Strategy ONE
Parallel queries
You can improve the speed of a super cube publication with the Maximum Parallel Queries Per Report setting.
To configure parallel data loading
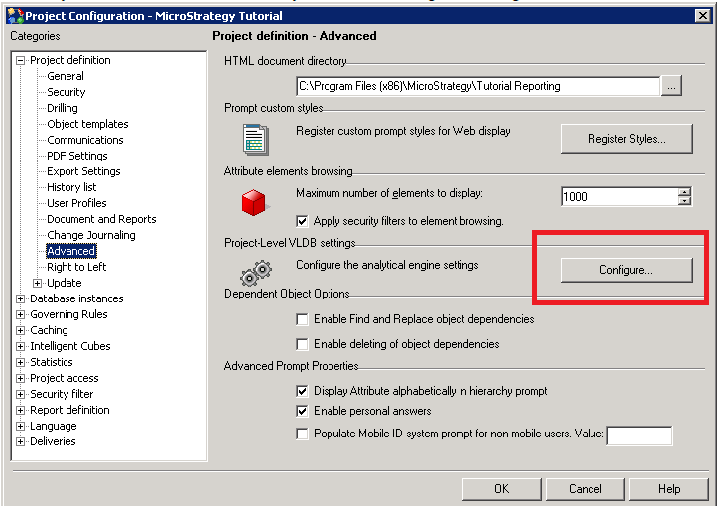
- In MicroStrategy Developer, choose Administration > Project Configuration….
- In the Project Configuration window, under Project definition categories, select Advanced.
-
In Project definition - Advanced, under Project-Level VLDB settings, click Configure….
-
In the VLDB Properties window, choose Tools > Show Advanced Settings.
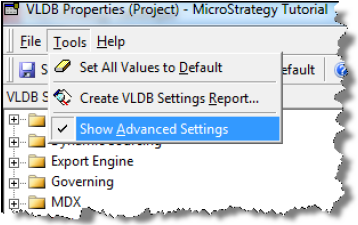
- In the VLDB Properties window, under VLDB settings, expand Query Optimizations.
- Under Query Optimizations, select Maximum Parallel Queries Per Report.
- Clear the Use default inherited value - (Default Setting ) check box.
-
In the Maximum Parallel Queries Per Report field, specify the maximum number of parallel queries per report.
The Network Transfer Rate depends on the theoretical limit between the data source and Intelligence Server. However, if the data source is from a database, the Network Transfer Rate depends on the number of concurrent database threads that can be handled by the database. Each imported table is executed over a single thread. Therefore, to parallelize a big table with multi-table data imports, you may want to build multiple views representing slices to be fetched over an independent connection.
The parallel data fetch option
- Increases speed of Publishing for OLAP Cubes built using the MicroStrategy Developer.
- This is an add-on option and not to be confused with Parallel Query Execution option.
-
Allows for SQL Select Pass for Metrics (typically the last pass) to be fetched over multiple ODBC connections.
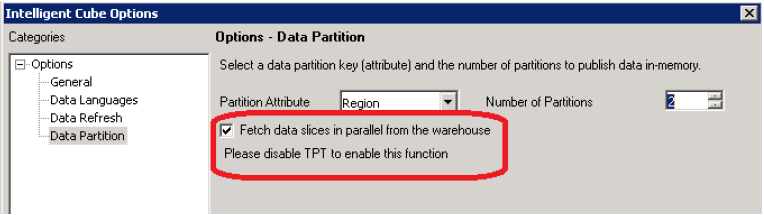
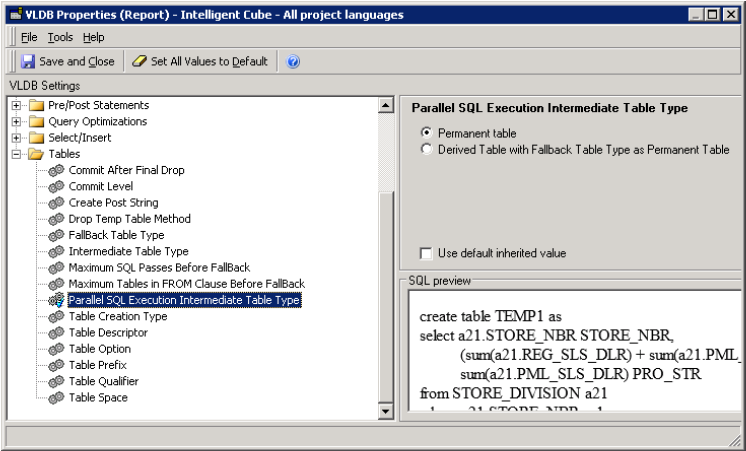
- Users are allowed to switch between Permanent Table (for Generic) and Derived Table syntax (optimal for Single Select). See below.
-
Number of maximum parallel queries for Parallel Data Fetch is governed by Number of Partitions setting in the screenshot above.
VLDB settings compatibility for OLAP cubes
For some of the VLDB settings, Parallel Data Fetch does not take effect, as described in the following sections:
Pre/post statements
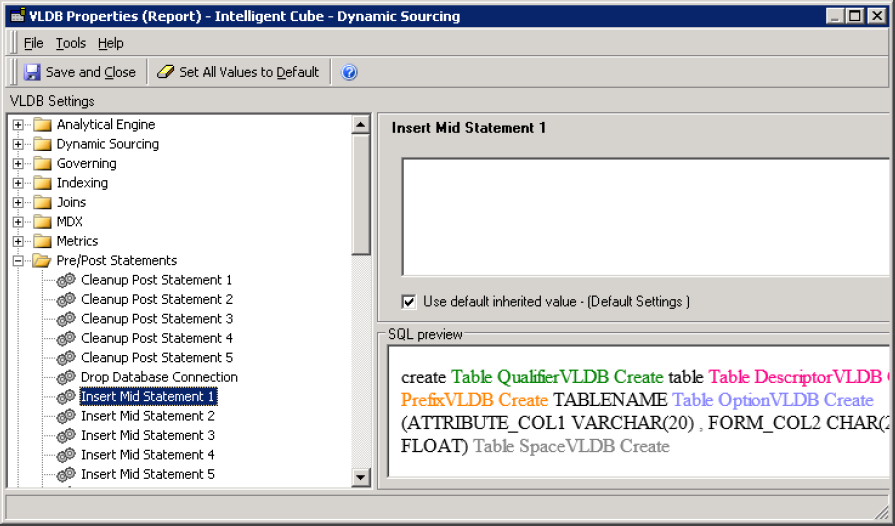
Parallel Data Fetch for OLAP Cubes does not work if Insert Mid Statements is set.
Query optimizations
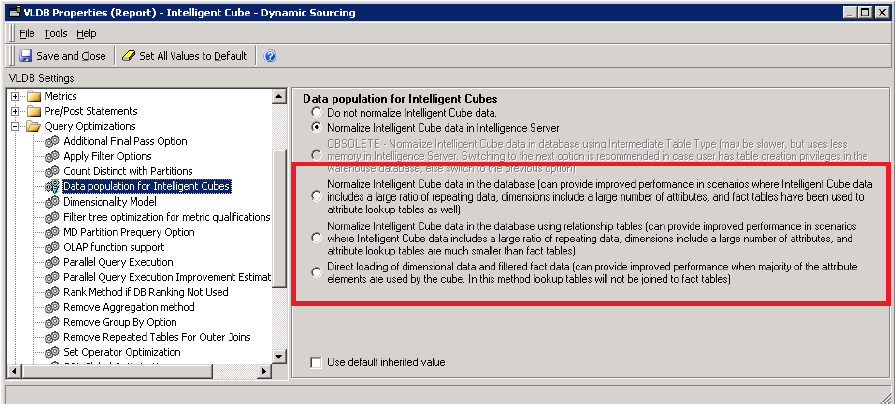
Parallel Data Fetch for OLAP Cubes does not work if any of the options below are chosen for the VLDB setting Data population for Intelligent Cubes:
- Normalize Intelligent Cube data in the database (can provide improved performance in scenarios where Intelligent Cube data includes a large ratio of repeating data, dimensions include a large number of attributes, and fact tables have been used to attribute lookup tables as well)
- Normalize Intelligent Cube data in the database using relationship tables (can provide improved performance in scenarios where Intelligent Cube data includes a large ratio of repeating data, dimensions include a large number of attributes, and attribute lookp tables are much small than fact tables)
-
Direct loading of dimensional data and filtered fact data (can provide improved performance when majority of the attribute elements are used by the cube. In this method, lookup tables will not be joined to fact tables)
Partition attribute ID form type
If ID form (or first form if ID form is compound) of the Partition attribute is String (or related) data type, Parallel Data Fetch for OLAP cubes does not take effect.