Version 2021
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (ADLS2) es una plataforma de lago de datos totalmente integrada con Azure Blob Storage. MicroStrategy Cloud Object Connector proporciona acceso a ADLS2 para explorar rápidamente carpetas y archivos e importarlos en cubos de MicroStrategy.
Explore los siguientes temas en esta página:
Preparar parámetros de conexión
Para que Cloud Object Connector explore correctamente el sistema de archivos ADLS2, necesita una cuenta de almacenamiento con un espacio de nombres jerárquico. Para obtener más detalles sobre la creación de una cuenta de almacenamiento, consulte la Documentación de Microsoft.
Una vez creada la cuenta de almacenamiento, se conceden dos claves de acceso. Se puede utilizar cualquiera de los dos para crear una conexión.
Crear un DBRole
Acceda al conector de objetos en la nube de Azure Data Lake Storage Gen2 en MicroStrategy Web o Workstation.
- Web
- Workstation
- Haga clic en Agregar datos > Datos nuevos.
-
Buscar y seleccionar Azure Data Lake Storage Gen2 Conector de objetos en la nube de la lista de orígenes de datos.
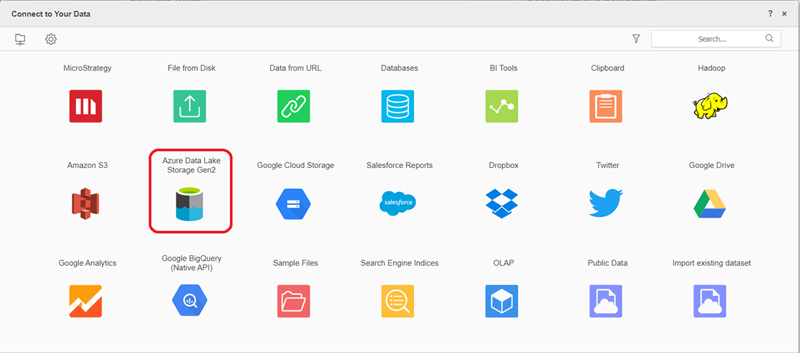
-
Junto a Orígenes de datos, haga clic enNuevo origen de datos
 para agregar una nueva conexión.
para agregar una nueva conexión.
-
Introduzca sus credenciales de conexión.
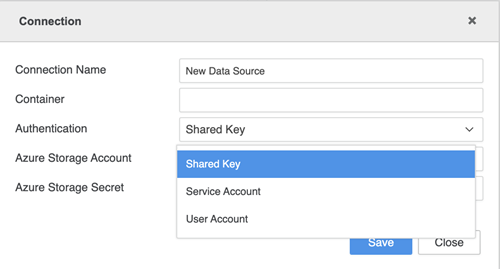
- Nombre de conexión: Un nombre para la nueva conexión
- Contenedor: El contenedor al que desea acceder
- Autenticación: El método de autenticación que desea utilizar
- ID de directorio (inquilino): El ID asociado con cada suscripción
- Cuenta de almacenamiento de Azure: La cuenta de almacenamiento que contiene los objetos de datos de Azure Storage
- Secreto de almacenamiento de Azure: El secreto asociado con el almacenamiento de Azure
-
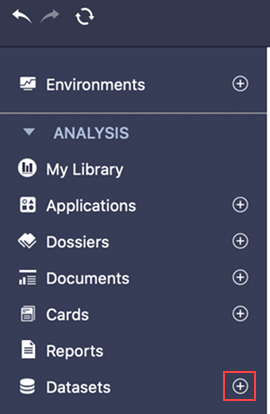
En el panel izquierdo, junto a Conjuntos de datos, haga clic en Crear un nuevo conjunto de datos
.
-
Buscar y seleccionar Azure Data Lake Storage Gen2 Conector de objetos en la nube de la lista de orígenes de datos.
-
Junto a Orígenes de datos, haga clic enNuevo origen de datos
para agregar una nueva conexión.
-
Introduzca sus credenciales de conexión.
- Nombre de conexión: Un nombre para la nueva conexión
- ID de directorio (inquilino): El ID asociado con cada suscripción
- Cuenta de almacenamiento de Azure: La cuenta de almacenamiento
- Contenedor: El contenedor al que desea acceder
- ID de cliente: El ID de cliente utilizado
- Secreto de cliente: El secreto del cliente asociado con el ID del cliente
Importar datos
Una vez que haya creado correctamente el conector, puede importar datos en MicroStrategy.
- Seleccione la conexión recién creada.
- Explorar las carpetas o los archivos del contenedor específico,
-
Haga doble clic en los archivos o arrástrelos al panel derecho.
En el panel Vista preliminar, puede ver los datos de ejemplo y ajustar el tipo de columna.
- Publique el cubo en MicroStrategy con los datos seleccionados.
Limitaciones
Tipos de archivo admitidos
Solo se admiten los siguientes tipos de archivo:
- .json
- .parquet
- .avro
- .orc
- .csv
- Formato delta
Seleccionar carpetas
Al seleccionar toda la carpeta, la carpeta debe cumplir los siguientes requisitos:
- Todos los archivos de la carpeta deben tener el mismo tipo de archivo. Un cuadro de diálogo le pedirá que elija el tipo de archivo
- Todos los archivos comparten el mismo esquema
-
Si la carpeta tiene subcarpetas, las subcarpetas deben tener un formato de particiones válido. El siguiente es un ejemplo de una estructura de carpetas válida
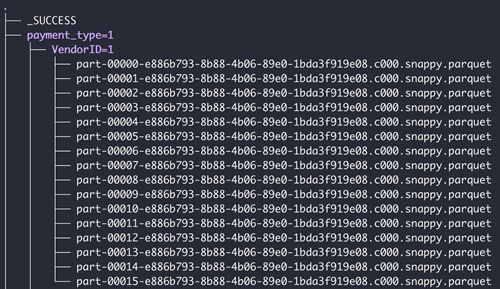
Limitaciones de Spark
- Solo se pueden leer archivos JSON con cada nueva línea como un JSON completo
- Los archivos Parquet que contienen caracteres especiales (,; {} \ = ".) No se pueden leer
- Los archivos Parquet con tipos de datos de columna como INT32 (UINT_8) / (UNIT_16) / (UNIT_32) / (Time_MILLIS) no son compatibles
- Las columnas de tipo binario no se pueden publicar en el cubo
- Los archivos ORC con nombres de campo precedidos por "_col" (p. Ej., _Col0, _col1), donde el esquema de archivo contiene al menos una estructura anidada, una matriz o un campo de mapa, no se pueden importar
Funciones
Las siguientes funciones no son compatibles:
- Carga de archivos de MicroStrategy conectando a Cloud Object Connector
- Transformación de datos en la importación de datos
- Definir la geografía en la importación de datos
- Planificación avanzada para la publicación de Schedule Cube
- Agrupar tablas en la importación de datos