Strategy ONE
Architecture of the Task Infrastructure
The architecture of the Task Infrastructure is presented in three sections:
The diagram shown below illustrates how the Task Infrastructure fits in the context of a larger, multi-tiered web application. At the outermost parts of the diagram, there are a series of client applications, divided into two distinct types: client applications that use “web services” and communicate using the SOAP protocol and client applications that are considered to be more traditional “web applications”.
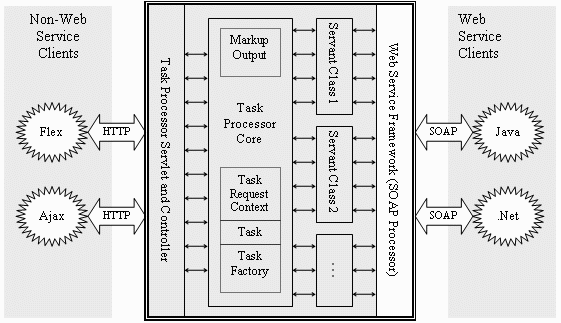
While the client labels used in the diagram (described as “Flex”, “Ajax”, “Java”, and “.Net”) are examples only, most of the technologies are capable of making both web service calls and pure HTTP calls.
Everything inside the heavy, double-lined border is running on the Web Server tier, while everything outside of it is considered to be on the Web Client tier. There are two sets of components on the Web Server tier:
-
Components that are part of the Web Service Framework
The Web Service Framework components provide all of the SOAP processing functionality. Third-party vendors— such as Apache’s Axis 2 framework or Microsoft’s Web Service framework (not MicroStrategy)— convert an incoming SOAP request into a method invocation on a web service implementation class, also called a “servant class”. Servant classes can be generated automatically from an endpoint XML file using the Servant Generator. This XML file defines how a Web Service method maps to a specific task and how the method arguments map to task parameters.
-
Components that are part of MicroStrategy Web
Just as the Web Service Framework receives a SOAP request on a specific port and processes it, the Task Processor Servlet (in coordination with the Task Processor Controller) receives an HTTP request on a different port and processes it.
Whether a request originates from a servant object or from a traditional Web client, the data associated with that request is put into a Task Processor Request State object. It contains both input data (associated with the Request) and output data (associated with the Response). The incoming request data can be encapsulated in a Container Services object, from which all of the name/value pairs as well as any HTTP headers can be retrieved. When the output content is generated, the Task Processor Request State holds the following response information:
-
An error message (if one exists)
-
A task-specific error code (if one exists)
-
The generated content (if the task succeeded)
All requests to the Task Processor proceed through the processRequest method, which instructs the Task to handle the incoming request. This method accepts a TaskProcessorRequestState object and returns a Boolean value (indicating whether the task invocation succeeded or not). If the task succeeded, the generated content—in the form of either a TaskOutput or a MarkupOutput—can be retrieved. If the task failed, only a status code and error message are accessible.
The TaskOutput-based version of the processRequest method is suitable for the majority of Tasks. It assumes that a single content "island" is being constructed and no special handling of that content is required. Tasks that require more sophisticated handling of the generated output should implement the MarkupOutput-based version of processRequest instead. The TaskProcessor invokes the TaskOutput-based version of the processRequest method. As a result, if you build a custom task that extends one of the MicroStrategy base classes (such as AbstractBaseTask}, calls are redirected automatically to the MarkupOutput-based version of processRequest.
In releases prior to 9.0, the TaskProcessor invoked the MarkupOutput-based version of the processRequest method.
The TaskProcessor class is configured to use a specific TaskFactory class. This class is defined in the microstrategy.xml file through the taskFactoryClass initialization parameter. The default value of this parameter is AggregatingTaskFactory. A Task Factory must create an instance of a specific task, based on the task’s unique identifier. The way in which AggregatingTaskFactory performs this is through the use of an XML file that maps a Task ID to a fully-qualified Java class name. The name of the XML file is also defined in microstrategy.xml as the initialization parameter, aggregatingTaskFactoryConfig.
Since a single Task Factory may not be able to create all task instances, the AggregatingTaskFactory aggregates a set of other TaskFactory instances. Here is an example of a simple configuration file:
<!DOCTYPE aggregatingTaskFactory SYSTEM "dtds/aggregatingTaskFactory.dtd">
<aggregatingTaskFactory>
<tasks>
<task registerAs="task1" class="com.acme.tasks.TaskOne" />
<task registerAs="myTask" class="com.acme.tasks.MyTask" />
</tasks>
<factories>
<factory class="com.acme.web.taskFactory.AcmeTaskFactory" />
<factory class="com.microstrategy.web.app.tasks.BeanTaskFactory" />
</factories>
</aggregatingTaskFactory>In the above file, two tasks are defined explicitly— “task1” and “myTask”— and they are instantiated using Java reflection. The nature of these tasks (and any task parameters they possess) is defined within the class and retrieved programmatically. Two additional factories are defined in the same file. One factory (AcmeTaskFactory) presumably provides another mechanism to create tasks (and associate them with a Task ID). The second factory (BeanTaskFactory) is provided by MicroStrategy and can create a task from an XML file definition. Finally, when a task is created, it may elect to perform some one-time initialization. This may be used to initialize persistent data structures used by all requests. Similarly, before the task is destroyed, it may be notified to release any persistent data. Both of these activities are coordinated by the task’s own Task Factory.
After a task instance is created by a Task Factory, that instance is held by the Task Processor in the Task Instance Cache and used to fulfill all requests for that task. Only the TaskProcessorRequestState object, which contains all per-request data, is created for a task invocation. While some tasks are very simple, others are more complex and may need to allocate and manage more per-request data elements. Because of the stateless nature of a task, the recommended practice is for task designers to provide their own Task Request Context object, rather than using Java instance fields to hold this data.
To fulfill a request, the processRequest method of the Task interface is invoked. This method takes two parameters: the first is the TaskRequestContext object (created by the task itself and populated with the ContainerServices and RequestKeys objects) and the second is either a TaskOutput or a MarkupOutput object in which the generated content is placed.
There are a number of ways in which a task can be constructed and a variety of classes that make this process easier. The relationship between TaskProcessor, TaskFactory, Task, and TaskRequestContext (among others) is illustrated below, followed by an explanation of the steps involved in creating a task.
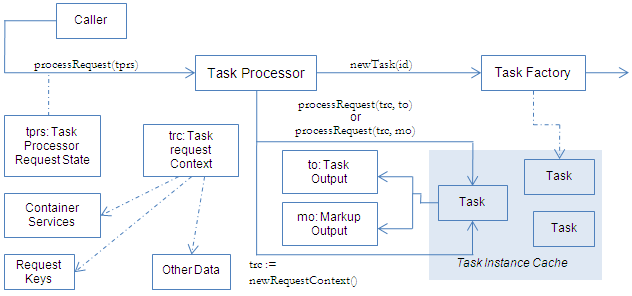
The flow of method calls during task construction can be summarized as follows:
-
The caller constructs a TaskProcessorRequestState object (called tprs). This object obtains a ContainerServices instance that holds all data associated with the request.
-
The caller passes the TaskProcessorRequestState object into the TaskProcessor instance (via the processRequest method). It is assumed that a single instance of the TaskProcessor is held by the caller for all subsequent requests.
-
The TaskProcessor first attempts to obtain an instance of the requested task. The ID of the requested task is included in the ContainerServices object.
-
If there is an instance of the task in the Task Instance Cache, it is returned. Otherwise, the program proceeds to the next step.
-
The TaskFactory instance is used to try to create a new instance of the task via newTask. If one is returned, it is saved in the Task Instance Cache and then returned. Otherwise, the program proceeds to the next step.
-
If no instance of the task is found, a TaskException is raised. A top-level catch block populates the TaskProcessorRequestState object (tprs) with information about the failure.
-
-
Next, the task is asked for a new TaskRequestContext object (call it trc). The contents of the TaskProcessorRequestState object (tprs) are copied into it.
-
Either a new TaskOutput instance (call it to) or a new MarkupOutput instance (call it mo) is created.
-
The task’s processRequest method is called (passing in trc and either to or mo).
-
The task performs the necessary data collection and content generation (storing the results in the supplied TaskOutput or MarkupOutput object).
-
If problems occur along the way, it may raise a TaskException.
-
-
-
The generated content is saved back into the TaskProcessorRequestState object. Success is indicated.
Task Processor Servlet and Controller
Task-related requests from traditional web applications are served by the TaskProcessorServlet. Consistent with the MicroStrategy Web architecture, the Servlet class puts all HttpServlet-specific data into neutral data structures (such as ContainerServices) and invokes the TaskProcessorController singleton, which performs all of the necessary actions to invoke the TaskProcessor and formulate a response back to the web client.
After a request has finished, the TaskProcessorController must construct a complete response. It does so through the use of a set of response envelopes. A response envelope is a pair of JSP files in MicroStrategy Web Universal (or ASP.NET files in MicroStrategy Web) that define how to place the generated content in the context of a larger response. One file defines how to construct successful responses, and the other defines how to construct failure messages.
The TaskProcessorController also handles the duties of the Task Processor Administrator application. The TaskProcessorController reads the definition of all envelopes— as well as Task Processor Administrator web pages— from the file specified in the microstrategy.xml initialization parameter, taskProcessorControllerConfig.