-
Ao lado de Fontes de dados, clique em Nova fonte de dados
para adicionar uma nova conexão.
-
Insira suas credenciais de conexão.
- Nome da conexão: Um nome para a nova conexão
- Projeto de faturamento: O código do projeto do arquivo JSON da chave da conta de serviço obtido com o seu administrador
- Método de autenticação: O método de autenticação que você deseja usar
- ID de cliente: O ID do cliente do arquivo JSON da chave da conta de serviço obtido com o seu administrador
- Segredo do cliente O segredo do cliente do arquivo JSON da chave da conta de serviço obtido junto ao seu administrador
- URL de retorno: A URL que é invocada após o login do usuário
Importar dados
Depois de criar o conector com êxito, você poderá importar dados para o MicroStrategy.
- Selecione a conexão recém-criada.
- Na lista suspensa, selecione o bucket e navegue pelas pastas ou arquivos.
-
Clique duas vezes nos arquivos ou arraste-os para o painel direito.
No painel de Visualização, você pode ver os dados de amostra e ajustar o tipo de coluna.
- Publique o cubo no MicroStrategy com os dados selecionados.
Limitações
Tipos de arquivo compatíveis
Somente os seguintes tipos de arquivo são compatíveis:
- .json
- .parquet
- .avro
- .orc
- .csv
- Formato delta
Selecionar pastas
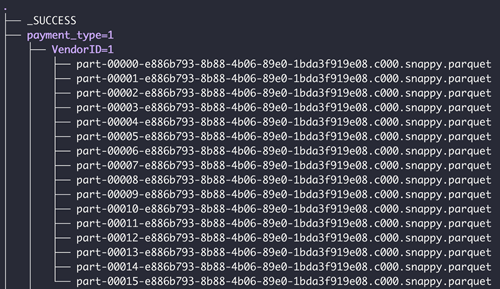
Ao selecionar a pasta inteira, a pasta deve atender aos seguintes requisitos:
- Todos os arquivos na pasta precisam ter os mesmos tipos de arquivo. Uma caixa de diálogo solicitará que você escolha o tipo de arquivo
- Todos os arquivos compartilham o mesmo esquema
-
Se a pasta tiver subpastas, as subpastas deverão estar em um formato particionado válido. Veja a seguir um exemplo de uma estrutura de pastas válida
Limitações do Spark
- Somente arquivos JSON com cada nova linha como um JSON completo podem ser lidos
- Arquivos Parquet que contêm caracteres especiais (, ; { } \ = " .) não podem ser lidos
- Arquivos Parquet com tipos de dados de coluna como INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) não são compatíveis
- Colunas com o tipo binário não podem ser publicadas no cubo
- Arquivos ORC com nomes de campo prefixados com "_col" (por exemplo, _col0, _col1), onde o esquema de arquivo contém pelo menos uma estrutura aninhada, matriz ou campo de mapa, não podem ser importados
Recursos
Os seguintes recursos não são compatíveis:
- Carregamento de arquivos da MicroStrategy conectando-se ao Cloud Object Connector
- Wrangling de dados na importação de dados
- Definição de geografia na importação de dados
- Programação avançada para Programar publicação de cubo
- Agrupar tabelas na importação de dados