Strategy ONE
配置高吞吐量或高级架构
本主题介绍如何使用 Kafka 节点(遥测服务器)集群配置高吞吐量架构。一个遥测存储(平台分析)只能使用来自单个 Kafka 节点或单个 Kakfa 集群的数据。
所有 Kafka 节点都应该在集群中,不支持多个 Kafka 集群。
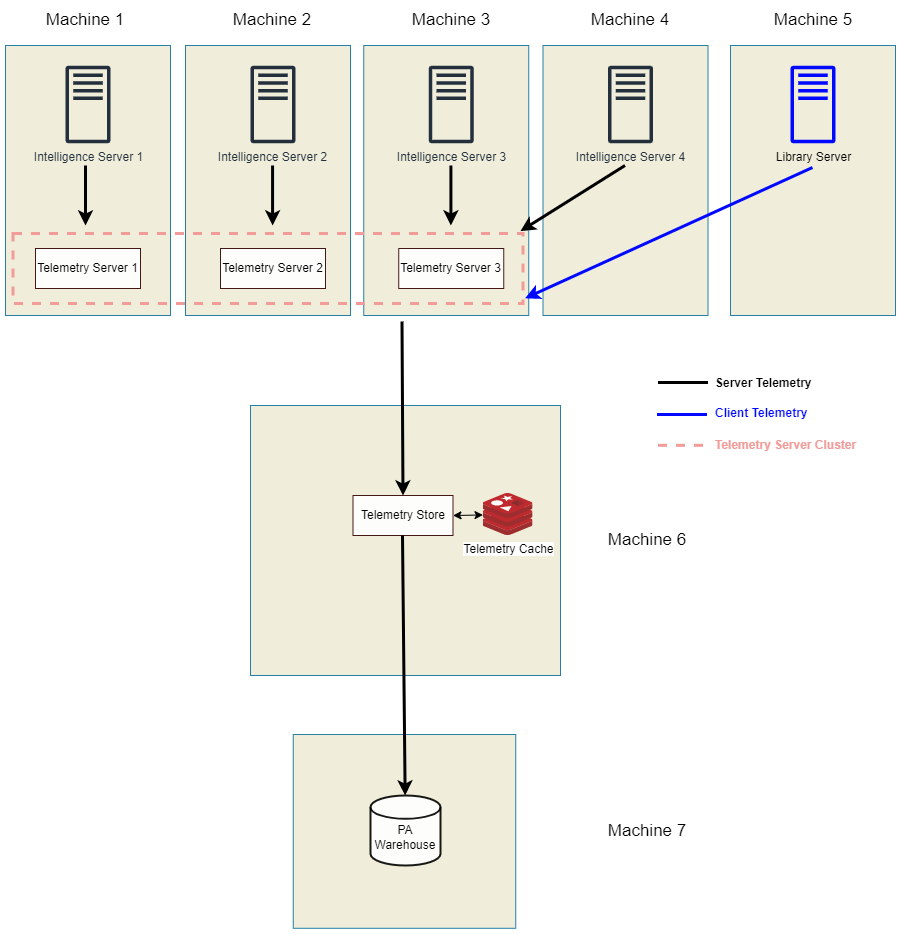
从以下主题开始:
1.1.安装组件
4.4.配置 Platform Analytics Consumer
1.安装组件
首先在相应的环境中安装组件。
-
在安装向导中为机器 1、2 和 3 选择以下组件:
-
MicroStrategy Intelligence
-
MicroStrategy 遥测服务器
-
选择创建集群...在为 Telemetry 创建集群环境时,提供已安装或将要安装 Telemetry 的其他节点或机器地址。对机器 1、2 和 3 重复此操作。
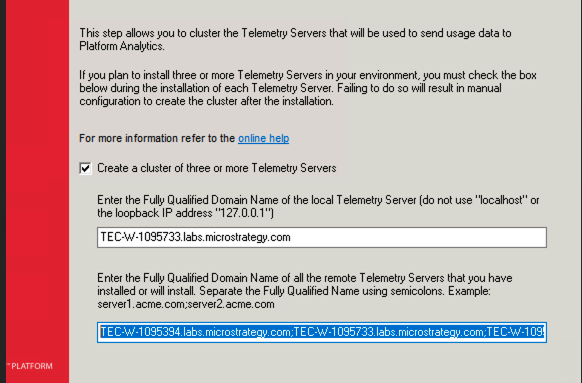
-
-
在安装向导中为机器 4 和 5 选择以下组件:
-
MicroStrategy Intelligence
-
MicroStrategy 遥测服务器
-
- 安装后,关闭 MicroStrategy Telemetry 服务器(Kafka 和 Zookeeper 服务)。
-
在安装向导中为机器 6 选择以下组件:
-
Platform Analytics
-
在安装组件期间,您必须输入存储库(机器 7)的连接信息。
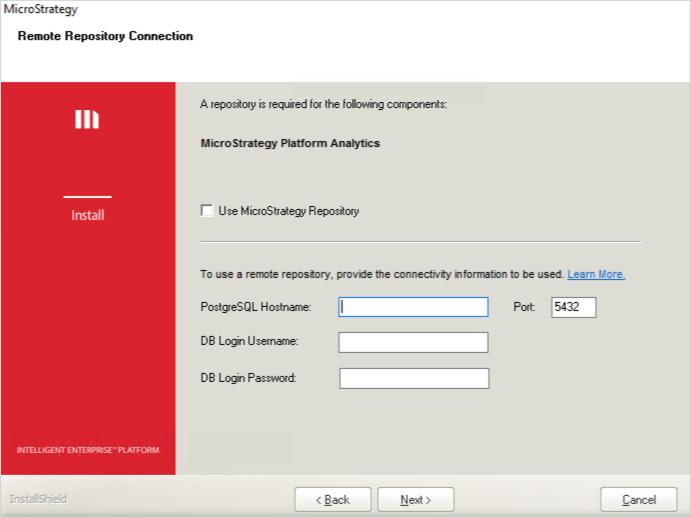
-
-
在机器 7 上安装 Platform Analytics Repository。您可以选择现成的 MicroStrategy 存储库,也可以选择自己的实例PostgreSQL 数据库服务器,由您提供 组织。
-
对于 Windows 部署,请继续对 Windows 进行特定修改以创建 Platform Analytics 服务,否则转到2.配置遥测服务器用于 Linux 部署。
对 Windows 进行特定修改以创建 Platform Analytics 服务
在 Windows 机器上,您必须重新创建平台分析服务以防止服务中断。
-
转至服务。
-
停止 MicroStrategy Platform Analytics Consumer。
-
停止 MicroStrategy Platform Analytics 内存缓存。
-
-
删除 MicroStrategy Platform Analytics Consumer 服务。
-
以管理员权限启动 Windows 命令提示符。
-
执行下列命令:
复制sc delete MSTR_PlatformAnalyticsConsumer -
关闭服务。
-
-
重新创建 Platform Analytics Consumer 服务。
-
导航到 Platform Analytics 目录。
-
打开
MSTR_PlatformAnalyticsConsumer.config进行编辑。 -
删除
--DependesOn =Redis删除依赖服务(Kafka 和 Zookeeper)。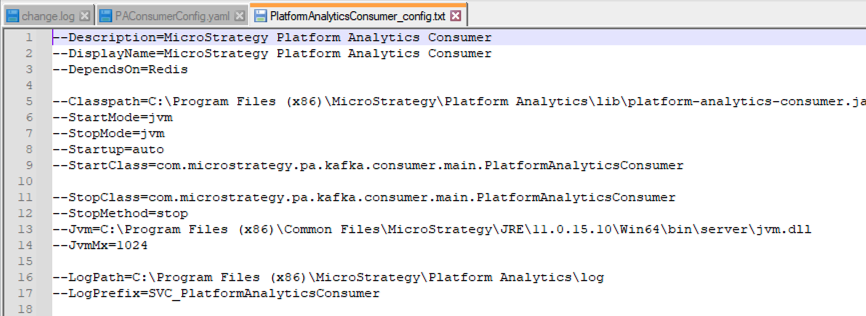
-
-
以管理员权限启动 Windows 命令提示符。
-
导航到 Platform Analytics 目录。
-
执行下列命令:
复制PlatformAnalyticsConsumer.exe install MSTR_PlatformAnalyticsConsumer --Config PlatformAnalyticsConsumer_config.txt
-
-
转至服务。
-
启动 MicroStrategy Platform Analytics Consumer。
-
如果有必要,请刷新服务管理器。
-
2.配置遥测服务器
执行以下步骤全部遥测服务器节点。这个例子使用机器 1、2 和 3。
编辑 server.properties
-
打开
server.properties进行编辑。Windows 位置:
C:\Program Files (x86)\MicroStrategy\Messaging Services\Kafka\kafka_x.x.xx\configLinux 位置:
/opt/MicroStrategy/MessagingServices/Kafka/kafka_x.x.x./config -
在下面
##### Server Basics ####,按照节点故障转移的首选顺序为每个 Telemetry 服务器机器提供唯一的代理 ID。在此示例中:
机器 1:
broker.id=1
机器2:broker.id=2
机器 3:broker.id=3复制# Set the broker id to a unique value for each node.
# Do not change it on the machine configured during single node set up, i.e. your main node. It should be left at the default value and referred to by the other nodes.
# For example,
broker.id=1 -
在“轴”选项卡下,
##### Internal Topic Settings ####,将偏移量和交易状态因素都设置为集群中的节点数量。在此示例中,该数字为 3。复制# offsets.topic.replication.factor= set to the number of nodes in your cluster
# transaction.state.log.replication.factor= set to the number of nodes in your cluster
# For example,
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3 -
在“轴”选项卡下,
##### Zookeeper #####,添加所有遥测服务器节点 IP 地址或 FQDNzookeeper.connect范围。节点顺序必须与broker ID对应 步骤2中的参数。复制# Set zookeeper.connect= to a comma separated list of <IP address:2181> for all nodes in the cluster.
# For example,
zookeeper.connect=10.27.18.73:2181,10.27.18.224:2181,10.27.36.168:2181
编辑 zookeeper.properties
-
打开
zookeeper.properties进行编辑。Windows 位置:
C:\Program Files (x86)\MicroStrategy\Messaging Services\Kafka\kafka_x.x.xx\configLinux 位置:
/opt/MicroStrategy/MessagingServices/Kafka/kafka_x.x.x./config -
在文件末尾添加新行
server.node_id=ip:2888:3888。在此示例中,每个节点都有三条新行。复制# To allow Zookeeper to work with the other nodes in your cluster, add the following properties to the end of the zookeeper.properties file.
# initLimit=5
# syncLimit=2
# server.X= <IP address of the node>:2888:3888
# When adding this property, replace X above with the broker.id for the node being referenced. A separate entry must be made for each node in the cluster.
# For example,
initLimit=5
syncLimit=2
server.0=10.27.18.73:2888:3888
server.1=10.27.18.224:2888:3888
server.2=10.27.36.168:2888:3888
編輯 myid
-
打开
myid进行编辑。如果此文件不存在,您应该创建一个。Windows 位置:
C:\Program Files (x86)\MicroStrategy\Messaging Services\tmp\zookeeperLinux 位置:
/opt/MicroStrategy/MessagingServices/tmp/zookeeper -
确认
myid文件确实不是有一个隐藏的扩展。在文件资源管理器中,转到看法 > 展示 > 文件扩展名显示扩展。如果您的文件有扩展名,请将其删除。 -
确保
broker.id对于每个节点匹配您设置的值server.properties。复制# Make sure the broker.id is the same as it appears in server.properties.
# For example,
broker.id=1
3.重启必要的服务
在集群中所有节点上更新 Kafka 和 Zookeeper 的配置后,必须重新启动服务,包括 Intelligence 服务器。
重启服务时,务必注意必须先完成所有配置文件更改。例如,如果您要添加两个额外的 Kafka 节点并且已经有一个现有节点,则应该在重新启动任何服务之前在所有三个节点上完成安装和配置。
此外,一些服务相互依赖,因此应按照下面提供的顺序启动服务。不按此顺序启动可能会导致服务不一致。
-
在启动其他节点之前,先在主节点上启动 Zookeeper 和 Kafka。
-
在剩余节点上启动 Zookeeper。
-
在剩余节点上启动 Kafka。
4.配置 Platform Analytics Consumer
在运行 Platform Analytics Consumer 的节点上执行以下步骤。在此示例中,即机器 6。
-
打开
PAConsumerConfig.yaml进行编辑。Windows 位置:
C:\Program Files (x86)\MicroStrategy\Platform Analytics\confLinux 位置:
/opt/MicroStrategy/Platform Analytics/conf -
将所有遥测节点 IP 地址添加到文件中,使用以下格式:
zookeeperConnection:IP1:port,IP2:port,IP3:portbootstrap.servers: IP1:port,IP2:port,IP3:port复制# Set kafkaTopicNumberOfReplicas: number of nodes in cluster
# Set zookeeperConnection: <ipAddress:2181> for all nodes in cluster
# Set bootstrap.servers: <ipAddress:9092> for all nodes in cluster
# For example,
kafkaTopicNumberOfReplicas: 3
zooKeeperConnection: 10.27.18.73:2181,10.27.18.224:2181
bootstrap.servers: 10.27.18.73:9092,10.27.18.224:9092 -
确保
kafkaTopicNumberOfReplicas参数与 Telemetry 服务器节点的数量匹配。在这个例子中,这个数字是 3。 -
重新启动以下服务:
-
MicroStrategy 平台分析消费者
-
MicroStrategy Platform Analytics 内存缓存
-