Strategy ONE
Synchronizing Cached Information Across Nodes in a Cluster
In a clustered environment, each node shares cached information with the other nodes so that the information users see is consistent regardless of the node to which they are connected when running reports. All nodes in the cluster synchronize the following cached information:
- Metadata information and object caches (for details, see Synchronizing Metadata)
- Result caches and Intelligent Cubes (for details, see Sharing Result Caches and Intelligent Cubes in a Cluster)
- History Lists (for details, see Synchronizing History Lists)
To view clustered cache information, such as cache hit counts, use the Cache Monitor.
Result cache settings are configured per project, and different projects may use different methods of result cache storage. Different projects may also use different locations for their cache repositories. However, History List settings are configured per project source. Therefore, different projects cannot use different locations for their History List backups.
For result caches and History Lists, you must configure either multiple local caches or a centralized cache for your cluster. The following sections describe the caches that are affected by clustering, and it presents the procedures to configure caches across cluster nodes.
Synchronizing Metadata
Metadata synchronization refers to the process of synchronizing object caches across all nodes in the cluster.
For example, when a user connected to a node in a cluster modifies a metadata object, the cache for that object on other nodes is no longer valid. The node that processed the change automatically notifies all other nodes in the cluster that the object has changed. The other nodes then delete the old object cache from memory. The next request for that object that is processed by another node in the cluster is executed against the metadata, creating a new object cache on that node.
In addition to server object caches, client object caches are also invalidated when a change occurs. When a user requests a changed object, the invalid client cache is not used and the request is processed against the server object cache. If the server object cache has not been refreshed with the changed object, the request is executed against the metadata.
Sharing Result Caches and Intelligent Cubes in a Cluster
In a non-clustered environment, Intelligent Cubes and report and document caches (result caches) are typically stored on the Intelligence Server machine. For an overview of Intelligent Cubes, see Managing Intelligent Cubes, or see the In-memory Analytics Help. For an overview of result caches, see Result Caches.
In a clustered environment, each node in a cluster must share its result caches and Intelligent Cubes with the other nodes, so all clustered machines have the latest cache information. For example, for a project, result caches on each node that has loaded the project are shared among other nodes in the cluster that have also loaded the project. Configuring caches to be shared among appropriate nodes eliminates the overhead associated with executing the same report or document on multiple nodes.
- Both memory and disk caches are shared among nodes.
- When an Intelligent Cube is updated, either through Incremental Refresh or by republishing the Intelligent Cube, the updated Intelligent Cube is available on all nodes of the cluster as soon as it is loaded into memory.
Intelligent Cube and result cache sharing among nodes can be configured in one of the following ways:
- Local caching: Each node hosts its own cache file directory and Intelligent Cube directory. These directories need to be shared so that other nodes can access them. For more information, see Local Caching.
If you are using local caching, the cache directory must be shared as "ClusterCaches" and the Intelligent Cube directory must be shared as "ClusterCube". These are the share names Intelligence Server looks for on other nodes to retrieve caches and Intelligent Cubes.
- Centralized caching: All nodes have the cache file directory and Intelligent Cube directory set to the same network locations,
\\<machine name>\<shared cache folder name>and\\<machine name>\<shared Intelligent Cube folder name>. For more information, see Centralized Caching.For caches on Windows machines, and on Linux machines using Samba, set the path to
\\<machine name>\<shared cache folder name>. For caches on Linux machines, set the path to//<SharedLocation>/<CacheFolder>.
The following table summarizes the pros and cons of the result cache configurations:
|
|
Pros |
Cons |
|
Local caching |
Allows faster read and write operations for cache files created by the local server. Faster backup of cache lookup table. Allows most caches to remain accessible even if one node in a cluster goes offline. |
The local cache files may be temporarily unavailable if an Intelligence Server is taken off the network or powered down. A document cache on one node may depend on a dataset that is cached on another node, creating a multi-node cluster dependency. |
|
Centralized caching |
Allows for easier backup process. Allows all cache files to be accessible even if one node in a cluster goes offline. May better suit some security plans because nodes using a network account are accessing only one machine for files. |
All cache operations are required to go over the network if shared location is not on one of the Intelligence Server machines. Requires additional hardware if shared location is not on an Intelligence Server. All caches become inaccessible if the machine hosting the centralized caches goes offline. |
MicroStrategy recommends storing the result caches locally if your users mostly do ad hoc reporting. In ad hoc reporting the caches are not used very much, and the overhead incurred by creating the caches on a remote file server outweighs the low probability that a cache may be used. On the other hand, if the caches are to be heavily used, centralized caching may suit your system better.
For steps to configure cache files with either method, see Configure Caches in a Cluster.
Local Caching
In this cache configuration, each node maintains its own local Intelligent Cubes and local cache file and, thus, maintains its own cache index file. Each node's caches are accessible by other nodes in the cluster through the cache index file. This is illustrated in the diagram below.
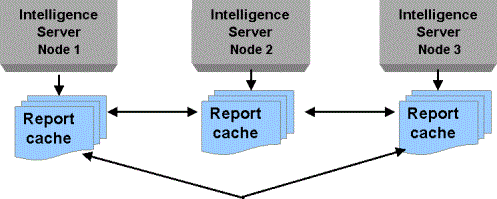
For example, User A, who is connected to node 1, executes a report and thus creates report cache A on node 1. User B, who is connected to node 2, executes the report. Node 2 checks its own cache index file first. When it does not locate report cache A in its own cache index file, it checks the index file of other nodes in the cluster. Locating report cache A on node 1, it uses that cache to service the request, rather than executing the report against the warehouse.
Centralized Caching
In this cache configuration, all nodes in the cluster use one shared, centralized location for Intelligent Cubes and one shared, centralized cache file location. These can be stored on one of the Intelligence Server machines or on a separate machine dedicated to serving the caches. The Intelligent Cubes, History List messages, and result caches for all the Intelligence Server machines in the cluster are written to the same location. In this option, only one cache index file is maintained. This is illustrated in the diagram below.
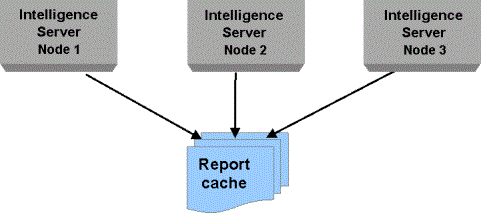
For example, User A, who is connected to node 1, executes report A and thus creates report cache A, which is stored in a centralized file folder. User B, who is connected to node 2, executes report A. Node 2 checks the centralized cache index file for report cache A. Locating report cache A in the centralized file folder, it uses that cache to service the request, regardless of the fact that node 1 originally created the cache.
Synchronizing History Lists
A History List is a set of pointers to cache files. Each user has their own History List, and each node in a cluster stores the pointers created for each user who is connected to that node. Each node's History List is synchronized with the rest of the cluster. Even if report caching is disabled, History List functionality is not affected.
If you are using a database-based History List, History List messages and their associated caches are stored in the database and automatically synchronized across all nodes in the cluster.
If you are using a file-based History List, the Intelligence Server Inbox folder contains the collection of History List messages for all users, which appear in the History folder in Developer. Inbox synchronization refers to the process of synchronizing History Lists across all nodes in the cluster, so that all nodes contain the same History List messages. Inbox synchronization enables users to view the same set of personal History List messages, regardless of the cluster node to which they are connected.
For more background information on History Lists, see Saving Report Results: History List. For steps to set up History List sharing in a file-based system, see Configure Caches in a Cluster.
MicroStrategy recommends that you enable user affinity clustering to minimize History List resource usage. User affinity clustering causes Intelligence Server to connect all sessions for a user to the same node of the cluster. This enables Intelligence Server to keep the user's History List on one node of the cluster. Resource use is minimized because the pointers to the History List are not stored on multiple machines. In addition, if you are using a file-based History List, the History List is never out of sync across multiple nodes of the cluster. For instructions on how to enable user affinity clustering, see Configure Caches in a Cluster.