Version 2021
MicroStrategy でのビッグデータの分析
Business Intelligence や分析業界では、ビッグデータは主に、従来のシステムでは処理できない膨大なデータの消費と関係しています。ビッグデータでは、大量のデータ セットを保存、処理、検索、分析、視覚化する新しいテクノロジーが必要です。
詳細は、次のトピックを参照してください。
新規ユーザー: 概要 - ビッグデータの一般的な紹介を提供します
経験のあるユーザー:
- MicroStrategy でのビッグデータ ソースの接続と分析 - MicroStrategy を使用してビッグデータ ソースに接続する方法について説明します
- ビッグデータ ソースへの接続のワークフロー例 – 接続構成例を示します
ビッグデータの概要
このセクションはビッグデータに対する一般的な導入であり、用語や最も一般的な使用事例をまとめます。次のトピックについて説明します。
ビッグデータの使用事例
ビッグデータ テクノロジーを使用することで、膨大なデータや複雑な分析によってこれまで実現できなかった使用事例が可能になりました。現在、ビッグデータ内に閉じ込められた情報やインサイトを利用することは、あらゆるビジネス タイプに役立ちます。
- 小売業者は、顧客の購入傾向、現在の製品、価格設定、およびプロモーションに関する情報と関連付けることによって、パーソナライズされたより優れた顧客サービスを提供したいと願っています。MicroStrategy でビッグデータ分析を実行することで、店舗担当者がパーソナライズされた、関連性のある顧客体験を提供する野に役立ちます。
- メーカーは効率性の向上、低い価格、およびサービス レベルの維持に対する需要に常に直面しています。これにより、サプライ チェーン全体でコストを削減価格を下げることを強いられています。また、消費者の人口統計および購入傾向に関連して製品の売り上げを調査し、消費分析を行う必要があります。メーカーは MicroStrategy を使用することで、分散されたソースでのビッグデータ分析を実施し、完全な注文率や品質を達成し、詳しい消費パターンを把握することができます。
- 通信会社は、トラフィックや位置データとともに、相関ネットワーク使用率、サブスクライバーの密度によってネットワーク容量を計画および最適化する必要があります。通信会社は MicroStrategy を使用することでネットワーク容量を正確に関しおよび予測し、停電の可能性に対する計画を効果的に行い、プロモーションを実行することができます。
- 医療ケアは医薬品の売上や患者分析を改善し、支払者のためのより良いソリューションを実現するため、組織が所有するペタバイト単位の患者データの使用を目指しています。MicroStrategy はこれらの使用事例を満たすのに役立つアプリケーションを効果的に構築し、実行できます。
- 政府はセキュリティの脅威、人口動態、予算策定、およびその他の大規模なオペレーションの中での財務に対処しています。大きく複雑なデータセットにおける MicroStrategy の分析機能は、政府担当者は深い洞察を得ることで、情報に基づいた政策決定を行い、無駄や不正をなくし、市民の詳細のニーズに合わせて計画することができます。
ビッグデータの特徴
ビッグデータは新しい課題をもたらし、課題に対処するための新しいアプローチが必要となります。企業がビッグデータの使用事例を有効にするよう計画する場合は、ビッグデータの 5 つの V 、つまりデータ量 (Volume)、多様性 (Variety)、スピード (Velocity)、変動制 (Variability)、および 価値 (Value) を考慮する必要があります。
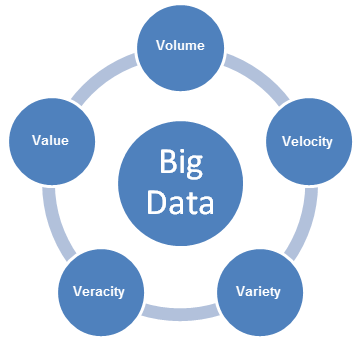
- データ量は、分析が必要な、生成されたデータ コンテンツのサイズを表します。
- スピードは、新しいデータが生成される速度と、データが移動する速度を表します。
- 多様性は、分析可能なデータのタイプを表します。これまで、分析業界はテーブルや列に収まる構造化データに焦点を当てていました。これらのデータは一般的に、リレーショナル データベースに保存されていました。けれども、世界のデータの大部分は現在構造化されておらず、簡単にテーブルに配置することはできません。より広いレベルでは、データは次の 3 つのカテゴリーに分類できます。それぞれに対して、異なるデータ分析アプローチが必要です。
- 構造化データは、構造が判明しているデータです。データはファイルまたはレコードないの固定フィールド内に格納されます。
- 非構造化データは、定義されたデータモデルや組織を持たない情報です。データはテキスト (電子メールの本文、インスタント メッセージ、Word ドキュメント、PowerPoint プレゼンテーション、PDF)、テキスト以外 (音声、ビデオ、イメージ ファイル) を使用できます。
- 半構造化データは、構造化データと非構造化データの中間です。データは厳密なデータ モデル (イベント ログ データやキー値の文字列のペアなど) を使用せずに構造化されます。
- 正確性は、データの信頼性を表します。ビッグデータの多くのソースや形式を使用することで、品質や正確性を制御しにくくなります。
- 価値は、意味のある出力を生み出すためにアクセスや分析が必要な、明確なビジネスの価値へビッグデータを変える機能を表します。
ビッグデータを採用する際の課題
企業がビッグデータ システム内に存在する情報を発掘するためのソリューションを開発する際、次の課題に直面します。
- [パフォーマンス]: 組織は、対話型パフォーマンスを達成するため、ビッグデータに関する高度な分析を実施しようとしています。
- データ連携: 現実世界では、プロジェクト間でデータを統合する必要があります。分散された形式で、異なるソースに保存されているデータを連携するのは困難です。
- データ クレンジング: 企業は、分析の準備をするため、さまざまな形式のデータのクレンジングを行うことが困難だと感じています。
- セキュリティ: 暗号化の適切な仕様、データ アクセス履歴の記録、さまざまな業界標準認証メカニズムを通じたデータへのアクセスなど、膨大なデータ レイクを安全に保つことは困難です。
- 効率を上げる: 企業はデータから価値を解放するためにかかる時間を短縮しようとしています。様々な種類のデータに対して多数のソースを処理し、それを行うためにポイント ソリューションのウェブを使用すると、多くの場合は時間がかかります。
Hadoop コンポーネントの概要
このセクションでは、Hadoop エコシステムのメイン コンポーネントについて説明します。
Apache Hadoop は、分散型ストレージおよび分散プロセス用のオープン ソースのソフトウェア フレームワークです。組織はこれを使用することで従来のデータベースよりけた違いに大きなデータを、コスト効率の良い、クラスター化環境で保存してクエリできます。以下の図は、Apache Hadoop コンポーネントのアーキテクチャ図を示します。
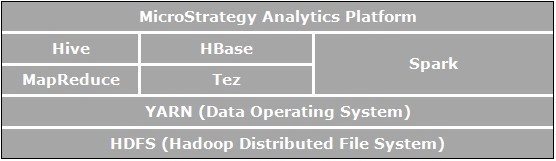
ビジネス分析に直接関係し、MicroStrategy によって実現する使用事例に関係するエレメントは次のとおりです。
- HDFS (Hadoop Distributed File System) は市販マシンのクラスター上上で実行する、Hadoop アプリケーションによって使用されるデータ ストレージ ファイル システムです。HDFS クラスターは、ファイル システム メタデータおよび実際のデータを保存する DataNode を管理する NameNode で構成されます。HDFS では、Hadoop エコシステム外のアプリケーションからインポートされた大きなファイルのストレージや、Hadoop アプリケーションで処理するインポートされたファイルのステージングが可能です。
- YARN (Yet Another Resource Negotiator) はリソース管理を提供し、Hadoop を実行するアプリケーション用に Hadoop クラスター全体でオペレーション、セキュリティ、データ管理ツールを提供する一元的なプラットフォームです。
- MapReduce は、市販のマシンの大規模なクラスター上で実行する、分散型データ処理モデルおよび実行環境です。すべてのオペレーションをマップに分割し、関数を削減する MapReduce アルゴリズムを使用しています。
- Tez は MapReduce と比較して SQL クエリ ワークフローのパフォーマンスを改善するよう設計された、汎用データ フロー プログラミング フレームワークです。
- Hive は大量のデータを管理および整理するため、HDFS の上に構築されれた分散型データ ウェアハウスです。Hive は HDFS 内の未加工のデータでタスクの分析やクエリを実行するため、大量の未加工データや SQL に似た環境を格納する、図式化されたデータ ストアを提供します。SQL のような Hive の環境は、Hadoop をクエリする最も人気の方法です。さらに、Hive は Map-Reduce、Tez、Spark などのさまざまなクエリ エンジンに SQL クエリをチャネルするために使用できます。
- Spark はクラスター コンピューティング フレームワークです。ETL 機械学習、ストリーム プロセス、およびグラフ計算など、幅広いアプリケーションをサポートするシンプルで表現の豊かなプログラミング モデルを提供します。
- Hbase は分散型の、列指向データベースです。参照元ストレージとして HDFS を使用し、MapReduce を使用したバッチ スタイルの計算と、トランザクショナルなポイント クエリ (ランダム読み取り) の両方をサポートします。
MicroStrategy でのビッグデータ ソースの接続と分析
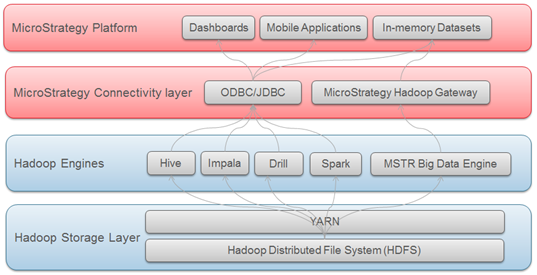
ビッグデータ エコシステムは、ユーザーが SQL クエリをビッグデータ ソースに送ることができる多数の SQL エンジン (Hive、Impala、Drill、など) を搭載し、従来のリレーショナル データベースのようにデータを分析します。そのため、ユーザーは、SQL 経由で構造化データにアクセスする場合と同じ分析フレームワークを活用することができます。
MicroStrategy は複数の Big Data SQL エンジンとの属性をサポートし、認証します。祷頼のデータベースと同様に、これらの SQL エンジンへの接続は ODBC または JDBC ドライバーを経由しまです。
MicroStrategy は、ユーザーに Hadoop ファイル システム(HDFS) から直接データのインポートを許可するメソッドを提供します。これは MicroStrategy Hadoop Gateway によって達成されます。クライアントは MicroStrategy Hadoop Gateway を使用することで、SQL クエリ エンジンを渡し、分析を行うため、ファイル システムから MicroStrategy のインメモリ キューブに直接データを読み込むことができます。
以下の図は、Hadoop システムから MicroStrategy に到達するため、データが通過するレイヤーを示しています。
データ アクセス モードの選択
MicroStrategy を使用することで、ユーザーはビッグデータ システムと BI システムのリソースを連動して効率的に活用し、分析を実行するための最善のパフォーマンスを提供できます。ユーザーには下記のオプションがあります。
- データをメモリに取り込む (インメモリ アプローチ) - 分析用のデータはインメモリ キューブからのみ取得されます。MicroStrategy では、ユーザーはビッグデータ ソースから最大数百ギガバイトのデータのサブセットをメモリ キューブに取り込み、キューブからレポート/dossier を構築できます。一般的に、キューブは定期的な感覚で公開されるよう設定されており、サーバーのメイン メモリに保存され、ビッグデータ データベースのクエリに必要な時間をなくします。
- ソースから直接データにアクセス (ライブ接続アプローチ) - データはデータベースからのみアクセスされます。MicroStrategy はさまざまなビッグデータ ソースへの接続を提供し、ソースに対して動的にレポートや dossier を実行します。
- ハイブリッド アプローチの適用 - データは必要に応じて、インメモリ キューブとデータベースから取得されます。ハイブリッド アプローチでは、ユーザーは、自分たちが送信したクエリに応じてそれらをシームレスに切り替えることができ、上記の両メソッドの力を効果的に活用します。MicroStrategy はキューブとデータベースのどちらで特定のクエリに回答できるかを自動的に決定する動的なソーシング テクノロジーを搭載しているため、それに従ってクエリを導くことができます。
次の図は、3 つのアプローチをまとめたものです。
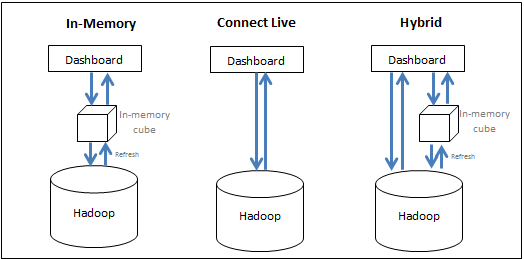
インメモリ アプローチは一般的に最も速い分析パフォーマンスを生み出しますが、膨大な量のデータによって実用的でない場合があります。次のセクションでは、データへのアクセス方法を決定する際のデザインの考慮事項について説明します。
- インメモリ アプローチ: このアプローチはより早いパフォーマンスを提供しますが、データはメイン メモリに収まることのできる小さなセットに制限され、インメモリ データを更新する頻度に応じて、データ クラウドが古くなっている可能性があります。このアプローチは、次のような場合に使用します。
- 最終的なデータは凝集型で、BI マシンのメイン メモリに適合させることができます。
- 対話型分析を使用するにはデータベースが遅すぎる
- ユーザーはトランザクション データベースの負荷を軽減する必要があります
- ユーザーがオフラインになる必要がある
- データ セキュリティを BI レベルで設定できる
- ライブ接続アプローチ: dossier のデータが最新である必要がある状況や、すべてのデータをインメモリ キューブに保存できない詳細レベルのデータの場合、ライブ接続オプションを使用して dossier を構築するアプローチが適しています。これにより、実行の度にウェアハウスから最後のデータをフェッチすることができます。このアプローチは、セキュリティがデータベース レベルで設定されていて、各ユーザーがアクセス権を持つデータを表示するためにウェアハウス実行が必要な場合に適しています。このアプローチは、次のような場合に使用します。
- データベースが高速で応答性がある
- ユーザーは、データベース内で頻繁に更新されるデータにアクセスする
- データ量がインメモリの制限を超えている
- ユーザーは事前に実行された dossier のスケジュールに基づいた配信を希望する
- データ セキュリティはデータベース レベルで設定される
- ハイブリッド アプローチ: このアプローチは、dossier のスプラッシュ スクリーンに、ユーザーが詳細にドリルできる高度な集約情報を含む使用事例に適しています。このような場合、アドミニストレーターは、dossier のメイン画面が素早く表示され、ユーザーがドリルダウンしたときに dossier がビッグデータ システム内の下位レベルのデータへ進ことができるよう、集計されたデータをインメモリ キューブに公開することができます。MicroStrategy の動的なソーシング機能を使用することで、これらのアプリケーションの構築は、選択したレポートをキューブに変えるときのように容易になります。MicroStrategy はユーザーが要求するデータに応じて、キューブまたはデータベースのどちらを使用するかを自動的に判断します。
サポートされるビッグデータ ドライバーとベンダー
Hadoop SQL エンジンは特定のデータ操作用に最適化されています。データにアクセスするために実行されるデータ型とクエリに基づいて、使用事例を次の 5 つのグループに分割できます。
- バッチ SQL - ビッグデータ上の大規模な変換の実行に使用します
- 対話型 SQL - ビッグデータにおける対話型分析を有効にします
- No-SQL - 一般的に、大規模なデータ ストレージや素早いトランザクション クエリに使用されます
- 非構造データ / 検索エンジン – 主に検索機能を使用してテキスト データまたはログ データを分析します
- メモリ / Hadoop Gateway へのデータのクレンジングと読み込み – 主にインメモリ キューブの公開を素早く行うよう最適化およびし使用されます
次の図は、MicroStrategy で現在サポートされている使用事例とエンジンの間のマッピングを示します。
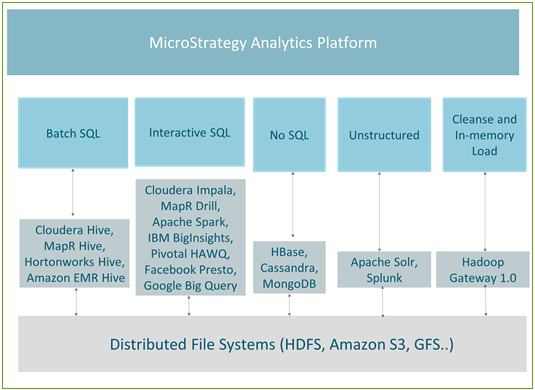
バッチ処理
Hive は、バッチ処理のための最も人気のあるクエリ メカニズムです。フォールト トレラントなため、ETL タイプのジョブに推奨されます。大手の Hadoop ディストリビューターはすべて (Hortonworks、Cloudera、MapR および Amazon EMR など)、Hive ODBC コネクターを提供します。MicroStrategy は上記のすべての Hadoop ベンダーと提携し、Hive 経由で Hadoop への認証接続を提供します。
Hive は、データベースのレイテンシがエンドユーザーに影響しないよう、ディストリビューション サービスと組み合わせたときに、MicroStrategy 内のインメモリ アプローチと共に使用したり、ライブ接続アプローチとして使用するのに優れたエンジンです。MapReduce を使用してクエリを処理していますが、バッチ処理は高レイテンシであり、対話型クエリには適していません。
次のテーブルは、サポートされる Hive ディストリビューションの接続情報をリストします。
| ベンダー | 接続 | 使用事例 | ドライバ名 | ワークフロー |
|---|---|---|---|---|
| Cloudera Hive | ODBC | SQL を取得して Map Reduce に変換し、データにおいて大規模な ETL のような変換を実行するために使用できるツール | MicroStrategy Hive ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Hortonworks Hive |
ODBC |
SQL を取得して Map Reduce に変換し、データにおいて大規模な ETL のような変換を実行するために使用できるツール | MicroStrategy Hive ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| MapR Hive | ODBC | SQL を取得して Map Reduce に変換し、データにおいて大規模な ETL のような変換を実行するために使用できるツール | MicroStrategy Hive ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Amazon EMR Hive | ODBC | SQL を取得して Map Reduce に変換し、データにおいて大規模な ETL のような変換を実行するために使用できるツール | MicroStrategy Hive ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
対話型クエリ
Several Hadoop ベンダーは、対話型クエリを実現するため、素早く実行するエンジンを開発しました。これらのエンジンはベンダー/テクノロジー固有のメカにズムを使用して HDFS のクエリを行っていますが、メタストアとして Hive を使用しています。これらのテクノロジーすべては、大きなデータセットでの応答時間の短縮と高度な分析機能を組み合わせて提供するよう、急速に進化しています。Impala、Drill、Spark などの対話型エンジンを、MicroStrategy ドシエ と効果的に組み合わせることで、Hadoop でのセルフサービスのデータ検出が可能となります。エンジンは、MicroStrategy との併用が認定されています。
次のテーブルは、サポートされるディストリビューションの接続情報をリストします。
| ベンダー | 接続 | 使用事例 | ドライバ名 | ワークフロー |
|---|---|---|---|---|
| Cloudera Impala | ODBC | An open source massively parallel processing (MPP) SQL query Apache Hadoop を実行するコンピューター クラスター内に保存されるデータ用の、オープン ソースの超並列 (MPP) SQL クエリ エンジン。Impala は独自の処理エンジンを使用し、インメモリ オペレーションを実行できます | MicroStrategy Impala ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Apache Drill | ODBC | MapR によってサポートされる、オープンソースの低レイテンシ クエリ エンジン。セルフサービスのデータ探索、機能を提供できるよう、スキーマをオンザフライで検出機能を搭載しています | MicroStrategy Drill ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Apache Spark | ODBC | 分散型データ コレクションで動作するデータ処理ツールであり、最大のオープン ソース コミュニティの 1 つとして開発されました。Spark はインメモリ処理により、MapReduce よりもはるかに高速です | Apache Spark SQL 向け MicroStrategy ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| IBM BigInsights | ODBC | 企業が Hadoop のネイティブ形式で膨大な量の構造化データおよび非構造化データを分析できる、高度な分析機能の豊富なセット | BigInsights ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Pivotal HAWQ | ODBC | HDFS へネイティブにデータを読み書きするパラレル SQL クエリ エンジン。ユーザーに完全な ANSI 規格準拠 SQL インターフェースを提供します | MicroStrategy ODBC Driver for Informix Wire Protocol | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
| Google BigQuery | ODBC | ユーザーがペタバイトのデータをインタラクティブにクエリできるよう、Google のインターフェイスを活用するクラウド ベースのサービス。 | MicroStrategy Google BigQuery ODBC ドライバー | MicroStrategy Architect および MicroStrategy データ インポートを通じてサポートされます |
NoSQL ソース
No SQL ソースは、大きな情報ストレージおよびトランザクション クエリ用に最適化されています。これらは、マルチソース オプションまたはデータ ブレンドオプションで効果的にペアリングできます。それにより、ユーザーが従来のデータベースから高度な情報を表示したり、No-SQL ソースを使用し、NoSQL ソースとの統合を通じて最下位レベルのトランザクション データへのドリルダウン機能を提供できます。
次の表は、MicroStrategy が接続を認証した NoSQL ソースをリストしています。
| ベンダー | 接続 | 使用事例 | ドライバ名 | ワークフロー |
|---|---|---|---|---|
| Apache Cassandra | JDBC | key-value ストア。すべてのデータがインデックス付きのキーと値で構成されます | Cassandra JDBC ドライバー | MicroStrategy データ インポートを通じてサポートされます |
| HBase | JDBC | データを行に保存する代わりに、データの列のセクションとしてテーブルにデータを保存する、カラムストア NoSQL データベース。高性能でスケーラブルなアーキテクチャを提供します | Phoenix JDBC ドライバー | MicroStrategy データ インポートを通じてサポートされます |
| MongoDB | ODBC | 従来のテーブル ベースのリレーショナル データべース構造を回避し、特定のタイプのアプリケーションの統合を簡単かつ素早く行えるようにするドキュメント指向データベース | MicroStrategy MongoDB ODBC ドライバー | MicroStrategy データ インポートを通じてサポートされます |
非構造データ/検索エンジン
検索エンジンは、膨大な量のテキスト データから検索し、dossier 内のデータへコンテキストを追加できる、効果的なツールです。この機能は、MicroStrategy でデータ ブレンドと併用に活用した場合に強力となり、検索データを従来のエンタープライズ ソースとペアリングすることができます。
次のテーブルは、サポートされる Hive ディストリビューションの接続情報をリストします。
| ベンダー | 接続 | 使用事例 | ドライバ名 | ワークフロー |
|---|---|---|---|---|
| Apache Solr | ネイティブ | 完全なテキスト検索、ファセット検索およびリアルタイム インデックス作成を許可する、最も人気のあるオープン ソースの検索エンジン。MicroStrategy は、Solr と統合するためのコネクターを構築してきました。動的な検索を実行し、Solr からインデックス付きのデータを分析および視覚化する能力を提供します | 組み込み | MicroStrategy データ インポートを通じてサポートされます |
| Splunk Enterprise | ODBC | 広くし使用されている専有検索エンジン | Splunk ODBC ドライバー | MicroStrategy データ インポートを通じてサポートされます |
MicroStrategy Hadoop ゲートウェイ
MicroStrategy は、Hadoop Gateway を使用して HDFS へのネイティブ接続を提供します。Hadoop Gateway は Hive をバイパスし、HDFS から直接データにアクセスします。Hadoop Gateway は HDFS ノード上での別のインストールです。
Hadoop Gateway は、Hadoop への接続時、大きなインメモリ キューブを作成する使用事例を最適化するよう設計されています。Hadoop から効果的なバッチ データ インポートを実現するため、次の手法を採用しています。
- Hive をバイパスして直接データにアクセスする: Hive/ODBC を回避する Yarn アプリケーションとして実行する HDFS とネイティブに通信します。これにより、データ クエリとアクセス時間をさらに減らします。
- HDFS からのデータの並列ロード: 並列スレッド経由でデータを MicroStrategy Intelligence Server にロードし、スループットを高め、ロード時間を短縮します。
- インメモリ使用事例用にデータ クレンジングのプッシュダウンを有効にする: データ ラングリング オペレーションは Hadoop で実行され、大規模なラングリングが可能です。
Hadoop Gateway のアーキテクチャの概要
- Hadoop Gateway は別の MicroStrategy 専有インストールであり、以下をインストールして、HDFS データおよび名前ノード上にインストールする必要があります。
- HDFS 名前ノードに Hadoop Gateway クエリ エンジン
- HDFS 実行エンジンに Hadoop Gateway 実行エンジン
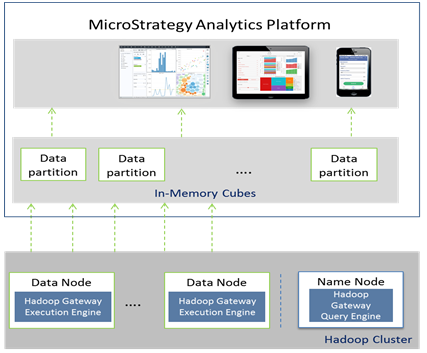
- MicroStrategy Intelligence Server は Hadoop Gateway 実行エンジンにクエリを送信します。その後、クエリは解析されて、データ ノードに送られ、処理されます。次に、クエリ用にフェッチされたデータは、インメモリ キューブに公開されるよう、データ ノードから並列スレッドの MicroStrategy Intelligence Server へとプッシュされます。
次の図は、アーキテクチャ図における MicroStrategy Hadoop Gateway を示しています。
Hadoop Gateway の制限
現在、Hadoop Gateway にはいくつかの制限があります。
- テキストおよび csv ファイルのみがサポートされます。
- データ ラングリングは、インメモリ使用事例でのみサポートされます
- マルチテーブル データのインポートはサポートされません。
- 分析機能については、集計とフィルタリングのみがサポートされます。JOIN 操作はサポートされません。
- Kerberos セキュリティは共有サービス ユーザーと、特定のユーザーに対する委任でサポートされています。
ビッグデータ ソースへの接続のワークフロー例
このセクションでは、MicroStrategy からビッグデータ ソースに接続するためのさまざまなワークフローの例を示します。
- ウェブデータ インポート経由で Hortonworks Hive に接続するには
- ウェブデータ インポート経由で Hortonworks Hive に接続するには
- Hadoop Gateway 経由で接続するには
Developer 経由での Hortonworks Hive への接続
Business Intelligence アドミニストレーター/開発者は、MicroStrategy Developer を使用し、下記の手順でビッグデータ ソースに接続できます。ワークフローは、従来のデータベースと MicroStrategy の統合方法に似ています。手順は、3 つの概念的エリアに分類できます。
- MicroStrategy からソースへの接続を構築します。これには、適切な接続の詳細を使用した ODBC データ ソースの作成や、ODBC ソースをポイントするデータベース インスタンス オブジェクトの作成が含まれます。
- ウェアハウス カタログ インターフェイス経由でソースからテーブルをインポートします。
- 必要なスキーマ オブジェクト (アトリビュートやファクトなど) を作成して、レポートや dossier を構築します。
次の手順では、Hortonworks Hive を例として示しています。
MicroStrategy からソースへの接続を構築するには:
-
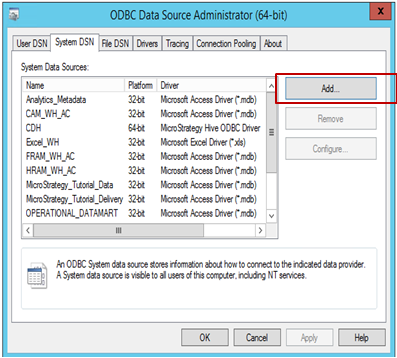
ODBC Data Source Administrator を開いて、ソースへのデータ ソース接続を構築します。[追加] をクリックして新規の接続を作成します。
-
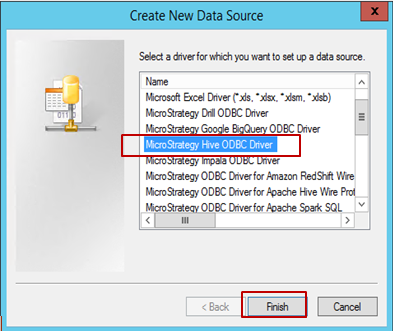
ドライバー (この例では [Hive ODBC] が選択されています) を選択し、[終了] をクリックします。
-
適切な接続性の詳細を入力します。
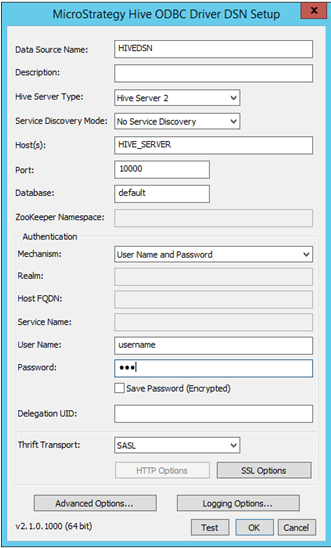
- データ ソース名: 接続の保存に使用される名前
- 説明: オプション
- Hive サーバー タイプ: 環境ごとにサーバーを選択します
-
サービス検出モード: 以下のように、2 つのサービス検出モードを使用できます。ユーザーが「Zookeeper」を選択すると、MicroStrategy では次のように Zookeeper 名前スペースを入力できます。
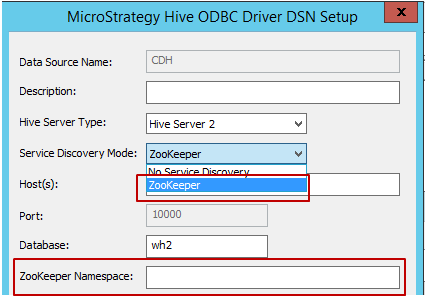
- ホスト、ポートおよびデータベース名: 環境に応じて入力される必須フィールド。
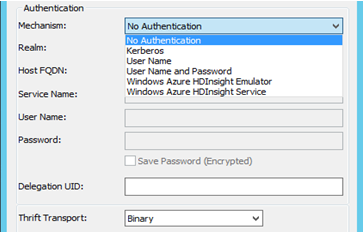
- 認証: MicroStrategy は、Hortonworks Hive に異なる認証メカニズムを認証します。認証なし、Kerberos、ユーザー名、ユーザー名とパスワード。メカニズムの選択に基づき、Thrift トランスポート パラメーターが変化します。例えば、次のようになります。
- 認証なしの場合 - Thrift トランスポート パラメーターは「バイナリ」
- Kerberos の場合 - Thrift トランスポート パラメーターは「SASL」
ユーザー名、ユーザー名とパスワード - Thrift トランスポート パラメーターは「SASL」になります
- 接続の詳細を選択して入力した後、[テスト] ボタンを使用してテストできます。
-
MicroStrategy Developer を開きます。[プロジェクト] にログインして [構成マネージャー] > [データベース インスタンス] に移動し、新しいデータベース インスタンスを作成します。
MicroStrategy Developer を Windows で初めて実行するときは、管理者として実行してください。
プログラム アイコンを右クリックして、[管理者として実行] を選択します。
これは、Windows のレジストリ キーを正しく設定するために必要な手順です。詳細は、「KB43491」を参照してください。
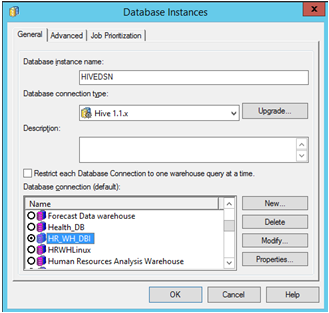
以前ソース用に作成した [データ ソース名] を選択します。必要なユーザー ログインおよびパスワードを入力します。
-
ソースからのテーブルのインポート: [スキーマ] > [ウェアハウス カタログ] > [データベース インスタンスを選択] へ移動し、ソースから必要なテーブルをドラッグ アンド ドロップします。
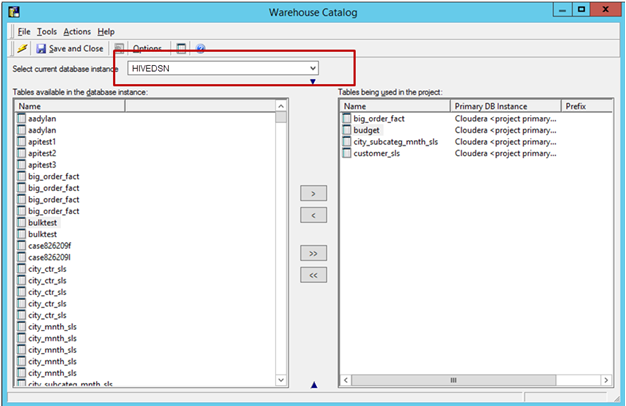
カタログを保存して閉じます。
-
必要に応じてアトリビュートとメトリックを構築します。新しい MicroStrategy レポートを立ち上げて分析を構築します。
ウェブデータ インポート経由で Hortonworks Hive に接続するには
ビジネス アナリストやエンド ユーザーは、MicroStrategy ウェブ データ インポートを活用して、リレーショナル データ ソースの場合と同じようにデータを接続および分析できます。3 つの概念的エリアに分類できます。接続、インポート、および分析。
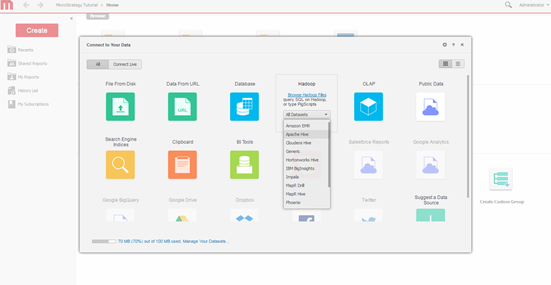
以下は、Hortonworks Hive からの MicroStrategy ウェブ データ インポートから接続性ウィンドウです。
-
クエリ エンジンを選択します。MicroStrategy データ インポート画面から接続するエンジンを選択します。
-
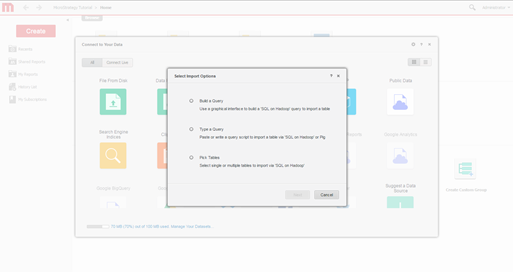
インポート オプションを選択します。クエリを構築、クエリを入力、またはテーブルを選択のいずれかを選択します。テーブル選択アプローチは、MicroStrategy のモデル化機能を最大限に活用しているため、お勧めです。
-
接続を作成します。Hadoop システムへの新しい接続を定義します。
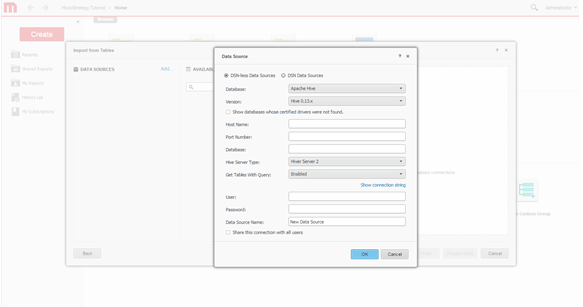
-
[テーブル] を選択します。データがアクセスするテーブルを選択します。
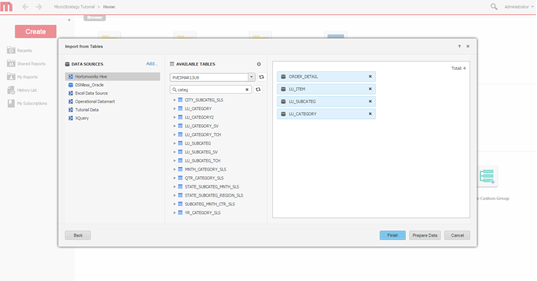
-
データをモデル化します。オプションとして、テーブルをモデル化、アトリビュートとメトリックの名前を変更、インポートから列を除外するなどがあります。
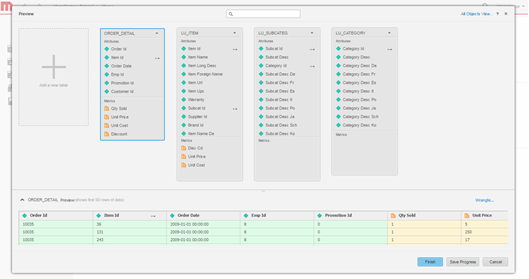
-
データ アクセス モードを定義します。データをインメモリ キューブとして、またはライブ接続モード経由のどちら公開するかを選択します。
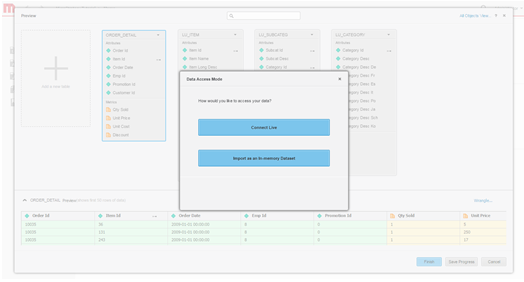
- dossier を構築します。
Hadoop Gateway 経由で接続するには
Hadoop Gateway は、次の一般的なデータ インポート ワークフローに従うことで、MicroStrategy Web Data インポートから活用できます。
- Hadoop/HDFS クラスターへの接続を構築します
- HDFS からフォルダーを参照してインポートします
- データのクレンジング (オプション)
- MicroStrategy Intelligence Server 内のインメモリ キューブとしてデータを公開し、dossier を通じてデータを分析します
各手順の詳細を以下に示します。
-
接続を構築します。
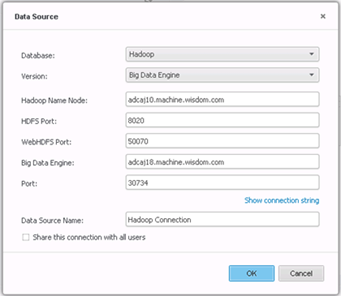
-
インポートするテーブルを選択します。
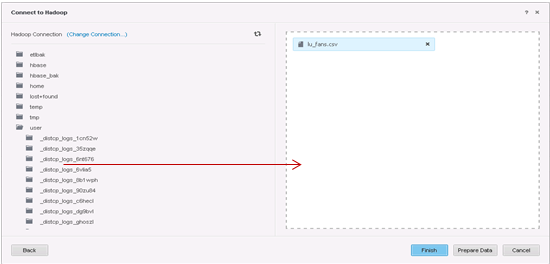
-
データ ラングラーでデータを準備します。
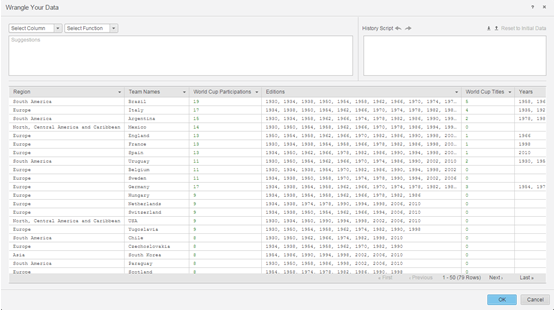
- 次の手順では、インメモリ キューブを MicroStrategy Intelligence Server に公開し、ビジュアル インサイト インターフェイスを使用して dossier を構築します。