Version 2021
Analisando Big Data no MicroStrategy
Nos setores de Business Intelligence e Analítica, práticas de Big Data envolvem principalmente o consumo de grandes volumes de dados que não podem ser manipulados por sistemas tradicionais. O Big Data exige novas tecnologias para armazenar, processar, pesquisar, analisar e visualizar os conjuntos de dados extensos.
Para obter mais informações, consulte os seguintes tópicos:
Novos usuários: Visão geral – Fornece uma introdução geral ao Big Data
Usuários experientes:
- Conectando e analisando fontes de Big Data no MicroStrategy – discute como usar o MicroStrategy para estabelecer uma conexão com fontes Big Data
- Exemplos de fluxos de trabalho para conexão com fontes de Big Data – mostra exemplos de configuração de conexão
Visão geral do Big Data
Esta seção serve como uma introdução geral ao Big Data e resume a terminologia e os casos de uso mais comuns. Ela abrange os seguintes tópicos:
- Casos de uso para Big Data
- Características do Big Data
- Desafios ao adotar o Big Data
- Visão geral dos componentes Hadoop
Casos de uso para Big Data
As tecnologias Big Data possibilitaram casos de uso que não eram viáveis antes, quer devido a grandes volumes de dados ou análises complexas. Atualmente, o aproveitamento das informações e ideias contidas no Big Data ajudam todos os tipos de negócios:
- Os varejistas desejam oferecer atendimento diferenciado e personalizado ao cliente, equipando seus associados com informações sobre o comportamento de compra dos clientes, produtos circulantes, preços e promoções. A execução de processos analíticos de Big Data com o MicroStrategy pode ajudar o pessoal das lojas a fornecer uma experiência personalizada e relevante para o cliente.
- Os fabricantes enfrentam a constante demanda por maior eficiência, preços mais baixos e níveis de serviço constantes, o que os obriga a reduzir os custos ao longo de toda a cadeia de abastecimento. Eles também precisam de análises de consumo, examinando as vendas dos produtos em relação à demografia dos consumidores e ao comportamento de compra. Usando o MicroStrategy, esses fabricantes podem executar análises de Big Data em fontes distintas para atingirem níveis perfeitos de qualidade e taxas de pedidos e também para obterem padrões detalhados de consumo.
- As empresas de telecomunicação precisam de otimização e planejamento da capacidade de rede, correlacionando o uso da rede e a densidade de assinantes com dados de tráfego e localização. As empresas de telecomunicações que usam o MicroStrategy podem executar processos analíticos para monitorar e prever com precisão a capacidade da rede, planejar efetivamente possíveis paralisações e executar promoções.
- As instituições de saúde procuram usar os petabytes de dados de pacientes que as organizações de saúde possuem para melhorar as vendas farmacêuticas, aprimorar a análise de pacientes e permitir soluções melhores para os pagadores. A MicroStrategy pode construir e executar aplicativos com eficiência para ajudar a atender esses casos de uso.
- O governo lida com ameaças à segurança, dinâmica populacional, orçamento e finanças, entre outras operações de grande escala. Os recursos analíticos da MicroStrategy em conjuntos de dados grandes e complexos podem fornecer ao pessoal do governo profundas percepções, permitindo que eles tomem decisões políticas bem fundamentadas, eliminem desperdícios e fraudes, identifiquem possíveis ameaças e façam planos para as necessidades futuras dos cidadãos.
Características do Big Data
O Big Data traz novos desafios e requer novas abordagens para lidar com esses desafios. À medida que as empresas desenvolvem planos para possibilitar casos de uso de Big Data, elas precisam considerar as características 5V do Big Data: Volume, Variedade, Velocidade, Veracidade e Valor.
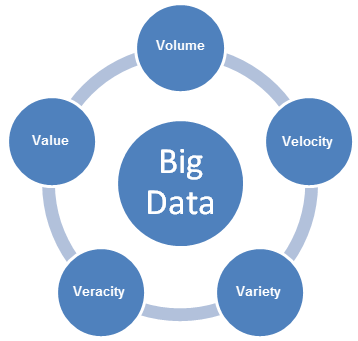
- Volume refere-se ao tamanho do conteúdo de dados gerado que precisa ser analisado.
- Velocidade refere-se à velocidade com que novos dados são gerados e movidos.
- Variedade refere-se aos tipos de dados que podem ser analisados. Anteriormente, a indústria de análises concentrava-se em dados estruturados que se adaptavam a tabelas e colunas e que eram geralmente armazenadas em bancos de dados relacionais. No entanto, grande parte dos dados do mundo é agora não estruturada e não pode ser facilmente colocada em tabelas. Em um nível mais amplo, os dados podem ser divididos em três categorias a seguir. Cada uma delas requer abordagens diferentes para analisar os dados
- Dados Estruturados são dados cuja estrutura é conhecida. Esses dados residem em um campo fixo dentro de um arquivo ou registro.
- Dados não Estruturados são informações que não têm uma organização ou um modelo de dados definido. Os dados podem ser textuais (corpo de e-mail, mensagens instantâneas, documentos do Word, apresentações em PowerPoint, PDFs) ou não textuais (arquivos de áudio/vídeo/imagem).
- Dados Semi-estruturados são um cruzamento entre dados estruturados e não estruturados. Esses dados são estruturados sem um modelo de dados rigoroso, como dados de log de eventos ou strings de pares chave/valor.
- Veracidade refere-se à confiabilidade dos dados. Com muitas fontes e formas de Big Data, a qualidade e a precisão são menos controláveis.
- Valor refere-se à capacidade de transformar o Big Data em um valor bem-definido para os negócios, o que requer acesso e análises para produzir uma saída significativa.
Desafios ao adotar o Big Data
À medida que as empresas desenvolvem soluções para explorar as informações presentes em seus sistemas de Big Data, elas enfrentam os seguintes desafios:
- Desempenho: Organizações que procuram implementar análises avançadas em Big Data se esforçam para obter desempenho interativo.
- Federação de Dados: Aplicativos reais exigem a integração de dados entre projetos. É um desafio federar dados armazenados em formatos e fontes diferentes.
- Limpeza de dados: As empresas consideram um desafio limpar os variados formatos de dados em preparação para análises.
- Segurança: Manter o grande lago de dados seguro é um desafio, incluindo o devido uso de criptografia, o registro de históricos de acesso a dados e o acesso aos dados por meio de vários mecanismos de autenticação padrão da indústria.
- Tempo até a obtenção de valor: As empresas fazem questão de encurtar o tempo necessário para revelar o valor dos dados. Lidar com inúmeras fontes de tipos variados de dados e usar uma rede de soluções de ponto para fazer isso é uma estratégia muitas vezes demorada.
Visão geral dos componentes Hadoop
Esta seção descreve os principais componentes do ecossistema Hadoop.
O Apache Hadoop é uma estrutura de software de código-fonte aberto para armazenamento e processamento distribuídos que permite às organizações armazenar e consultar dados cuja ordem de magnitude é maior do que a dos dados em bancos de dados tradicionais e fazer isso em um ambiente clusterizado de baixo custo. A figura abaixo mostra um diagrama de arquitetura dos componentes do Apache Hadoop.
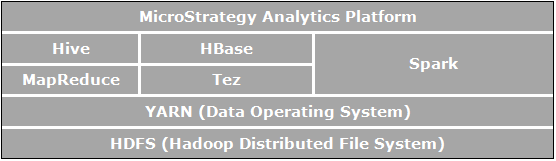
Os elementos diretamente relacionados a análises de negócios e relevantes para os casos de uso possibilitados pela MicroStrategy são:
- O HDFS (sistema de arquivos Hadoop distribuído) é o sistema de arquivos de armazenamento de dados usado por aplicativos Hadoop e que é executado em clusters de máquinas de consumo. Os clusters HDFS consistem em um NameNode que gerencia os metadados do sistema de arquivo e em DataNodes que armazenam os dados propriamente ditos. O HDFS permite o armazenamento de arquivos importados grandes provenientes de aplicativos fora do ecossistema Hadoop e também a preparação de arquivos importados para processamento por aplicativos Hadoop.
- O YARN (Yet Another Resource Negotiator) fornece gerenciamento de recursos e é uma plataforma central para distribuir operações, segurança e ferramentas de governança de dados entre clusters Hadoop para aplicativos em execução no Hadoop.
- O MapReduce é um ambiente de execução e modelo de processamento de dados distribuído que é executado em grandes clusters de máquinas de consumo. Ele usa o algoritmo MapReduce, que decompõe todas as operações em funções Map e/ou Reduce.
- O Tez é uma estrutura generalizada de programação de fluxo de dados que foi concebida para proporcionar melhor desempenho para fluxos de trabalho de consultas SQL em comparação com o MapReduce.
- O Hive é um data warehouse distribuído construído sobre o HDFS para gerenciar e organizar grandes quantidades de dados. O Hive fornece um repositório de dados esquematizado para o armazenamento de grandes quantidades de dados brutos e um ambiente ao estilo SQL para executar tarefas de análise e consulta em dados brutos no HDFS. O ambiente ao estilo SQL do Hive é a forma mais popular de consultar o Hadoop. Além disso, o Hive pode ser usado para canalizar consultas SQL para uma variedade de mecanismos de consulta, como o Map-Reduce, o Tez e o Spark, entre outros.
- O Spark é uma estrutura de computação em cluster. Ele fornece um modelo de programação simples e expressivo que é compatível com uma ampla gama de aplicações, incluindo ETL, aprendizagem de máquina, processamento de fluxos e computação gráfica.
- O HBase é um banco de dados distribuído orientado por colunas. Ele usa o HDFS para seu armazenamento subjacente e oferece suporte a cálculos ao estilo em lote usando consultas MapReduce e a consultas de ponto (leituras aleatórias) que são transacionais.
Conectando e analisando fontes de Big Data no MicroStrategy
O ecossistema do Big Data tem vários mecanismos SQL (Hive, Impala, Drill etc.) que permitem aos usuários transmitir consultas SQL para fontes de Big Data e analisar os dados como eles fariam com bancos de dados relacionais tradicionais. Dessa forma, os usuários podem tirar proveito da mesma estrutura analítica que eles utilizam ao acessarem dados estruturados via SQL.
O MicroStrategy é compatível e certifica a conectividade com vários mecanismos SQL de Big Data. De maneira semelhante aos bancos de dados tradicionais, a conectividade com esses mecanismos SQL é feita via drivers ODBC ou JDBC.
O MicroStrategy também oferece um método que permite aos usuários importar dados diretamente do sistema de arquivos Hadoop (HDFS). Isso é possível com o uso do MicroStrategy Hadoop Gateway, que permite aos clientes contornar os mecanismos de consulta SQL e carregar os dados diretamente do sistema de arquivos em cubos MicroStrategy na memória para análise.
O diagrama abaixo mostra as camadas através das quais os dados viajam para chegarem ao MicroStrategy a partir de sistemas Hadoop.
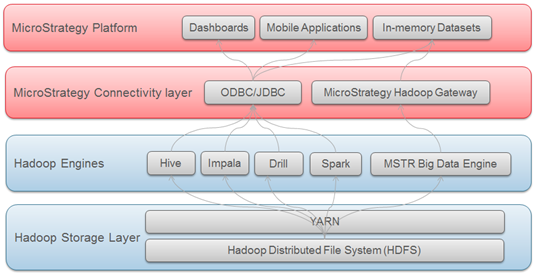
Selecionando o modo de acesso aos dados
O MicroStrategy permite que os usuários aproveitem eficientemente os recursos do sistema Big Data e do sistema de BI em conjunto para oferecer o melhor desempenho na execução de análises. Os usuários têm as seguintes opções:
- Trazer dados para a memória (abordagem na memória) - os dados para a análise são obtidos exclusivamente do cubo na memória. O MicroStrategy permite que os usuários extraiam subconjuntos de dados, que podem somar centenas de Gigabytes, de uma fonte de Big Data para um cubo na memória e gerem relatórios/dossiers a partir desse cubo. Normalmente, um cubo é configurado para publicação em intervalos regulares e é salvo na memória principal do servidor, eliminando a demorada necessidade de consultar o banco de dados Big Data.
- Acessar os dados diretamente de sua fonte (abordagem de conexão dinâmica) - os dados são acessados exclusivamente do banco de dados. O MicroStrategy oferece conectividade com várias fontes de Big Data para executar relatórios e dossiers de forma dinâmica com base na fonte.
- Adotar uma abordagem híbrida - os dados são obtidos do cubo na memória e do banco de dados, conforme necessário. A abordagem híbrida aproveita efetivamente o poder de ambos os métodos acima, permitindo ao usuário alternar facilmente entre eles dependendo da consulta enviada. O MicroStrategy tem uma tecnologia de fornecimento dinâmica que determina automaticamente se uma determinada consulta pode ser respondida por cubos ou pelo banco de dados e é capaz de canalizar essa consulta de acordo.
A figura a seguir resume as três abordagens:
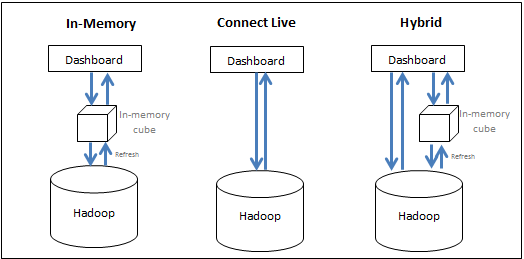
Embora a abordagem na memória produza geralmente o desempenho analítico mais rápido, ela pode não ser prática devido ao grande volume de dados. A seção a seguir discute considerações de design ao decidir como os dados devem ser acessados.
- Abordagem na memória: Essa abordagem fornece um desempenho mais rápido. No entanto, os dados estão limitados ao pequeno conjunto que cabe na memória principal e, dependendo de quantas vezes os dados na memória são atualizados, eles poderiam acabar ficando obsoletos. Use essa abordagem quando:
- Os dados finais estão em formato agregado e cabem na memória principal da máquina de BI
- O banco de dados é muito lento para análises interativas
- O usuário precisa remover a carga de um banco de dados transacional
- O usuário precisa estar offline
- A Segurança de Dados pode ser configurada no nível de BI
- Abordagem de Conexão Dinâmica: Em situações em que os dados do dossier precisam ser atuais, ou se os dados estão em um nível de detalhes em que nem todos os dados podem ser armazenados no cubo na memória, a geração de um dossier usando a opção de conexão dinâmica pode ser uma abordagem adequada. Isso permite que os dados mais recentes sejam buscados do warehouse após cada execução. Essa abordagem também é útil nos casos em que a segurança é configurada no nível do banco de dados e uma execução do warehouse é necessária para cada usuário para poder exibir os dados aos quais eles têm acesso. Use essa abordagem quando:
- O banco de dados é rápido e ágil
- O usuário acessa dados que muitas vezes são atualizados no banco de dados
- Os volumes de dados são maiores que o limite na memória
- Os usuários desejam uma distribuição programada de um dossier pré-executado
- A Segurança de Dados está configurada no nível do banco de dados
- Abordagem Híbrida: Essa abordagem é adequada para os casos de uso em que a tela splash do dossier contém um alto nível de informações agregadas nas quais os usuários podem iniciar detalhamentos. Nesses casos, os administradores podem publicar os dados agregados em um cubo na memória, para que a tela principal do dossier possa aparecer rapidamente e, em seguida, fazer com que o dossier acesse os dados de nível inferior no sistema Big Data quando o usuário fizer o detalhamento. A capacidade de fornecimento dinâmico no MicroStrategy facilita a criação de tais aplicativos, já que os relatórios selecionados podem ser transformados em cubos, e o MicroStrategy determina automaticamente se deve acessar esses cubos ou o banco de dados, dependendo dos dados que o usuário está solicitando.
Drivers e Fornecedores de Big Data com suporte
Os mecanismos SQL Hadoop são otimizados para manipulação de dados específicos. Com base no tipo de dados e nas consultas executadas para acessar esses dados, podemos dividir os casos de uso nos cinco grupos a seguir:
- SQL em lote – usado para realizar transformações em grande escala no Big Data
- SQL interativo - permite análises interativas no Big Data
- No-SQL – geralmente usado para armazenamento de dados em grande escala e rápidas consultas transacionais
- Dados não estruturados/mecanismo de pesquisa – análise de dados de texto ou dados de log, usando principalmente funcionalidades de pesquisa
- Limpeza e carregamento de dados na memória/Hadoop Gateway – otimizado e usado principalmente para a rápida publicação de cubos na memória
A figura a seguir mostra o mapeamento entre os casos de uso e os motores atualmente com suporte no MicroStrategy.
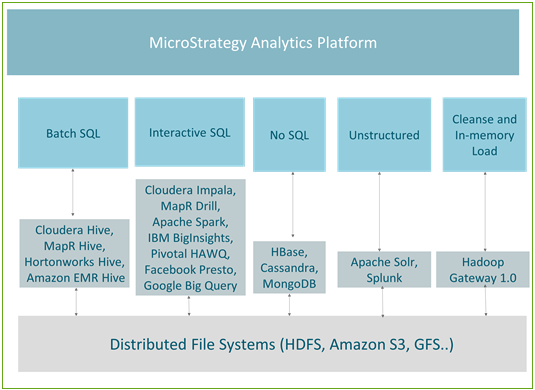
Processamento em lote
O Hive é o mecanismo de consulta mais popular para processamento em lote. Por ser tolerante a falhas, ele é recomendável para trabalhos do tipo ETL. Todas as principais distribuições Hadoop (como Hortonworks, Cloudera, MapR e Amazon EMR) oferecem conectores Hive ODBC. A MicroStrategy tem parcerias com todos os fornecedores Hadoop acima e oferece conectividade certificada com o Hadoop via Hive.
O Hive é um bom mecanismo para uso com a abordagem na memória no MicroStrategy ou como parte da abordagem de conexão dinâmica quando associado a serviços de distribuição, de modo que a latência do banco de dados não afete o usuário final. Como ele usa o MapReduce para processar suas consultas, o processamento em lote tem alta latência e não é adequado para consultas interativas.
A tabela a seguir lista as informações de conectividade para as distribuições do Hive com suporte.
| Fornecedor | Conectividade | Caso de uso | Nome do Driver | Fluxo de trabalho |
|---|---|---|---|---|
| Cloudera Hive | ODBC | Uma ferramenta que utiliza o SQL e o converte em MapReduce, podendo ser usada para realizar transações nos dados ao estilo de ETL em grande escala | MicroStrategy Hive ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Hortonworks Hive |
ODBC |
Uma ferramenta que utiliza o SQL e o converte em MapReduce, podendo ser usada para realizar transações nos dados ao estilo de ETL em grande escala | MicroStrategy Hive ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| MapR Hive | ODBC | Uma ferramenta que utiliza o SQL e o converte em MapReduce, podendo ser usada para realizar transações nos dados ao estilo de ETL em grande escala | MicroStrategy Hive ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Amazon EMR Hive | ODBC | Uma ferramenta que utiliza o SQL e o converte em MapReduce, podendo ser usada para realizar transações nos dados ao estilo de ETL em grande escala | MicroStrategy Hive ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
Consultas interativas
Vários fornecedores Hadoop desenvolveram mecanismos de rápida execução para permitir consultas interativas. Esses mecanismos usam mecanismos específicos de fornecedores/tecnologias para consultar o HDFS, mas ainda usam o Hive como um metastore. Todas essas tecnologias estão evoluindo em um rápido ritmo para fornecer tempos de resposta mais rápidos em grandes conjuntos de dados, bem como capacidades analíticas avançadas. Mecanismos interativos, como o Impala, o Drill ou o Spark, podem ser associados efetivamente com o MicroStrategy Dossier para possibilitar a descoberta de dados via autoatendimento no Hadoop. Os mecanismos são certificados para funcionamento com o MicroStrategy.
A tabela a seguir lista as informações de conectividade para as distribuições com suporte.
| Fornecedor | Conectividade | Caso de uso | Nome do Driver | Fluxo de trabalho |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Um mecanismo de consulta SQL de processamento maciçamente paralelo (MPP) de código-fonte aberto para dados armazenados em um cluster de computador que executa o Apache Hadoop. O Impala usa seu próprio mecanismo de processamento e pode realizar operações na memória | MicroStrategy Impala ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Apache Drill | ODBC | Um mecanismo de consulta de baixa latência de código-fonte aberto com suporte pelo MapR. Ele tem a capacidade de descobrir esquemas dinamicamente para ser capaz de oferecer recursos de exploração de dados de autoatendimento | MicroStrategy Drill ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Apache Spark | ODBC | Uma ferramenta de processamento de dados que opera em coleções de dados distribuídas e é desenvolvida por uma das maiores comunidades de código-fonte aberto. Com seu processamento em memória, o Spark é em ordem de grandeza mais rápido do que o MapReduce | MicroStrategy ODBC Driver for Apache Spark SQL | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| IBM BigInsights | ODBC | Um rico conjunto de avançados recursos de análise que permite às empresas analisar grandes volumes de dados estruturados e não estruturados em seu formato nativo no Hadoop | BigInsights ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Pivotal HAWQ | ODBC | Um mecanismo paralelo de consulta SQL que lê e grava dados no HDFS nativamente. Ele fornece aos usuários uma interface padrão ANSI completa e compatível com SQL | MicroStrategy ODBC Driver for Greenplum Wire Protocol | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
| Google BigQuery | ODBC | Um serviço baseado na nuvem que aproveita a infraestrutura do Google para permitir que os usuários consultem petabytes de dados interativamente | MicroStrategy Google BigQuery ODBC Driver | Com suporte no MicroStrategy Architect e no MicroStrategy Data Import |
Fontes NoSQL
Fontes NoSQL são otimizadas para grandes consultas transacionais e de armazenamento de informações. Elas podem ser associadas de forma eficaz com a Opção de várias origens ou com a opção de mesclagem de dados no MicroStrategy, de modo que os usuários possam visualizar informações de nível superior de bancos de dados tradicionais e usar a fonte No-SQL para fornecer a capacidade de detalhar até os dados de transação de nível mais baixo por meio da integração com fontes NoSQL.
A tabela a seguir lista as fontes NoSQL para as quais a MicroStrategy oferece conectividade certificada.
| Fornecedor | Conectividade | Caso de uso | Nome do Driver | Fluxo de trabalho |
|---|---|---|---|---|
| Apache Cassandra | JDBC | Um repositório de chaves/valores, todos os dados consistem em uma chave e um valor indexados | Cassandra JDBC Driver | Com suporte no MicroStrategy Data Import |
| HBase | JDBC | Um banco de dados NoSQL de repositório de colunas que, em vez de armazenar dados em linhas, armazena-os em tabelas como seções de colunas de dados. Oferece alto desempenho e uma arquitetura escalável | Phoenix JDBC Driver | Com suporte no MicroStrategy Data Import |
| MongoDB | ODBC | Um banco de dados orientado a documentos que evita a tradicional estrutura de banco de dados relacional com base em tabela, tornando a integração de dados em determinados tipos de aplicativos mais fácil e rápida | MicroStrategy MongoDB ODBC Driver | Com suporte no MicroStrategy Data Import |
Dados não estruturados/Mecanismos de Pesquisa
Mecanismos de pesquisa são ferramentas eficazes que permitem aos usuários pesquisar em grandes volumes de dados de texto e adicionar contexto aos dados em seus dossiers. Esse recurso é poderoso quando aproveitado com mesclagem de dados no MicroStrategy, permitindo que os dados de pesquisa sejam associados a fontes empresariais tradicionais.
A tabela a seguir lista as informações de conectividade para as distribuições do Hive com suporte.
| Fornecedor | Conectividade | Caso de uso | Nome do Driver | Fluxo de trabalho |
|---|---|---|---|---|
| Apache Solr | Nativo | O mecanismo de pesquisa de código-fonte aberto mais popular, que permite pesquisa de texto completo, pesquisas facetadas e indexação em tempo real. A MicroStrategy desenvolveu um conector para integração com o Solr. Ele fornece a capacidade de realizar pesquisas dinâmicas e de analisar e visualizar os dados indexados do Solr | integrado | Com suporte no MicroStrategy Data Import |
| Splunk Enterprise | ODBC | Um mecanismo de pesquisa proprietário amplamente utilizado | Splunk ODBC Driver | Com suporte no MicroStrategy Data Import |
MicroStrategy Hadoop Gateway
A MicroStrategy oferece uma conectividade nativa com o HDFS usando um Hadoop Gateway. O Hadoop Gateway contorna o Hive, acessando os dados diretamente do HDFS. O Hadoop Gateway é uma instalação à parte em nós HDFS.
O Hadoop Gateway foi projetado para otimizar um caso de uso de criação de grande cubos na memória durante a conexão com o Hadoop. Ele emprega as seguintes técnicas para obter uma eficiente importação de dados em lote do Hadoop:
- Contorna o Hive para acessar dados diretamente: Comunica-se nativamente com o HDFS em execução como um aplicativo Yarn que contorna o Hive/ODBC. Isso reduz ainda mais a consulta de dados e o tempo de acesso.
- Carregamento paralelo de dados do HDFS: Carrega dados no MicroStrategy Intelligence Server por meio de segmentos paralelos, produzindo uma taxa de transferência maior e reduzindo o tempo de carregamento.
- Permite a limpeza de dados descendente para casos de uso na memória: Operações de transformação de dados são realizadas no Hadoop, possibilitando a transformação em escala.
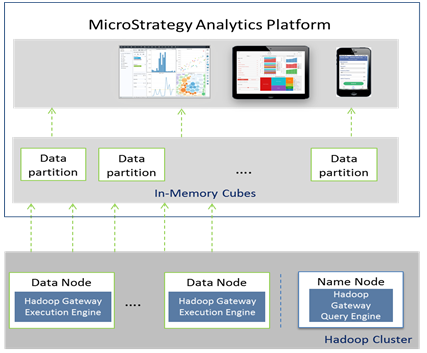
Visão geral da arquitetura do Hadoop Gateway
- O Hadoop Gateway é uma instalação à parte patenteada da MicroStrategy, que deve ser feita em nós de nomes e dados HDFS por meio da instalação dos seguintes componentes:
- Hadoop Gateway Query Engine no Nó de Nomes HDFS
- Hadoop Gateway Execution Engine no HDFS Execution Engine
- O MicroStrategy Intelligence Server envia a consulta ao Hadoop Gateway Execution Engine. Em seguida, a consulta é analisada e enviada aos nós de dados para processamento. Os dados buscados para a consulta são então extraídos dos nós de dados para o MicroStrategy Intelligence Server em threads paralelos para publicação em cubos na memória.
A figura a seguir mostra o MicroStrategy Hadoop Gateway em um diagrama de arquitetura.
Limitações do Hadoop Gateway
Atualmente, o Hadoop Gateway tem algumas limitações:
- Apenas há suporte para arquivos de texto e csv
- A transformação de dados apenas tem suporte no caso de uso na memória
- Não há suporte para a importação de dados de várias tabelas
- Para recursos analíticos, apenas há suporte para agregação e filtragem. Não há suporte para a operação JOIN
- Não há suporte para a segurança Kerberos com um usuário de serviços compartilhados vs. delegação para usuários específicos
Exemplos de fluxos de trabalho para conexão com fontes de Big Data
Esta seção contém exemplos de diferentes fluxos de trabalho para conexão com fontes de Big Data da MicroStrategy:
- Para conectar-se via Web Data Import ao Hortonworks Hive
- Para conectar-se via Web Data Import ao Hortonworks Hive
- Para conectar-se via Hadoop Gateway
Conectando-se via Developer ao Hortonworks Hive
Os administradores/desenvolvedores de Business Intelligence podem usar o MicroStrategy Developer para se conectarem a uma fonte de Big Data usando as etapas mencionadas abaixo. O fluxo de trabalho é semelhante ao de integração dos bancos de dados tradicionais com a MicroStrategy. As etapas podem ser divididas em três áreas conceituais:
- Criação de uma conexão com a fonte da MicroStrategy. Isso inclui criar uma fonte de dados ODBC com os detalhes de conectividade apropriados e criar um objeto de Instância de Banco de Dados que aponte para essa fonte ODBC.
- Importação das tabelas da origem por meio da interface do Catálogo do Warehouse.
- Criação dos objetos de esquema necessários (como atributos, fatos etc.) para a geração de relatórios e dossiers.
Nas etapas abaixo, o Hortonworks Hive é mostrado como exemplo.
Para criar uma conexão com a fonte do MicroStrategy.
-
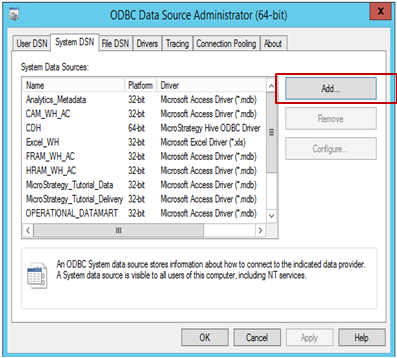
Abra o Administrador de Origem de Dados ODBC para criar uma conexão de fonte de dados com a origem. Clique em Adicionar para criar uma nova conexão.
-
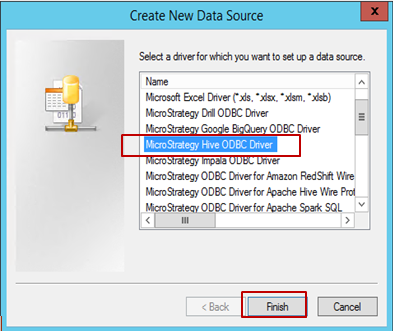
Selecione o driver (neste exemplo, Hive ODBC está selecionado) e clique em Concluir.
-
Preencha os detalhes de conectividade apropriados:
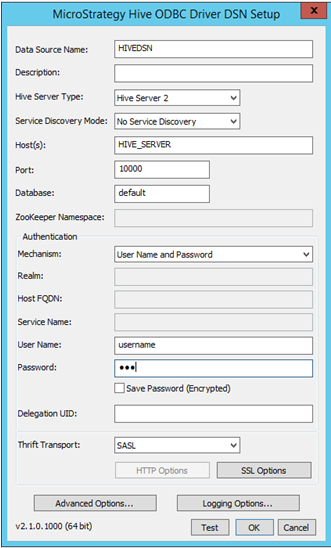
- Nome da Fonte de Dados: Nome usado para salvar a conexão
- Descrição: Opcional
- Tipo do Servidor Hive: Selecionar o servidor com base no ambiente
-
Modo de Descoberta de Serviço: Existem dois modos de descoberta de serviço que podem ser usados, conforme mostrado abaixo. Quando o usuário seleciona "Zookeeper", o MicroStrategy permite inserir o Namespace do Zookeeper, conforme mostrado abaixo.
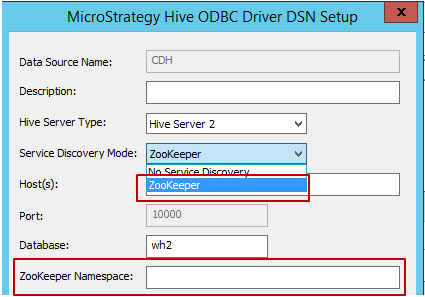
- Host, Porta e Nome do Banco de Dados: Campos necessários, preencha de acordo com o ambiente.
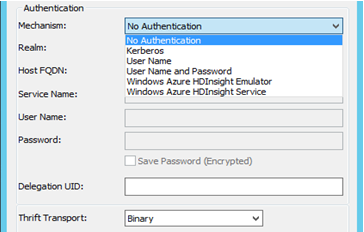
- Autenticação: O MicroStrategy certifica diferentes mecanismos de autenticação para o Hortonworks Hive: Sem autenticação, Kerberos, Nome de usuário, Nome de usuário e senha. Com base na seleção do Mecanismo, o Parâmetro de Transporte Thrift mudará. Da seguinte maneira:
- Para Sem autenticação - o Parâmetro de Transporte Thrift é "Binário"
- Para Kerberos - o Parâmetro de Transporte Thrift é "SASL"
Nome de usuário, Nome de Usuário e Senha - o Parâmetro de Transporte Thrift é "SASL"
- Após a seleção e o preenchimento dos detalhes da conexão, esta pode ser testado com o uso do botão "Testar".
-
Abra o MicroStrategy Developer. Faça login no Projeto -> Acesse Gerenciador de Configuração -> Instâncias de Banco de Dados -> Criar uma Nova Instância de Banco de Dados.
Se você estiver executando o MicroStrategy Developer no Windows pela primeira vez, execute-o como administrador.
Clique com o botão direito no ícone do programa e selecione Executar como administrador.
Isso é necessário para definir corretamente as chaves de registro do Windows. Para obter mais informações, consulte KB43491.
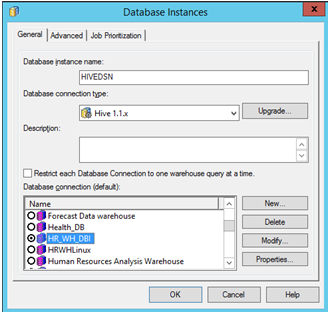
Selecione o "Nome da Fonte de Dados" criado anteriormente para a origem. Preencha as informações necessárias de nome de usuário e senha.
-
Importe Tabelas da origem: Acesse Esquema -> Catálogo do Warehouse -> Selecione a Instância de Banco de Dados -> Arraste e solte as tabelas necessárias da origem.
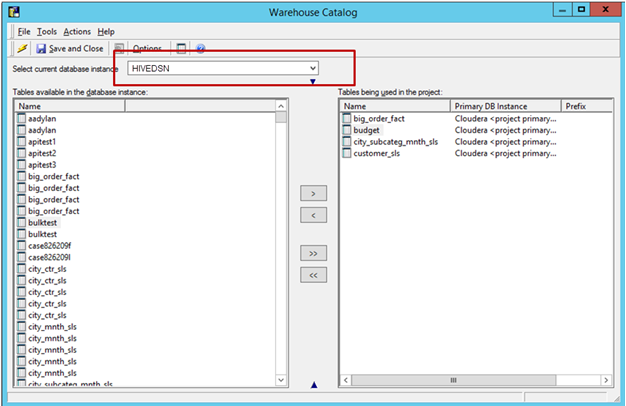
Salve e feche o catálogo.
-
Arraste atributos e métricas conforme necessário. Inicie um novo Relatório do MicroStrategy para gerar sua análise.
Para conectar-se via Web Data Import ao Hortonworks Hive
Os analistas de negócios e usuários finais podem tirar proveito do fluxo de trabalho de Importação de Dados do MicroStrategy Web para se conectarem e analisarem dados exatamente como fariam com fontes de dados relacionais. Ele pode ser dividido em três áreas conceituais: Conectar, Importar e Analisar.
Veja abaixo a janela da conectividade de Importação de Dados do MicroStrategy Web, estabelecendo uma conexão com o Hortonworks Hive.
-
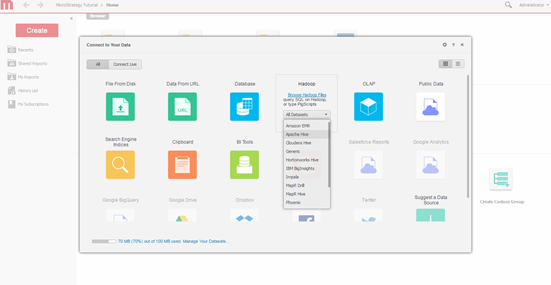
Selecione Mecanismo de Consulta. Selecione o mecanismo para conexão na tela de importação de dados do MicroStrategy.
-
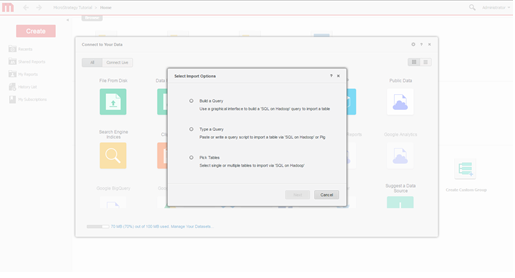
Selecionar Opções de Importação. Selecione se deseja criar uma consulta, digitar uma consulta ou escolher tabelas. A abordagem de seleção de tabelas é recomendada porque oferece o melhor uso dos recursos de modelagem do MicroStrategy.
-
Crie a conexão. Defina uma nova conexão com o sistema Hadoop.
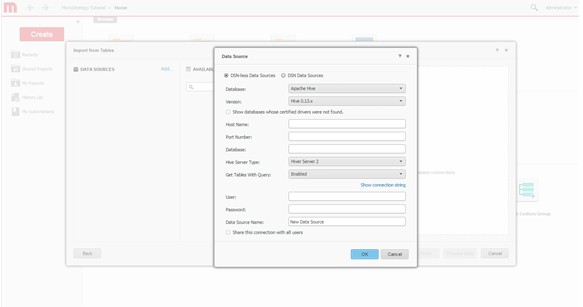
-
Selecione tabelas. Selecione tabelas das quais os dados serão acessados.
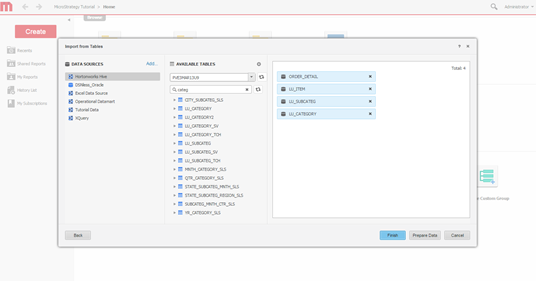
-
Modele os dados. Como opção, modele as tabelas, altere o nome dos atributos e das métricas, exclua colunas da importação etc.
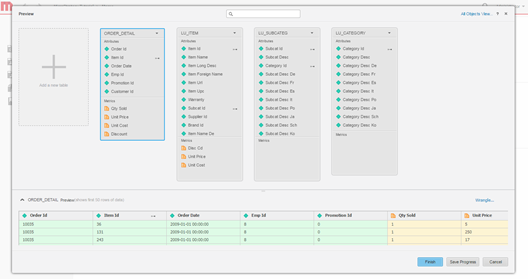
-
Defina o modo de acesso aos dados. Escolha se deseja publicar os dados como um cubo na memória ou por meio do modo de conexão dinâmica.
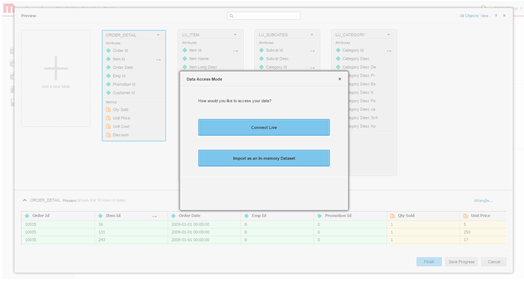
- Crie o dossier.
Para conectar-se via Hadoop Gateway
O Hadoop Gateway pode ser aproveitado na Importação de Dados do MicroStrategy Web, seguindo o típico fluxo de trabalho de importação de dados:
- Criar uma conexão com o cluster Hadoop/HDFS
- Procurar e importar pastas do HDFS
- Limpar os dados (opcional)
- Publicar os dados como um cubo na memória no MicroStrategy Intelligence Server e analisar os dados em um dossier
Veja a seguir os detalhes de cada uma das etapas.
-
Crie a conexão.
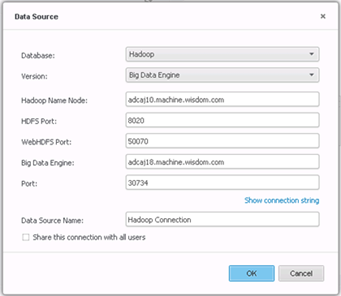
-
Selecione os dados a serem importados.
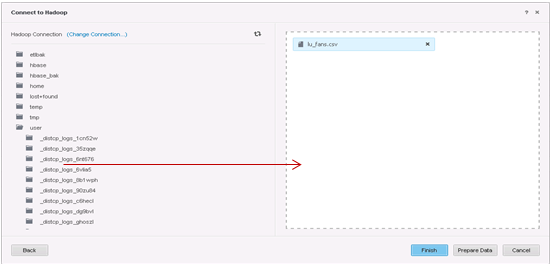
-
Prepare os dados usando o Transformador de Dados.
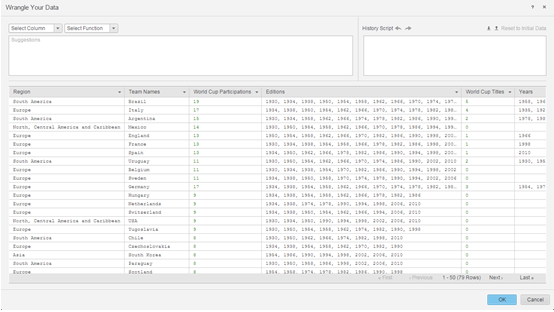
- As próximas etapas compreendem publicar os cubos na memória no Microstrategy Intelligence Server e usar a interface da Percepção Visual para construir um dossier.