Version 2021
Análisis de datos masivos en MicroStrategy
En el sector de Business Intelligence y de los análisis, los datos masivos implican principalmente el consumo de grandes cantidades de datos que los sistemas tradicionales no pueden procesar. Los datos masivos requieren nuevas tecnologías para almacenar, procesar, realizar búsquedas, analizar y visualizar estos grandes conjuntos de datos.
Si desea obtener más información, consulte los siguientes temas:
Nuevos usuarios: Descripción general: proporciona una introducción general a los datos masivos
Usuarios con experiencia:
- Conexión y análisis de orígenes de datos masivos en MicroStrategy: explica cómo utilizar MicroStrategy para conectar con orígenes de datos masivos.
- Flujos de trabajo de ejemplo para conectar con orígenes de datos masivos: incluye ejemplos de configuración de conexiones.
Descripción general de los datos masivos
Esta sección sirve como introducción general a los datos masivos y proporciona un resumen de la terminología y los casos de uso más frecuentes. Abarca los siguientes temas:
- Casos de uso de datos masivos
- Características de los datos masivos
- Dificultades al adoptar datos masivos
- Descripción general de los componentes de Hadoop
Casos de uso de datos masivos
Las tecnologías de datos masivos han habilitado casos de uso que antes no eran posibles debido a la gran cantidad de datos o a la complejidad de los análisis. Hoy en día, comprender y aprovechar la información que encierran los datos masivos resulta útil para todo tipo de empresas:
- Los comercios desean ofrecer un servicio al cliente superior y personalizado, y proporcionar a sus asociados información sobre el comportamiento de compra de los clientes, los productos actuales, los precios y las promociones. La ejecución de análisis de datos masivos con MicroStrategy puede ayudar al personal de las tiendas a ofrecer una experiencia relevante y personalizada a los clientes.
- Los fabricantes se enfrentan a una constante demanda por aumentar la eficiencia, reducir los precios y mantener los niveles de servicio, lo que les obliga a reducir costes a lo largo de toda la cadena de suministro. También necesitan analizar el consumo examinando las ventas de los productos en relación con la demografía y el comportamiento de compra de los consumidores. Mediante MicroStrategy, los fabricantes pueden ejecutar análisis de datos masivos en diferentes orígenes para lograr unas tasas de pedidos y una calidad perfectas, así como obtener patrones de consumo pormenorizados.
- Las compañías de telecomunicaciones necesitan planificar y optimizar la capacidad de red; para ello, correlacionan el uso de red con la densidad de suscriptores y los datos de tráfico y ubicación. Gracias a MicroStrategy, pueden ejecutar análisis para supervisar y predecir con exactitud la capacidad de la red, planificar de forma eficaz los cortes potenciales y realizar promociones.
- Las compañías médicas aspiran a utilizar los petabytes de datos de sus pacientes para aumentar las ventas farmacéuticas, mejorar los análisis de los pacientes y conseguir unas mejores soluciones para los pagadores. MicroStrategy permite crear y ejecutar eficazmente aplicaciones que ayuden a dar respuesta a estos casos de uso.
- La administración pública se enfrenta a amenazas de seguridad, dinámica de poblaciones, presupuestos y finanzas, entre otras operaciones a gran escala. Las capacidades analíticas de MicroStrategy con conjuntos de datos grandes y complejos pueden ofrecer a los trabajadores públicos una visión profunda que les permita tomar decisiones políticas informadas, evitar el despilfarro y el fraude, identificar amenazas potenciales y planificar las futuras necesidades de los ciudadanos.
Características de los datos masivos
Los datos masivos plantean nuevos desafíos, y requieren nuevos enfoques para responder a dichos desafíos. A medida que las empresas desarrollan planes para habilitar los casos de uso de los datos masivos, deben tener en cuenta las características de las 5V de los datos masivos: volumen, variedad, velocidad, variabilidad y valor.
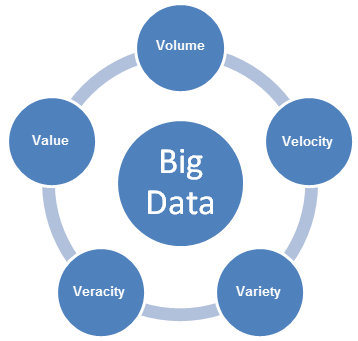
- Volumen se refiere al tamaño de los datos de contenido generado que se debe analizar.
- Velocidad se refiere a la velocidad con la que se generan los datos nuevos, y la velocidad con la que se mueven los datos.
- Variedad se refiere a los tipos de datos que se pueden analizar. Anteriormente, el sector de los análisis se centraba en los datos estructurados que podían organizarse en tablas y columnas y se almacenaban en bases de datos relacionales. Sin embargo, muchos de los datos actuales carecen de estructura, y no resulta sencillo organizarlos en tablas. En un nivel más general, los datos se pueden dividir en las tres categorías siguientes: Cada una de ellas requiere un enfoque distinto para analizar los datos.
- Datos estructurados: datos cuya estructura es conocida. Los datos residen en un campo fijo dentro de un archivo o registro.
- Datos no estructurados: información que carece de una organización o un modelo de datos definidos. Los datos pueden ser textuales (cuerpo de mensaje de correo electrónico, mensajes instantáneos, documentos de Word, presentaciones de PowerPoint, archivos PDF) o no textuales (archivos de audio/vídeo/imagen).
- Datos semiestructurados: cruce entre datos estructurados y no estructurados. Los datos se estructuran sin un modelo de datos estricto, como datos de registros de eventos o cadenas de pares clave-valor.
- Veracidad se refiere a la credibilidad de los datos. Con muchos orígenes y formas de datos masivos, es más difícil controlar la calidad y la precisión.
- Valor se refiere a la capacidad de convertir los datos masivos en un valor empresarial claro, lo que requiere acceso y análisis para obtener unos resultados significativos.
Dificultades al adoptar datos masivos
A medida que las empresas desarrollan soluciones para recopilar la información presente en sus sistemas de datos masivos, experimentan las siguientes dificultades:
- Rendimiento: las organizaciones que buscan implementar análisis avanzados en los datos masivos se esfuerzan por lograr un rendimiento interactivo.
- Federación de datos: las aplicaciones del mundo real requieren la integración de datos de múltiples proyectos. Federar los datos almacenados en formatos dispares y de orígenes diferentes supone todo un reto.
- Limpieza de datos: para las empresas supone un desafío limpiar las diferentes formas de datos para preparar los análisis.
- Seguridad: mantener la seguridad de esta vasta cantidad de datos es complicado, incluido el uso adecuado del cifrado, el registro del historial de acceso a los datos, y el acceso a los datos a través de los diferentes mecanismos de verificación de identidad estándar de la industria.
- Relación valor-tiempo: las empresas están deseosas de acortar el tiempo necesario para liberar el valor de los datos. A menudo, lidiar con numerosos orígenes, con diferentes tipos de datos, y utilizar una red de soluciones específicas requiere mucho tiempo.
Descripción general de los componentes de Hadoop
En esta sección se describen los componentes principales del ecosistema de Hadoop.
Apache Hadoop es un marco de software de código abierto para el almacenamiento y el procesamiento distribuidos, que permite a las organizaciones almacenar y consultar datos con un tamaño de varios órdenes de magnitud mayor que los datos de las bases de datos tradicionales, y hacerlo en un entorno agrupado y asequible. En la siguiente imagen se muestra un diagrama de la arquitectura de los componentes de Apache Hadoop.
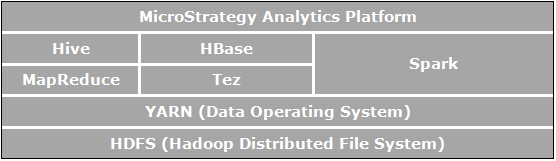
Los elementos que están directamente relacionados con el análisis empresarial y son relevantes para los casos de uso habilitados por MicroStrategy son:
- HDFS (Sistema de archivos distribuido de Hadoop) es el sistema de archivos de almacenamiento de datos que utilizan las aplicaciones de Hadoop; se ejecuta en los clústeres de los equipos comerciales. Los clústeres de HDFS consisten en un NameNode que administra los metadatos del sistema de archivos y DataNodes que almacenan los datos reales. HDFS permite almacenar archivos de gran tamaño importados de aplicaciones externas al ecosistema de Hadoop y archivos importados provisionales para que las aplicaciones de Hadoop los procesen.
- YARN (Otro negociador de recursos) ofrece gestión de recursos y es una plataforma central para suministrar herramientas de operaciones, seguridad y gobernanza de datos en los clústeres de Hadoop para las aplicaciones que se ejecutan en Hadoop.
- MapReduce es un modelo distribuido de procesamiento de datos y entorno de ejecución que se ejecuta en grandes clústeres de equipos comerciales. Utiliza el algoritmo de MapReduce que divide todas las operaciones en funciones Map o Reduce.
- Tez es un marco generalizado de programación de flujos de datos que se ha diseñado para ofrecer un rendimiento mejorado de los flujos de trabajo de consultas SQL en comparación con MapReduce.
- Hive es un almacén de datos distribuido que se implementa sobre HDFS para administrar y organizar grandes cantidades de datos. Proporciona un almacén de datos esquematizado para albergar grandes cantidades de datos sin formato y un entorno similar a SQL para realizar análisis y tareas de consulta en datos sin procesar en HDFS. Este entorno parecido a SQL de Hive es la forma más popular de realizar consultas en Hadoop. Además, Hive puede utilizarse para dirigir las consultas SQL a diversos motores de consulta como Map-Reduce, Tez, Spark, etc.
- Spark es un marco de computación con clústeres. Proporciona un modelo de programación sencillo y expresivo que admite una amplia gama de aplicaciones, como ETL, aprendizaje automático, procesamiento de transmisiones y computación de gráficos.
- HBase es una base de datos distribuida orientada a columnas. Emplea HDFS para su almacenamiento subyacente, y admite las computaciones por lotes tanto con MapReduce como con consultas específicas (lecturas aleatorias) que sean transaccionales.
Conexión y análisis de orígenes de datos masivos en MicroStrategy
El ecosistema de datos masivos tiene varios motores SQL (Hive, Impala, Drill, etc.) que permiten a los usuarios enviar consultas SQL a orígenes de datos masivos y analizar los datos de la misma forma que con las bases de datos relacionales tradicionales. De esta forma, los usuarios pueden aprovechar el mismo marco de análisis que utilizan cuando acceden a datos estructurados mediante SQL.
MicroStrategy admite y certifica la conectividad con varios motores SQL de datos masivos. Al igual que las bases de datos tradicionales, la conectividad con estos motores SQL se realiza a través de controladores ODBC o JDBC.
MicroStrategy también ofrece un método que permite a los usuarios importar datos directamente del sistema de archivos de Hadoop (HDFS). Esto se consigue mediante Hadoop Gateway de MicroStrategy, que permite a los clientes eludir los motores de consultas SQL y cargar los datos directamente desde el sistema de archivos en los cubos en memoria de MicroStrategy para analizarlos.
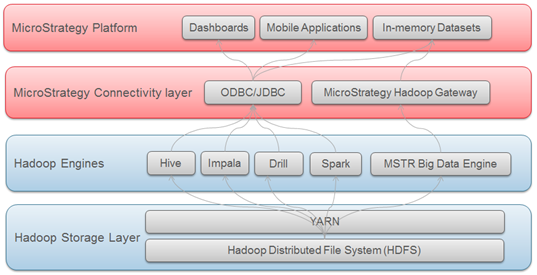
En el siguiente diagrama se muestran las capas que atraviesan los datos para llegar a MicroStrategy desde los sistemas de Hadoop.
Selección del modo de acceso a los datos
MicroStrategy permite a los usuarios aprovechar eficazmente los recursos del sistema de datos masivos y del sistema de BI de forma conjunta para lograr el mejor rendimiento al realizar análisis. Los usuarios tienen las siguientes opciones:
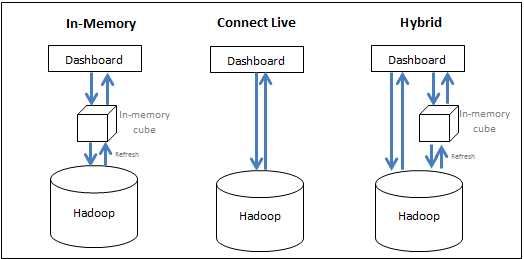
- Transferir datos a la memoria (enfoque en memoria): los datos para analizar se obtienen exclusivamente del cubo en memoria. MicroStrategy permite a los usuarios extraer subconjuntos de datos, que pueden alcanzar un tamaño de cientos de gigabytes, de un origen de datos masivos a un cubo en memoria, y crear informes o dossiers desde el cubo. Normalmente, un cubo está configurado para publicarse a intervalos periódicos y se guarda en la memoria principal del servidor, lo que elimina la necesidad de consultar la base de datos masivos, algo que requiere mucho tiempo.
- Acceder a los datos directamente en su origen (enfoque de conexión en vivo): a los datos se accede exclusivamente desde la base de datos. MicroStrategy ofrece conectividad a varios orígenes de datos masivos para ejecutar informes y dossiers de forma dinámica y en directo en el origen.
- Adoptar un enfoque híbrido: los datos se obtienen del cubo en memoria y de la base de datos, según sea necesario. El enfoque híbrido aprovecha eficazmente las virtudes de los dos métodos anteriores, ya que permite al usuario alternar sin problemas entre uno y otro en función de las consultas enviadas por los usuarios. MicroStrategy cuenta con tecnología de origen dinámico que determina automáticamente si a una consulta específica debe responder un cubo o la base de datos y dirige la consulta en consecuencia.
En la siguiente ilustración se resumen los tres enfoques:
Aunque el enfoque en memoria suele ofrecer el mejor rendimiento al realizar análisis, puede resultar poco práctico si hay un gran volumen de datos. En la siguiente sección se analizan las consideraciones de diseño a la hora de decidir cómo se debe acceder a los datos.
- Enfoque en memoria: este enfoque ofrece el rendimiento más rápido; sin embargo, el tamaño de los datos se limita al que puede admitir la memoria principal y, en función de la frecuencia con la que se actualicen los datos en memoria, los datos podrían volverse obsoletos. Utilice este enfoque si:
- Los datos finales están agregados y caben en la memoria principal del equipo de BI.
- La base de datos es demasiado lenta para el análisis interactivo.
- El usuario necesita reducir la carga de una base de datos transaccionales.
- El usuario necesita estar desconectado.
- La seguridad de los datos se puede configurar en el nivel de BI.
- Enfoque de conexión en vivo: en situaciones donde los datos del dossier deban ser actuales, o si los datos tienen tal nivel de detalle que hace imposible almacenarlos todos en el cubo en memoria, crear un dossier mediante la opción de conexión en vivo podría ser un enfoque adecuado. Esto permite recuperar los datos más recientes del almacén en cada ejecución. Este método también es útil en aquellos casos donde la seguridad está configurada en el nivel de base de datos y es necesario ejecutar el almacén de datos para mostrar a cada usuario los datos a los que tiene acceso. Utilice este enfoque si:
- La base de datos es rápida y responde adecuadamente.
- El usuario accede a datos que se actualizan a menudo en la base de datos.
- El volumen de los datos es mayor que el límite en memoria.
- Los usuarios desean una entrega planificada de un dossier ejecutado previamente.
- La seguridad de los datos está configurada en el nivel de base de datos.
- Enfoque híbrido: este enfoque es adecuado para los casos de uso donde la pantalla de presentación del dossier contiene información agregada de alto nivel desde la que los usuarios navegan para obtener los detalles. En esos casos, los administradores pueden publicar los datos agregados en un cubo en memoria de modo que la pantalla principal del dossier aparezca rápidamente, y luego hacer que el dossier consulte los datos de nivel inferior en el sistema de datos masivos cuando el usuario explore en profundidad. La capacidad de origen dinámico de MicroStrategy facilita la creación de estas aplicaciones, ya que los informes seleccionados se pueden convertir en cubos y MicroStrategy determinará automáticamente si consultar los cubos o la base de datos, en función de los datos solicitados por el usuario.
Controladores y proveedores de datos masivos admitidos
Hadoop mediante los motores de SQL están optimizados para determinados manipulación de datos. En función del tipo de datos y las consultas ejecutadas para acceder a los datos, podemos dividir los casos de uso en los cinco grupos siguientes:
- SQL por lotes: se utiliza para realizar transformaciones de datos masivos a gran escala.
- SQL interactivo: habilita el análisis interactivo de datos masivos.
- Sin SQL: se utiliza normalmente para el almacenamiento de datos a gran escala y las consultas transaccionales rápidas.
- Datos no estructurados / motores de búsqueda: se utiliza para analizar datos de texto o datos de registros, principalmente para utilizar funciones de búsqueda.
- Limpiar y cargar datos en memoria / Hadoop Gateway: está optimizado y se utiliza principalmente para publicar rápidamente cubos en memoria.
En la siguiente ilustración se muestra la relación entre los casos de uso y los motores que MicroStrategy admite actualmente.
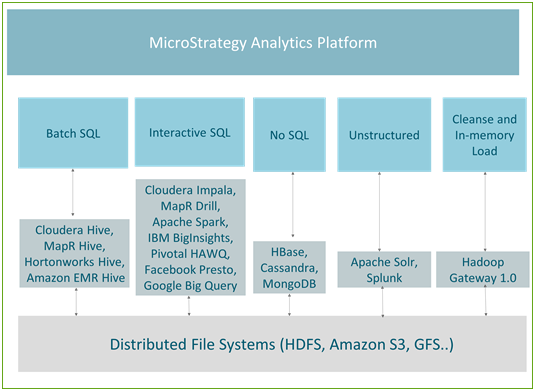
Procesamiento por lotes
Hive es el mecanismo de consultas más popular para el procesamiento por lotes. Como es tolerante a los errores, se recomienda para los trabajos de tipo ETL. Todas las principales distribuciones de Hadoop (como Hortonworks, Cloudera, MapR y Amazon EMR) ofrecen conectores de ODBC de Hive. MicroStrategy colabora con todos estos proveedores de Hadoop y ofrece conectividad certificada a Hadoop a través de Hive.
Hive es un buen motor para el enfoque en memoria en MicroStrategy o como parte del enfoque de conexión en vivo cuando se emplea junto con servicios de distribución, de modo que la latencia de la base de datos no afecte al usuario final. Dado que utiliza MapReduce para procesar las consultas, el procesamiento por lotes tiene una latencia alta y no está indicado para las consultas interactivas.
En la tabla siguiente se enumera la información de conectividad de las distribuciones de Hadoop admitidas.
| Proveedor | Conectividad | Caso de uso | Nombre de controlador | Flujo de trabajo |
|---|---|---|---|---|
| Hide de Cloudera | ODBC | Herramienta que toma SQL y lo convierte en Map Reduce; se puede utilizar para realizar una transformación similar a ETL a gran escala en los datos | Controlador ODBC de MicroStrategy para Hive | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Hide de Hortonworks |
ODBC |
Herramienta que toma SQL y lo convierte en Map Reduce; se puede utilizar para realizar una transformación similar a ETL a gran escala en los datos | Controlador ODBC de MicroStrategy para Hive | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Hive de MapR | ODBC | Herramienta que toma SQL y lo convierte en Map Reduce; se puede utilizar para realizar una transformación similar a ETL a gran escala en los datos | Controlador ODBC de MicroStrategy para Hive | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Hive de Amazon EMR | ODBC | Herramienta que toma SQL y lo convierte en Map Reduce; se puede utilizar para realizar una transformación similar a ETL a gran escala en los datos | Controlador ODBC de MicroStrategy para Hive | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
Consultas interactivas
Varios proveedores de Hadoop han desarrollado motores de rendimiento rápido que permiten las consultas interactivas. Estos motores utilizan mecanismos específicos de proveedor/tecnología para consultar HDFS, pero siguen utilizando Hive como tienda de metadatos. Todas estas tecnologías están evolucionando a un ritmo acelerado para lograr tiempos de respuesta cada vez más rápidos con conjuntos de datos de gran tamaño, así como capacidades de análisis avanzadas. Los motores interactivos como Impala, Drill o Spark se pueden combinar de forma eficaz con MicroStrategy Dossier para habilitar la detección de datos de autoservicio en Hadoop. Además, estos motores están certificados para funcionar con MicroStrategy.
En la tabla siguiente se enumera la información de conectividad de las distribuciones admitidas.
| Proveedor | Conectividad | Caso de uso | Nombre de controlador | Flujo de trabajo |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Motor de consultas SQL de procesamiento paralelo masivo (MPP) y código abierto para datos almacenados en un clúster de equipos que ejecutan Apache Hadoop. Impala utiliza su propio motor de procesamiento y puede realizar operaciones en memoria. | Controlador ODBC de MicroStrategy para Impala | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Apache Drill | ODBC | Motor de consultas de latencia baja y código abierto compatible con MapR. Tiene la capacidad de detectar esquemas sobre la marcha para ofrecer capacidades de exploración de datos como autoservicio. | Controlador ODBC de MicroStrategy para Drill | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Apache Spark | ODBC | Herramienta de procesamiento de datos que funciona en colecciones de datos distribuidas; la desarrolla una de las mayores comunidades de código abierto. Gracias a su procesamiento en memoria, Spark es un orden de magnitud más rápido que MapReduce. | Controlador ODBC de MicroStrategy para Apache Spark SQL | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| IBM BigInsights | ODBC | Variado conjunto de capacidades de análisis avanzadas que permite a las empresas analizar enormes cantidades de datos estructurados y no estructurados en su formato nativo en Hadoop. | Controlador ODBC para BigInsights | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Pivotal HAWQ | ODBC | Motor de consultas SQL en paralelo que lee y escribe datos en HDFS de forma nativa. Proporciona a los usuarios una completa interfaz SQL compatible con ANSI estándar. | Controlador ODBC de MicroStrategy para Greenplum Wire Protocol | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
| Google BigQuery | ODBC | Servicio basado en la nube que aprovecha la infraestructura de Google para permitir a los usuarios consultar de forma interactiva petabytes de datos. | Controlador ODBC de MicroStrategy para Google BigQuery | Compatible mediante MicroStrategy Architect y MicroStrategy Data Import |
Orígenes no SQL
Los orígenes que no son SQL están optimizados para el almacenamiento de información de gran tamaño y las consultas transaccionales. Se pueden combinar de forma eficaz con la opción de orígenes múltiples o de mezcla de datos en MicroStrategy, de modo que a los usuarios se les muestre información de alto nivel de las bases de datos transaccionales, y utilizar el origen no SQL para permitir explorar en profundidad hasta los datos transaccionales de nivel inferior mediante la integración con orígenes no SQL.
En la siguiente tabla se enumeran los orígenes no SQL para los que MicroStrategy ofrece conectividad certificada.
| Proveedor | Conectividad | Caso de uso | Nombre de controlador | Flujo de trabajo |
|---|---|---|---|---|
| Apache Cassandra | JDBC | Tienda donde todos los datos consisten en un par indexado de clave-valor. | Controlador JDBC para Cassandra | Compatible mediante MicroStrategy Data Import |
| HBase | JDBC | Base de datos no SQL de almacén de columnas que, en lugar de almacenar los datos en filas, los almacena en tablas como secciones de columnas de datos. Ofrece un alto rendimiento y una arquitectura escalable. | Controlador JDBC para Phoenix | Compatible mediante MicroStrategy Data Import |
| MongoDB | ODBC | Base de datos orientada a documentos que evita la tradicional estructura de base de datos relacional basada en tablas, lo que facilita y agiliza la integración de datos en ciertos tipos de aplicaciones. | Mongodb controlador ODBC de MicroStrategy | Compatible mediante MicroStrategy Data Import |
Datos no estructurados/motores de búsqueda
Los motores de búsqueda son eficaces herramientas que permiten a los usuarios realizar búsquedas en grandes volúmenes de datos de texto y agregar contexto a los datos dentro de sus dossiers. Esta función es muy útil cuando se combina con la mezcla de datos en MicroStrategy, permitiendo emparejar los datos de búsqueda con los orígenes empresariales tradicionales.
En la tabla siguiente se enumera la información de conectividad de las distribuciones de Hadoop admitidas.
| Proveedor | Conectividad | Caso de uso | Nombre de controlador | Flujo de trabajo |
|---|---|---|---|---|
| Apache Solr | Nativo | El motor de búsqueda de código abierto más popular, permite las búsquedas de texto completo, las búsquedas con facetas y la creación de índices en tiempo real. MicroStrategy ha creado un conector para integrarse con Solr. Proporciona la capacidad de realizar búsquedas dinámicas, analizar y visualizar los datos indexados de Solr. | integrado | Compatible mediante MicroStrategy Data Import |
| Splunk Enterprise | ODBC | Un motor de búsqueda propietario ampliamente utilizado | Controlador ODBC para Splunk | Compatible mediante MicroStrategy Data Import |
Hadoop Gateway de MicroStrategy
MicroStrategy ofrece conectividad nativa con HDFS mediante Hadoop Gateway. Hadoop Gateway omite Hive y accede directamente a los datos de HDFS. Hadoop Gateway se instala de forma independiente en los nodos HDFS.
Hadoop Gateway se ha diseñado para optimizar un caso de uso donde se crea un cubo en memoria de gran tamaño al conectarse a Hadoop. Emplea las siguientes técnicas para importar datos por lotes desde Hadoop de forma eficaz:
- Omite Hive para acceder a los datos directamente: se comunica de forma nativa con HDFS al ejecutarse como una aplicación YARN, eludiendo Hive/ODBC. Esto reduce aún más el tiempo de acceso y de consulta de los datos.
- Carga en paralelo de los datos desde HDFS: carga los datos en MicroStrategy Intelligence Server a través de subprocesos paralelos, con una mayor capacidad de proceso y un menor tiempo de carga.
- Habilita la limpieza de datos de arriba a abajo para el caso de uso en memoria: las operaciones de conversión de datos se ejecutan en Hadoop, lo que permite la conversión a gran escala.
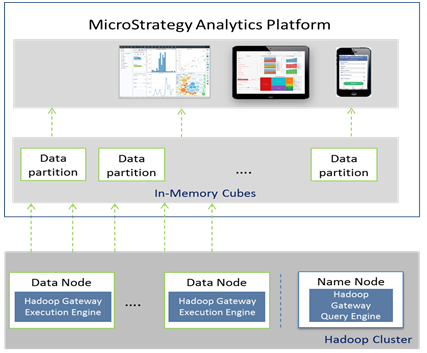
Descripción general de la arquitectura de Hadoop Gateway
- Hadoop Gateway, propiedad de MicroStrategy, se instala de forma independiente y es necesario instalarla en los nodos de nombres y de datos de HDFS. Para ello, se debe instalar lo siguiente:
- Motor de consultas de Hadoop Gateway en el nodo de nombres de HDFS
- Motor de ejecución de Hadoop Gateway en el motor de ejecución de HDFS
- MicroStrategy Intelligence Server envía la consulta al motor de ejecución de Hadoop Gateway; a continuación, la consulta se analiza y se envía a los nodos de datos para su procesamiento. Los datos recuperados por la consulta se transfieren desde los nodos de datos al servidor MicroStrategy Intelligence Server en subprocesos paralelos para su publicación en los cubos en memoria.
En la siguiente ilustración se muestra Hadoop Gateway de MicroStrategy en un diagrama de arquitectura.
Limitaciones de Hadoop Gateway
Actualmente, Hadoop Gateway presenta algunas limitaciones:
- Solo se admiten archivos de texto y csv.
- Solo se admite la conversión de datos para el caso de uso en memoria.
- No se admite la importación de datos de varias tablas.
- Para las capacidades analíticas, solo se admiten la agregación y el filtrado. No se admiten las operaciones JOIN.
- La seguridad de Kerberos se admite con un servicio compartido de usuario vs. delegación para usuarios específicos.
Flujos de trabajo de ejemplo para conectar con orígenes de datos masivos
Esta sección incluye ejemplos de los diversos flujos de trabajo para conectar con orígenes de datos masivos desde MicroStrategy:
- Para conectar a través de Web Data Import a Hortonworks Hive
- Para conectar a través de Web Data Import a Hortonworks Hive
- Para conectar mediante Hadoop Gateway
Conexión mediante Developer a Hortonworks Hive
Los administradores y desarrolladores de Business Intelligence pueden utilizar MicroStrategy Developer para conectarse a un origen de datos masivos siguiendo los pasos que se mencionan a continuación. El flujo de trabajo es similar a la manera tradicional de integrar bases de datos con MicroStrategy. Los pasos se pueden dividir en tres áreas conceptuales:
- Crear una conexión con el origen desde MicroStrategy. Esto incluye crear un origen de datos de ODBC con detalles de conectividad adecuados y un objeto de instancia de base de datos que apunte al origen de ODBC.
- Importar las tablas del origen mediante la interfaz del Catálogo de Warehouse.
- Crear los objetos de esquema necesarios (como atributos, hechos, etc.) para generar informes y dossiers.
En los siguientes pasos, Hortonworks Hive se muestra como ejemplo.
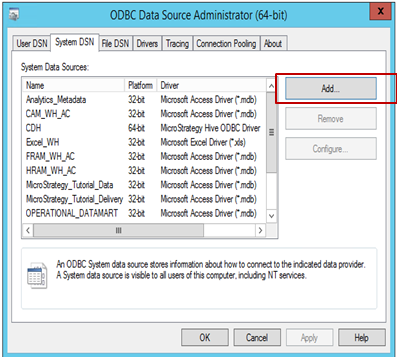
Para crear una conexión con el origen desde MicroStrategy:
-
Abra el Administrador de orígenes de datos ODBC para crear una conexión con el origen de los datos. Haga clic en Agregar para crear una nueva conexión.
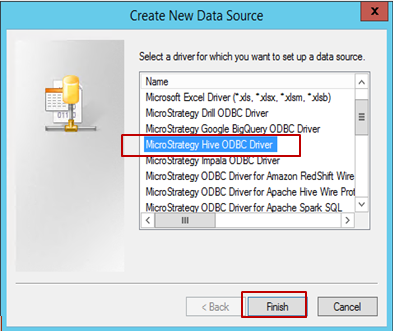
-
Seleccione el controlador (en este ejemplo, Hive ODBC está seleccionado) y haga clic en Terminar.
-
Rellene los detalles de conectividad correspondientes:
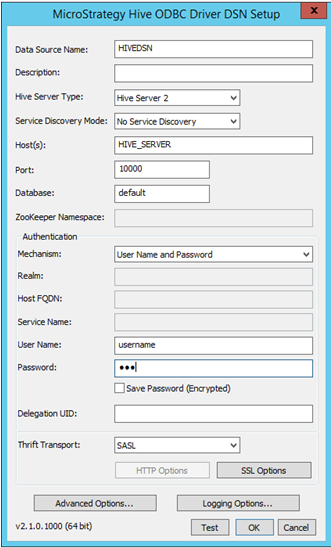
- Nombre de origen de datos: nombre con el que se guarda la conexión
- Descripción: Opcional
- Tipo de servidor Hive: seleccione el servidor según el entorno
-
Modo de detección de servicios: existen dos modos de detección de servicios, que se muestran a continuación. Cuando el usuario selecciona ‘Zookeeper’, MicroStrategy permite escribir en el espacio de nombres de Zookeeper, como se muestra a continuación.
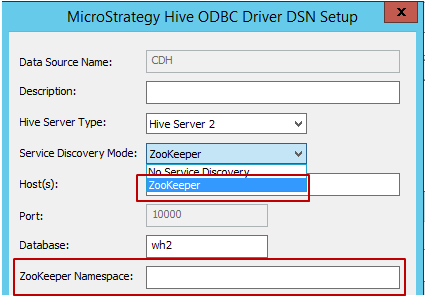
- Host, puerto y nombre de base de datos: campos requeridos; rellene los adecuados según el entorno.
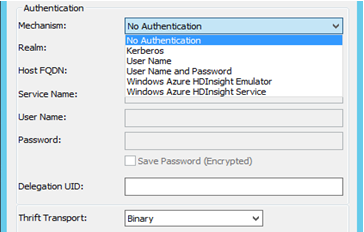
- Verificación de identidad: MicroStrategy certifica diferentes mecanismos de verificación de identidad para Hortonworks Hive: Sin verificación de identidad, Kerberos, nombre de usuario, nombre de usuario y contraseña. En función del mecanismo seleccionado, el parámetro de transporte Thrift cambiará. Por ejemplo:
- Para Sin verificación de identidad: el parámetro de transporte Thrift es ‘Binary’.
- Para Kerberos: el parámetro de transporte Thrift es ‘SASL’.
Nombre de usuario, nombre de usuario y contraseña: el parámetro de transporte Thrift es ‘SASL’.
- Después de seleccionar y rellenar los detalles de la conexión, se puede probar con el botón ‘Prueba’.
-
Abra MicroStrategy Developer. Inicie sesión en el proyecto -> Vaya a Configuration Manager -> Instancias de base de datos -> Cree una nueva instancia de base de datos.
Si está ejecutando MicroStrategy Developer en Windows por primera vez, ejecútelo como administrador.
Haga clic con el botón derecho en el icono del programa y seleccione Ejecutar como administrador.
Esto es necesario para establecer correctamente las claves de registro de Windows. Para obtener más información, consulte KB43491.
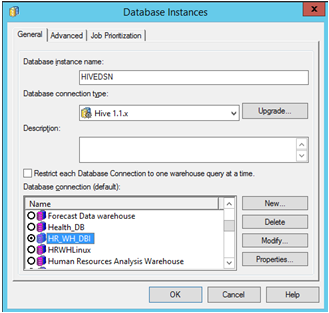
Seleccione el ‘Nombre de origen de datos’ que se creó previamente para el origen. Rellene el ID de usuario y contraseña requeridos.
-
Importe las tablas del origen: Vaya a Esquema -> Catálogo de Warehouse -> Seleccione la instancia de base de datos -> Arrastre y suelte las tablas necesarias del origen.
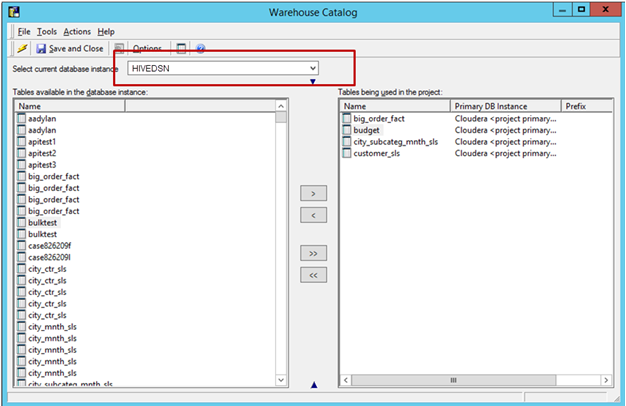
Guarde y cierre el catálogo.
-
Cree atributos e indicadores según sea necesario. Inicie un nuevo informe de MicroStrategy para generar el análisis.
Para conectar a través de Web Data Import a Hortonworks Hive
Los analistas de negocio y los usuarios finales pueden aprovechar el flujo de trabajo de MicroStrategy Web Data Import para conectar y analizar datos del mismo modo que con los orígenes de datos relacionales. Se puede dividir en tres áreas conceptuales: Conectar, importar y analizar.
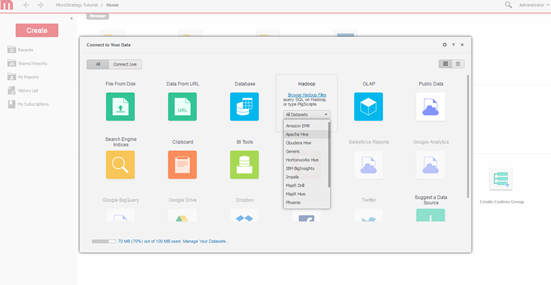
A continuación, se muestra la ventana de conectividad de MicroStrategy Web Data Import cuando se conecta a Hortonworks Hive.
-
Seleccione el motor de consultas. Seleccione el motor para conectar mediante la pantalla de importación de datos de MicroStrategy.
-
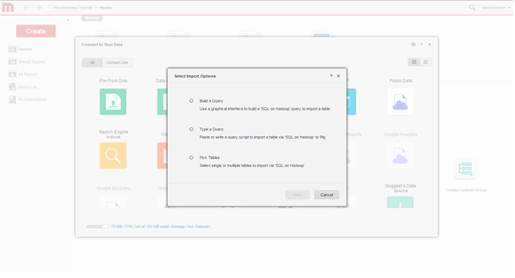
Seleccione las opciones de importación. Seleccione si desea crear una consulta, escribir una consulta o seleccionar tablas. Se recomienda el método de selección de tablas porque hace el mejor uso de las capacidades de modelado de MicroStrategy.
-
Cree la conexión. Defina una nueva conexión al sistema de Hadoop.
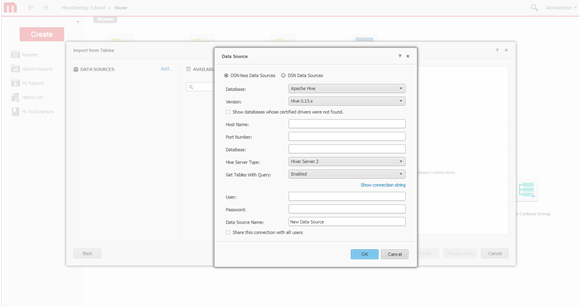
-
Seleccione las tablas. Seleccione las tablas a cuyos datos se accederá.
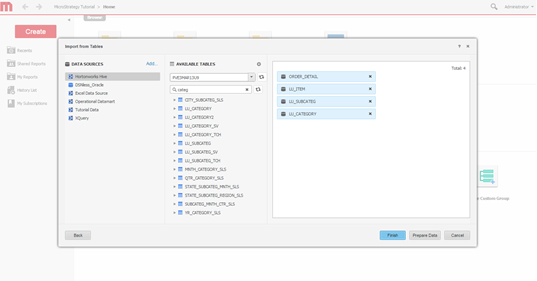
-
Modele los datos. Opcionalmente, modele las tablas, cambie el nombre de los atributos y los indicadores, excluya columnas de la importación, etc.
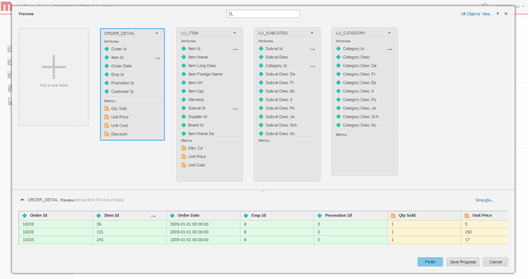
-
Defina el modo de acceso a los datos. Elija si desea publicar los datos como un cubo en memoria o a través del modo de conexión en vivo.
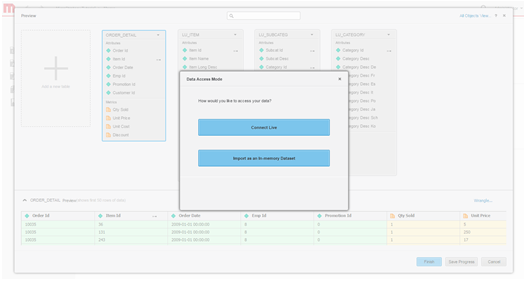
- Cree el dossier.
Para conectar mediante Hadoop Gateway
Hadoop Gateway se puede aprovechar con MicroStrategy Web Data Import, siguiendo el típico flujo de trabajo de importación de datos:
- Crear una conexión con el clúster de Hadoop/HDFS
- Explorar carpetas e importar desde HDFS
- Limpiar los datos (opcional)
- Publicar los datos como un cubo en memoria en el servidor MicroStrategy Intelligence Server y analizar los datos mediante un dossier
A continuación se incluyen los detalles de cada uno de estos pasos.
-
Cree la conexión.
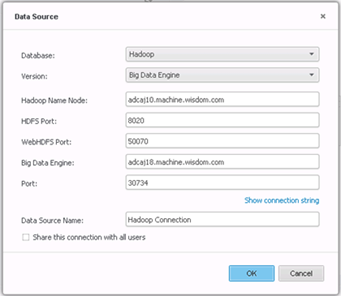
-
Seleccione las tablas que desee importar.
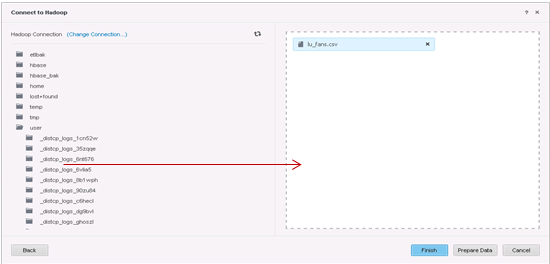
-
Prepare los datos con Data Wrangler.
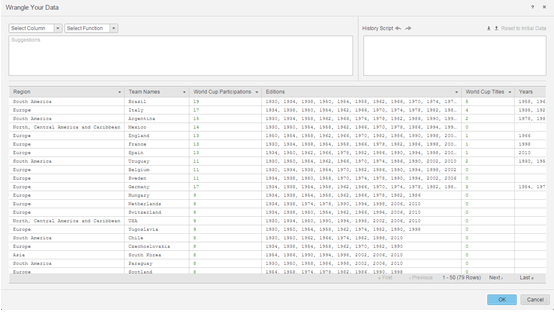
- A continuación, los siguientes pasos son publicar los cubos en memoria en un servidor MicroStrategy Intelligence Server y utilizar la interfaz de exploración visual de datos para crear un dossier.