Version 2021
Big Data in MicroStrategy analysieren
In der Branche „Business Intelligence und Analyse“ bezieht sich „Big Data“ primär auf die Ausschöpfung großer Datenmengen, die von herkömmlichen Systemen nicht gehandhabt werden können. Big Data erfordert neue Technologien, um die großen Datensätze zu speichern, zu verarbeiten, zu durchsuchen, zu analysieren und zu visualisieren.
Weitere Informationen finden Sie unter den folgenden Themen:
Neue Benutzer: Übersicht – stellt eine allgemeine Einführung zu Big Data bereit
Erfahrene Benutzer:
- Einbinden und Analysieren von Big-Data-Quellen in MicroStrategy – Erörtert, wie MicroStrategy verwendet wird, um eine Verbindung zu Big-Data-Quellen herzustellen
- Beispielabläufe zur Verbindung mit Big-Data-Quellen – Zeigt Beispiele zur Verbindungskonfiguration
Übersicht zu Big Data
Dieser Abschnitt dient als eine allgemeine Einführung zu Big Data und fasst die Terminologie und die häufigsten Anwendungsfälle zusammen. Die folgenden Themen werden abgedeckt:
- Anwendungsfälle für Big Data
- Charakteristika von Big Data
- Herausforderungen bei der Anwendung von Big Data
- Übersicht der Hadoop-Komponenten
Anwendungsfälle für Big Data
Big-Data-Technologien machten Anwendungsfälle möglich, die vorher aufgrund von großer Datenmengen oder komplexer Analytik nicht durchführbar waren. Heute hilft die Nutzbarmachung der Informationen und Einsichten, die in Big Data verborgen waren, allen Betriebsformen:
- Einzelhändler möchten überlegenen und personalisierten Kundendienst anbieten, indem Partnern Informationen zum Kaufverhalten des Kunden, aktuellen Produkten, Preisgestaltung und Sonderaktionen zur Verfügung gestellt werden. Die Ausführung von Big-Data-Analytik mit MicroStrategy kann helfen, dem Personal in den Filialen personalisierte und relevante Benutzerfreundlichkeit bereitzustellen.
- Hersteller sehen sich mit einer konstanten Nachfrage nach erhöhter Effizienz, niedrigeren Preisen und ununterbrochenen Serviceebenen konfrontiert, was sie zwingt, Kosten über die gesamte Lieferkette zu reduzieren. Sie benötigen auch Verbrauchsanalyse durch Untersuchen des Produktabsatzes in Bezug auf Konsumentendemographie und Einkaufsverhalten. Unter Verwendung von MicroStrategy können Hersteller Big-Data-Analytik zu verschiedenartigen Quellen ausführen, um perfekte Bestellquoten und Qualität zu erzielen, und um in die tiefe gehende Verbrauchsstrukturen zu erhalten.
- Telefongesellschaften benötigen Planung und Optimierung der Netzwerkkapazität durch Korrelieren der Netzwerkverwendung, Abonnentendichte zusammen mit Verkehrs- und Standortdaten. Telefongesellschaften, die MicroStrategy verwenden, können Analytik ausführen, um Netzwerkkapazität genau zu überwachen und zu prognostizieren, um effektiv potentielle Ausfälle zu planen, und um Sonderaktionen durchzuführen.
- Die Gesundheitspflege hat zum Ziel, die Petabyte Patientendaten, die Organisationen in der Gesundheitspflege gehören, zu verwenden, um pharmazeutischen Absatz und Patientenanalyse zu verbessern und um Zahlungspflichtigen bessere Lösungen zu ermöglichen. MicroStrategy kann wirkungsvoll Anwendungen erstellen und ausführen, um zu helfen, solche Anwendungsfälle zu erfüllen.
- Die Regierung hat, neben anderen Vorgängen in großem Umfang, mit Sicherheitsbedrohungen, Bevölkerungsdynamik, Budgetierung und Finanzen zu kämpfen. Die analytischen Funktionen von MicroStrategy bei großen und komplexen Datensätzen kann dem staatlichen Personal tiefe Einblicke gewähren, um auf Informationen beruhende Richtlinienentscheidungen zu treffen, Verschwendung und Betrug zu eliminieren, mögliche Bedrohungen zu identifizieren und für die zukünftigen Bedürfnisse der Bürger zu planen.
Charakteristika von Big Data
Big Data bringt neue Herausforderungen und erfordert neue Lösungsansätze, um mit den Herausforderungen umzugehen. Während Unternehmen Pläne entwickeln, Big-Data-Anwendungsfälle zu ermöglichen, müssen sie die 5V-Charakteristika von Big Data berücksichtigen: Volumen, Varianz, Geschwindigkeit, Variabilität und Wert (Volume, Variety, Velocity, Variability und Value).
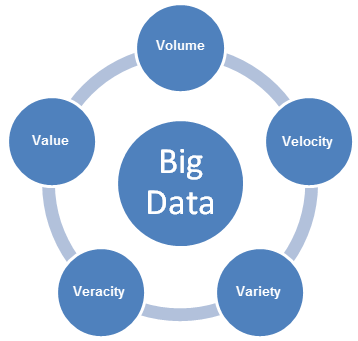
- Volumen bezieht sich auf die Größe des erzeugten Dateninhalts, der analysiert werden muss.
- Geschwindigkeit bezieht sich auf die Schnelligkeit, mit der neue Daten generiert werden, und der Schnelligkeit, mit der Daten verschoben werden.
- Varianz bezieht sich auf die Datentypen, die analysiert werden können. In der Vergangenheit fokussierte sich die Analytikbranche auf strukturierte Daten, die in Tabellen und Spalten passen und die normalerweise in relationalen Datenbanken gespeichert wurden. Heutzutage ist jedoch ein Großteil der Daten dieser Welt nicht strukturiert und kann nicht einfach in Tabellen untergebracht werden. Auf einer umfangreicheren Ebene können die Daten in die folgenden drei Kategorien aufgeteilt werden. Jede davon erfordert andere Lösungsansätze, um die Daten zu analysieren
- Strukturierte Daten sind Daten, deren Struktur bekannt ist. Die Daten sind in einem festen Feld innerhalb einer Datei oder eines Datensatzes gespeichert.
- Unstrukturierte Daten sind Informationen, die über kein definiertes Datenmodell oder keine definierte Anordnung verfügen. Die Daten können Text (Textkörper einer E-Mail, Sofortnachrichten, Word-Dokumente, PowerPoint-Präsentationen, PDF) oder Nicht-Texte (Audio/Video/Grafikdateien) sein.
- Teilweise strukturierte Daten ist eine Mischung aus strukturierten und unstrukturierten Daten. Die Daten sind ohne ein striktes Datenmodell, wie z. B. Ereignisprotokoll-Daten oder Zeichenfolgen mit Schlüssel-Wert-Paaren, strukturiert.
- Wahrhaftigkeit bezieht sich auf die Vertrauenswürdigkeit der Daten. Bei vielen Quellen und Feldern in Big Data sind Qualität und Genauigkeit weniger steuerbar.
- Wert bezieht sich auf die Möglichkeit, Big Data in klare Geschäftswerte umzuwandeln, was Zugriff und Analyse erfordert, um einen bedeutungsvollen Output zu erzeugen.
Herausforderungen bei der Anwendung von Big Data
Während Unternehmen Lösungen entwickeln, die in ihren Big-Data-Systemen vorhandenen Informationen zu gewinnen, kommt es zu folgenden Herausforderungen:
- Performance: Organisationen versuchen, erweiterte Analytik im Kampf mit Big Data zu implementieren, um interaktive Performance zu erzielen.
- Datenbund: Anwendungen in der realen Welt erfordern die Integration von Daten über Projekte. Es ist eine Herausforderung, Daten, die in verschiedenartigen Formaten und unterschiedlichen Quellen gespeichert sind, zu einem Verbund zu vereinigen.
- Datenbereinigung: Für Unternehmen stellt es eine Herausforderung dar, unterschiedliche Datenformen in der Vorbereitung auf die Analytik zu bereinigen.
- Sicherheit: Den großen „Datensee“ sicher zu halten, ist eine Herausforderung; einschließlich des richtigen Einsatzes der Verschlüsselung, der Aufzeichnung von Datenzugriffshistorien und dem Zugriff auf Daten über verschiedene Authentifizierungsmechanismen mit Industriestandard.
- Zeit bis Wert: Unternehmen sind eifrig bemüht den Zeitraum zu verkürzen, der notwendig ist, den Wert aus Daten freizusetzen. Die Abwicklung zahlreicher Quellen für unterschiedliche Datentypen und die Verwendung eines Netzes mit punktueller Lösungen ist oft zeitraubend.
Übersicht der Hadoop-Komponenten
In diesem Abschnitt werden die Hauptkomponenten des Hadoop-Ökosystems beschrieben.
Apache Hadoop ist ein Open-Source-Software-Framework für verteilte Abspeicherung und verteilte Bearbeitung, die es Organisationen ermöglicht, Daten zu speichern und abzufragen, wobei es sich um Bestellungen in einer Größenordnung größer als die Daten in herkömmlichen Datenbanken handelt; und dies soll in einer kostengünstigen, gebündelten Umgebung geschehen. Das folgende Bild zeigt das Architekturdiagramm der Apache-Hadoop-Komponenten.
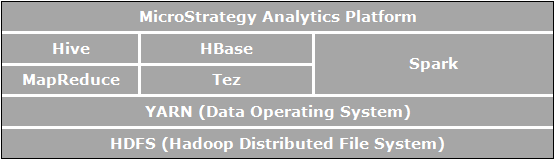
Die Elemente, die direkt in Bezug zur Geschäftsanalytik stehen, und relevant für die Anwendungsfälle sind, die in MicroStrategy aktiviert sind:
- HDFS (Hadoop Distributed File System) ist das Datenspeicher-Dateisystem, das von Hadoop-Anwendungen verwendet wird, die unter Clustern von Commodity-Computern ausgeführt werden. HDFS-Cluster bestehen aus einem NameNode (Namensknoten), der die Dateisystem-Metadaten verwaltet, und DataNodes (Datenknoten), die die tatsächlichen Daten speichern. HDFS ermöglicht die Speicherung großer importierter Dateien aus Anwendungen außerhalb des Hadoop-Ökosystems und auch die Bereitstellung importierter Dateien, um durch Hadoop-Anwendungen verarbeitet zu werden.
- YARN (Yet Another Resource Negotiator) stellt Ressourcenverwaltung bereit und ist eine zentrale Plattform zur Bereitstellung von Vorgängen, Sicherheit und Datenkontroll-Tools über Hadoop-Cluster hinweg für Anwendungen, die unter Hadoop ausgeführt werden.
- MapReduce ist ein verteiltes Datenbearbeitungsmodell und eine Ausführungsumgebung, die auf großen Clustern von Commodity-Computern ausgeführt wird. Es wird der MapReduce-Algorithmus verwendet, der alle Vorgänge zu Karten- und/oder Reduzierungsfunktionen herunterbricht.
- Tez ist ein generalisierter Datenfluss-Programmierungsframework, der entworfen wurde, SQL-Abfrage-Arbeitsabläufen, im Vergleich zu MapReduce, verbesserte Performance bereitzustellen.
- Hive ist ein verteiltes Data Warehouse, das oben auf HDFS aufgesetzt ist, um große Datenmengen zu verwalten und zu organisieren. Hive bietet einen schematisierten Datenspeicher für das Aufnehmen großer Mengen Rohdaten und eine SQL-ähnliche Umgebung zur Ausführung von Analyse- und Abfrageaufgaben zu Rohdaten in HDFS. Die SQL-ähnliche Umgebung von Hive ist der populärste Weg, Hadoop abzufragen. Zusätzlich kann Hive verwendet werden, um SQL-Abfragen zu einer Vielzahl von Abfragemodulen, wie Map-Reduce, Tez, Spark, etc., zu kanalisieren.
- Spark ist ein Cluster-Comuting-Framework. Es stellt ein einfaches und expressives Programmierungsmodell bereit, das eine große Anzahl von Anwendungen unterstützt, einschließlich ETL, Machine Learning, Datenstromverarbeitung und Diagrammberechnung.
- HBase ist eine verteilte, spaltenorientierte Datenbank. Sie verwendet HDFS für ihre zugrunde liegende Abspeicherung und unterstützt sowohl stapelförmige Berechnungen unter Verwendung von MapReduce wie auch Punktabfragen (zufällige Lesevorgänge), die transaktional sind.
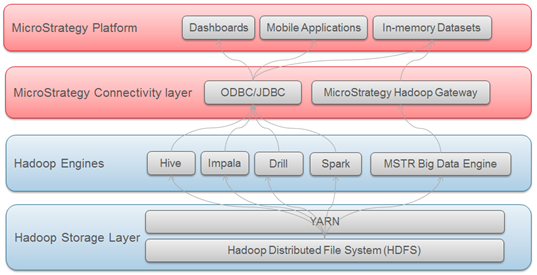
Einbinden und Analysieren von Big-Data-Quellen in MicroStrategy
Das Big-Data-Ökosystem verfügt über eine Anzahl SQL-Module (Hive, Impala, Drill, etc.), die es Benutzern ermöglichen, SQL-Abfragen zu Big-Data-Quellen weiterzuleiten und die Daten zu analysieren, wie sie es mit herkömmlichen relationalen Datenbanken tun würden. Die Benutzer können somit dasselbe analytische Framework wirksam einsetzen, wie sie es tun, wenn Sie über SQL auf strukturierte Daten zugreifen.
MicroStrategy unterstützt und zertifiziert Konnektivität zu verschiedenen Big-Data-SQL-Engines. Ähnliche wie bei herkömmlichen Datenbanken verläuft die Konnektivität zu diesen SQL-Engines über ODBC- oder JDBC-Treiber.
MicroStrategy bietet auch eine Methode an, die es Benutzern ermöglicht, Daten direkt aus dem Hadoop-Dateisystem (HDFS) zu importieren. Dies wird erreicht durch Verwendung des MicroStrategy Hadoop Gateway, das es Clients ermöglicht, die SQL-Abfragemodule zu umgehen und die Daten direkt für die Analyse aus dem Dateisystem zu MicroStrategys Im-Speicher-Cubes zu laden.
Das folgende Diagramm zeigt die Ebenen, durch die die Daten geführt werden, um von Hadoop-Systemen zu MicroStrategy zu gelangen.
Auswählen des Datenzugriffsmodus
MicroStrategy ermöglicht es Benutzern, wirkungsvoll Ressourcen des Big-Data-Systems und des BI-Systems hintereinander einzusetzen, um die beste Performance zur Ausführung von Analytik bereitzustellen. Benutzer haben die folgenden Optionen:
- Übergeben Sie Daten in den Speicher (speicherinterner Ansatz) - Die Daten für die Analyse werden exklusiv aus dem speicherinternen Cube bezogen. MicroStrategy ermöglicht es Benutzern, Teilmengen von Daten aus einer Big-Data-Quelle in einen Im-Speicher-Cube abzuziehen und aus dem Cube Berichte/Dossiers zu erstellen; dabei kann es sich um bis zu Hunderte Gigabyte handeln. Normalerweise ist ein Cube so eingerichtet, dass er in regelmäßigen Intervallen veröffentlicht und im Hauptspeicher des Servers gespeichert wird, wodurch die zeitaufwendige Notwendigkeit, die Big-Data-Datenbank abzufragen, entfällt.
- Greifen Sie direkt auf die Daten von der Quelle zu (Lösungsansatz „Live verbinden“) - Es wird exklusiv von der Datenbank auf die Daten zugegriffen. MicroStrategy bietet Konnektivität zu verschiedenen Big-Data-Quellen, um Berichte und Dossiers dynamisch live gegen die Quelle auszuführen.
- Übernehmen Sie einen Mischform-Lösungsansatz - Daten werden, wie benötigt, aus dem Im-Speicher-Cube und der Datenbank erhalten. Der Mischform-Lösungsansatz nutzt wirkungsvoll die Stärke beider obiger Methoden, indem sie dem Benutzer gestattet – abhängig von der von den Benutzern eingereichten Abfrage –, nahtlos zwischen Ihnen zu wechseln. MicroStrategy verfügt über dynamische Beschaffungstechnologie, die automatisch bestimmt, ob eine bestimmte Abfrage durch Cubes oder durch die Datenbank beantwortet werden kann, und kann die Abfrage entsprechend kanalisieren.
Die folgende Abbildung fasst die drei Lösungsansätze zusammen:
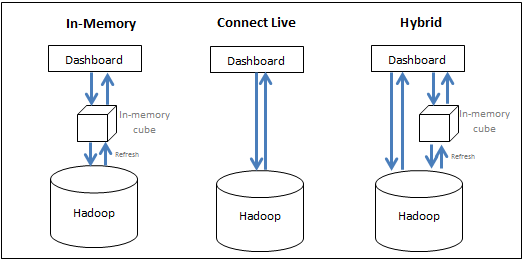
Während der Lösungsansatz „Im Speicher“ normalerweise die schnellste analytische Leistung erzielt, ist er u. U. aufgrund eines großen Datenvolumens nicht praktikabel. Der folgende Abschnitt erläutert Entwurfsüberlegungen bei der Entscheidung, wie auf die Daten zugegriffen werden sollte.
- Lösungsansatz „Im Speicher“: Dieser Lösungsansatz bietet schnellere Performance; die Daten sind jedoch auf den kleinen Satz begrenzt, der in den Hauptspeicher passt, und abhängig davon, wie oft die Im-Speicher-Daten aktualisiert werden, könnten die Daten veraltet sein. Verwenden Sie diesen Lösungsansatz, wenn:
- die abschließenden Daten in einer aggregierten Form vorliegen und in den Hauptspeicher des BI-Computers passen
- die Datenbank zu langsam für interaktive Analyse ist
- der Benutzer die Auslastung einer transaktionalen Datenbank aufheben muss
- der Benutzer offline sein muss
- Datensicherheit auf der BI-Ebene eingerichtet werden kann
- Lösungsansatz „Live verbinden“: In Situationen, in denen die Daten für das Dossier aktuell sein müssen, oder wenn die Daten auf einer Detailebene vorhanden sind, so dass nicht alle Daten im Im-Speicher-Cube gespeichert werden können, könnte das Erstellen eines Dossiers unter Verwendung der Option „Live verbinden“ ein passender Lösungsansatz sein. Dies ermöglicht es, bei der Ausführung die neuesten Daten aus dem Warehouse abzurufen. Dieser Lösungsansatz ist auch in Fällen hilfreich, in denen die Sicherheit auf der Datenbankebene eingerichtet wird und eine Warehouse-Ausführung für jeden Benutzer erforderlich ist, um die Daten angezeigt zu bekommen, auf die sie Zugriff haben. Verwenden Sie diesen Lösungsansatz, wenn:
- die Datenbank schnell und reaktionsfähig ist
- der Benutzer auf Daten zugreift, die in der Datenbank oft aktualisiert werden
- Datenvolumen höher als das Im-Speicher-Maximum sind
- die Benutzer eine geplante Zustellung eines im Voraus ausgeführten Dossiers wünschen
- Datensicherheit auf der Datenbankebene eingerichtet wird
- Mischform-Lösungsansatz: Dieser Lösungsansatz ist passend für die Anwendungsfälle, in denen der Begrüßungsbildschirm für das Dossier auf hoher Ebene aggregierte Informationen enthält, von denen die Benutzer in die Details drillen können. In solchen Fällen können die Administratoren die aggregierten Daten in einen Im-Speicher-Cube aggregieren, so dass der Hauptbildschirm des Dossiers schnell angezeigt wird und sich das Dossier dann auf die Daten niedrigerer Ebene im Big-Data-System richten, wenn der Benutzer nach unten drillt. Die dynamische Beschaffungsfunktion in MicroStrategy macht die Erstellung solcher Anwendungen einfach, da ausgewählte Berichte zu Cubes umgewandelt werden können und MicroStrategy automatisch bestimmt, ob, abhängig von den Daten, die der Benutzer anfordert, geben die Cubes oder die Datenbank fortgefahren werden soll.
Unterstützte Big-Data-Treiber und Lieferanten
Hadoop SQL-Engines sind für bestimmte Datenmanipulation optimiert. Basierend auf dem Datentyp und den ausgeführten Abfragen, um auf die Daten zuzugreifen, können wir Anwendungsfälle in die fünf folgenden Gruppen aufteilen:
- Batch-SQL – Wird für die Ausführung von umfangreiche Transformationen zu Big Data verwendet.
- Interaktive SQL - Aktiviert interaktive Analyse zu Big Data.
- Kein SQL – Wird normalerweise für umfangreiche Datenspeicherung und schnelle transaktionale Abfragen verwendet.
- Unstrukturierte Daten / Suchmaschinen – Analysieren von Textdaten oder Protokolldaten, verwendet hauptsächlich Suchfunktionalitäten
- Bereinigen von Daten und in Speicher laden / Hadoop Gateway – Optimiert und primär für die schnelle Veröffentlichung von speicherinternen Cubes verwendet
Die folgende Abbildung zeigt die Zuordnung zwischen den Anwendungsfällen und den Engines (Modulen), die aktuell in MicroStrategy unterstützt werden.
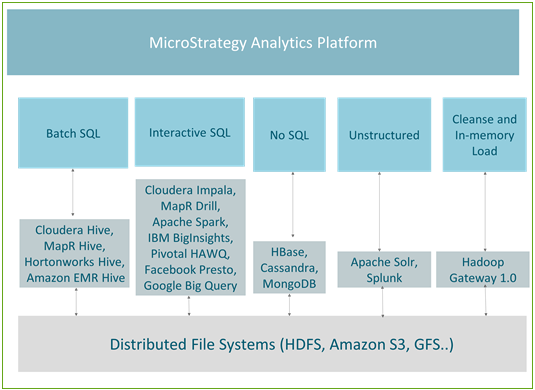
Stapelverarbeitung
Hive ist der am häufigsten verwendete Abfragemechanismus für Stapelverarbeitung. Da es fehlertolerant ist, wird es für Aufträge des Typs ETL empfohlen. Alle führenden Hadoop-Verteilungen (wie z. B. Hortonworks, Cloudera, MapR und Amazon EMR) bieten Hive ODBC-Verbindungen. MicroStrategy ist Partner aller obigen Hadoop-Vertreiber und bietet eine zertifizierte Konnektivität zu Hadoop über Hive.
Hive ist eine gute Engine beim Lösungsansatz „Im Speicher“ in MicroStrategy oder als Teil des Lösungsansatzes „Live verbinden“, wenn es mit Distribution Services gepaart ist, sodass die Datenbankwartezeit den Endbenutzer nicht beeinflusst. Da es MapReduce verwendet, um die Abfragen zu verarbeiten, hat die Stapelverarbeitung eine hohe Wartezeit und ist nicht passend für interaktive Abfragen.
Die folgende Tabelle listet Verbindungsinformationen für die unterstützten Hive-Verteilungen auf.
| Hersteller | Datenbankverbindung | Anwendungsfall | Treibername | Arbeitsablauf |
|---|---|---|---|---|
| Cloudera Hive | ODBC | Ein Tool, das SQL verwendet und zu MapReduce konvertiert; es kann verwendet werden, um ETL-ähnliche Transformation zu Daten in großem Maßstab auszuführen | MicroStrategy Hive ODBC-Treiber | Datenimport |
| Hortonworks Hive |
ODBC |
Ein Tool, das SQL verwendet und zu MapReduce konvertiert; es kann verwendet werden, um ETL-ähnliche Transformation zu Daten in großem Maßstab auszuführen | MicroStrategy Hive ODBC-Treiber | Datenimport |
| MapR Hive | ODBC | Ein Tool, das SQL verwendet und zu MapReduce konvertiert; es kann verwendet werden, um ETL-ähnliche Transformation zu Daten in großem Maßstab auszuführen | MicroStrategy Hive ODBC-Treiber | Datenimport |
| Amazon EMR Hive | ODBC | Ein Tool, das SQL verwendet und zu MapReduce konvertiert; es kann verwendet werden, um ETL-ähnliche Transformation zu Daten in großem Maßstab auszuführen | MicroStrategy Hive ODBC-Treiber | Datenimport |
Interaktive Abfragen
Verschiedene Hadoop-Lieferanten haben Engines mit schneller Performance entwickelt, um interaktive Abfragen zu ermöglichen. Diese Engines (Module) verwenden lieferantenspezifische/technologiespezifische Mechanismen, um HDFS abzufragen, verwenden aber dennoch Hive als einen Metastore. Alle diese Technologien entwickeln sich schnell, um schnellere Antwortzeiten bei großen Datensätzen bereitzustellen; dies in Verbindung mit erweiterten analytischen Funktionen. Interaktive Engines wie Impala, Drill oder Spark können wirkungsvoll mit MicroStrategy Dossier gekoppelt werden, um Self-Service-Datenermittlung bei Hadoop zu ermöglichen. Die Engines sind für den Einsatz mit MicroStrategy zertifiziert.
Die folgende Tabelle listet Verbindungsinformationen für die unterstützten Verteilungen auf.
| Hersteller | Datenbankverbindung | Anwendungsfall | Treibername | Arbeitsablauf |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Ein SQL-Abfragemodul mit massiver paralleler Verarbeitung (MPP = massively parallel processing) im Open-Source-Format für Daten, die in einem Computer-Cluster gespeichert sind, auf dem Apache Hadoop ausgeführt wird. Impala verwendet ein eigenes Verarbeitungsmodul und kann Im-Speicher-Vorgänge ausführen | MicroStrategy Impala ODBC-Treiber | Datenimport |
| Apache Drill | ODBC | Ein Abfragemodul mit geringer Wartezeit im Open-Source-Format, das von MapR unterstützt wird. Es verfügt über die Möglichkeit, Schemata umgehend zu entdecken, um so Self-Service-Datenerkundungsfunktionen bereitzustellen | MicroStrategy Drill ODBC-Treiber | Datenimport |
| Apache Spark | ODBC | Ein Datenverarbeitungstool, das zu verteilten Datensammlungen ausgeführt wird und von einer der größten Open-Source-Communitys entwickelt wurde. Mit seiner Im-Speicher-Verarbeitung liegt Spark in der Größenordnung schneller als MapReduce | MicroStrategy ODBC-Treiber für Apache Spark SQL | Datenimport |
| IBM BigInsights | ODBC | Ein umfangreicher Satz erweiterter analytischer Funktionen, die es Unternehmen ermöglichen, massive Volumen strukturierter und unstrukturierter Daten in ihrem systemeigenen Format in Hadoop zu analysieren | BigInsights ODBC-Treiber | Datenimport |
| Pivotal HD | ODBC | Ein paralleles SQL-Abfragemodul, das Daten zu HDFS systemeigen liest und schreibt. Es bietet Benutzern eine komplett ANSI-Standard-kompatible SQL-Benutzeroberfläche | MicroStrategy ODBC-Treiber für Greenplum Wire Protocol | Datenimport |
| Google BigQuery | ODBC | Ein auf Cloud basierender Dienst, der Googles Infrastruktur wirksam einsetzt, um es Benutzern zu ermöglichen, Petabytes mit Daten interaktiv abzufragen | MicroStrategy Google BigQuery ODBC-Treiber | Datenimport |
NoSQL-Quellen
Es gibt keine SQL-Quellen, die für große Informationsabspeicherung und transaktionale Abfragen optimiert sind. Sie können wirkungsvoll mit der Option „Mehrfachquelle“ oder der Option zur Datenmischung in MicroStrategy gekoppelt werden, damit den Benutzern Informationen höherer Ebene von traditionellen Datenbanken gezeigt werden können, und die Nicht-SQL-Quelle kann verwendet werden, um die Möglichkeit bereitzustellen, einen Drill-Down zur niedrigsten Ebene mit Transaktionsdaten auszuführen (über Integration mit NoSQL-Quellen).
Die folgende Tabelle listet die NoSQL-Quellen auf, für die MicroStrategy zertifizierte Konnektivität anbietet.
| Hersteller | Datenbankverbindung | Anwendungsfall | Treibername | Arbeitsablauf |
|---|---|---|---|---|
| Apache Cassandra | JDBC | Ein Schlüssel-Wert-Lager; alle Daten bestehen aus einem indizierten Schlüssel und Wert | Cassandra JDBC-Treiber | Über MicroStrategy-Datenimport unterstützt |
| HBase | JDBC | Eine NoSQL-Datenbank im Spaltenlagerformat, in dem, anstatt Daten in Zeilen zu speichern, Daten in Tabellen als Bereiche von Spalten mit Daten gespeichert werden. Sie bietet hohe Performance und eine skalierbare Architektur | Phoenix JDBC-Treiber | Über MicroStrategy-Datenimport unterstützt |
| MongoDB | ODBC | Eine dokumentorientierte Datenbank, die die traditionelle tabellenbasierte relationale Datenbankstruktur vermeidet, was die Integration von Daten bei bestimmten Anwendungstypen einfacher und schneller macht | MicroStrategy MongoDB ODBC-Treiber | Über MicroStrategy-Datenimport unterstützt |
Unstrukturierte Daten / Suchmaschinen
Suchmaschinen sind wirkungsvolle Tools, die es Benutzern ermöglichen, große Menge Textdaten zu durchsuchen und den Daten in deren Dossiers Kontext hinzuzufügen. Diese Funktion ist leistungsstark, wenn sie bei Datenmischung in MicroStrategy wirksam eingesetzt wird, was es erlaubt, Suchdaten mit traditionellen Unternehmensquellen zu koppeln.
Die folgende Tabelle listet Verbindungsinformationen für die unterstützten Hive-Verteilungen auf.
| Hersteller | Datenbankverbindung | Anwendungsfall | Treibername | Arbeitsablauf |
|---|---|---|---|---|
| Apache Solr | Native | Die am häufigsten eingesetzte Suchmaschine, die vollständige Textsuche ermöglicht, facettierte Suchen und Echtzeit-Indizierung ermöglicht. MicroStrategy hat einen Konnektor für die Integration zu Solr entwickelt. Er stellt die Möglichkeit bereit, dynamische Suchen durchzuführen und die indizierten Daten von Solr zu analysieren und visualisieren | integriert | Über MicroStrategy-Datenimport unterstützt |
| Splunk Enterprise | ODBC | Eine verbreitet eingesetzte proprietäre Suchmaschine | Splunk ODBC-Treiber | Über MicroStrategy-Datenimport unterstützt |
MicroStrategy Hadoop Gateway
MicroStrategy bietet eine systemeigene Konnektivität zu HDFS unter Verwendung des Hadoop Gateway. Das Hadoop Gateway umgeht Hive und greift direkt von HDFS auf Daten zu. Hadoop Gateway ist eine separate Installation in HDFS-Knoten.
Hadoop Gateway wurde entworfen, um einen Anwendungsfall zur Erstellung großer Im-Speicher-Cubes bei der Verbindungserstellung zu Hadoop zu optimieren. Es wendet die folgenden Techniken an, um wirkungsvollen Stapeldatenimport von Hadoop zu erzielen:
- Umgeht Hive, um direkt auf Daten zuzugreifen: Kommuniziert systemeigen mit HDFS, das als eine Yarn-Anwendung ausgeführt wird, wobei Hive/ODBC umgangen wird. Dies reduziert die Datenabfrage und Zugriffszeit weiter.
- Paralleles Laden von Daten von HDFS: Lädt Daten in MicroStrategy Intelligence Server über parallele Threads und ergibt höheren Durchsatz und reduzierter Ladezeit.
- Ermöglicht Push-Down-Datenbereinigung für einen Anwendungsfall „Im-Speicher“: Datenumbauvorgänge werden in Hadoop ausgeführt, was Umbau in großem Umfang ermöglicht.
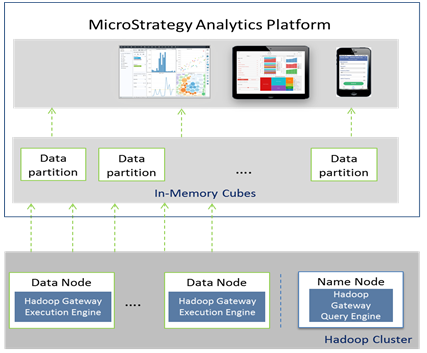
Übersicht über die Architektur von Hadoop Gateway
- Hadoop Gateway ist eine separate MicroStrategy-proprietäre Installation, die zu HDFS-Daten und Namensknoten installiert werden muss, indem Folgendes installiert wird:
- Hadoop Gateway Query Engine zu HDFS-Namensknoten
- Hadoop Gateway Execution Engine (Ausführungsmodul) zu HDFS Execution Engine (Ausführungsmodul)
- MicroStrategy Intelligence Server sendet die Abfrage an die Hadoop Gateway Execution Engine (Ausführungsmodul); die Abfrage wird dann analysiert und für die Bearbeitung zu Datenknoten gesendet. Die für die Abfrage abgerufenen Daten werden dann in parallelen Threads von den Datenknoten zu MicroStrategy Intelligence Server geschoben, um zu Im-Speicher-Cubes veröffentlicht zu werden.
Die folgende Abbildung zeigt MicroStrategy Hadoop Gateway in einem Architekturdiagramm.
Beschränkungen Hadoop Gateway
Aktuell gibt es für Hadoop Gateway einige Beschränkungen:
- Es werden nur Text- und CSV-Dateien unterstützt
- Datenumbau wird nur für Anwendungsfall „Im-Speicher“ unterstützt
- Mehrfachtabellen-Datenimport wird nicht unterstützt
- Für analytische Funktionen werden nur Aggregation und Filterung unterstützt. Der JOIN-Vorgang wird nicht unterstützt
- Kerberos-Sicherheit wird bei einem freigegebenen Dienst-Benutzer vs. Delegierung für bestimmte Benutzer unterstützt
Beispielabläufe zur Verbindung mit Big-Data-Quellen
Dieser Abschnitt enthält Beispiele zu verschiedenen Arbeitsabläufen für die Verbindung mit Big-Data-Quellen von MicroStrategy:
- So stellen Sie über den Web-Datenimport eine Verbindung mit Hortonworks Hive her
- So stellen Sie über den Web-Datenimport eine Verbindung mit Hortonworks Hive her
- So stellen Sie eine Verbindung über Hadoop Gateway her
Verbindung mit Hortonworks Hive über Developer
Administratoren/Entwickler von Business Intelligence können MicroStrategy Developer verwenden, um eine Verbindung zu einer Big-Data-Quelle unter Verwendung der nachfolgend erwähnten Schritte herzustellen. Der Arbeitsablauf ähnelt der Art, in der herkömmliche Datenbanken zu MicroStrategy integriert werden. Die Schritte können in drei konzeptionelle Bereiche unterteilt werden:
- Erstellung einer Verbindung von MicroStrategy zur Quelle. Dies umfasst die Erstellung einer ODBC-Datenquelle mit entsprechenden Konnektivitätsdetails und die Erstellung eines Datenbankinstanzobjekts, das zur ODBC-Quelle verweist.
- Das Importieren der Tabellen von der Quelle über die Schnittfläche „Warehouse-Katalog“.
- Erstellung der erforderlichen Schemaobjekte (wie Attribute, Fakten etc.), um Berichte und Dossiers zu erstellen.
In den folgenden Schritten wird Hortonworks Hive als ein Beispiel gezeigt.
So verbinden Sie MicroStrategy mit einer Quelle:
-
Öffnen Sie den ODBC-Datenquellen-Administrator, um eine Datenquellenverbindung zur Quelle zu erstellen. Klicken Sie auf Hinzufügen, um eine neue Verbindung zu erstellen.
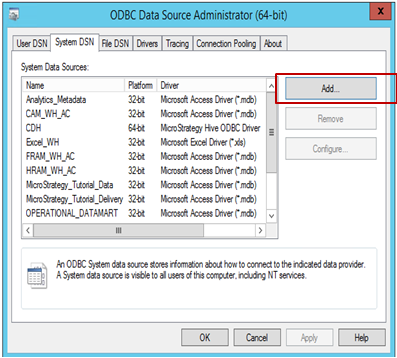
-
Wählen Sie den Treiber (in diesem Beispiel ist Hive ODBC ausgewählt) und klicken Sie auf Fertigstellen.
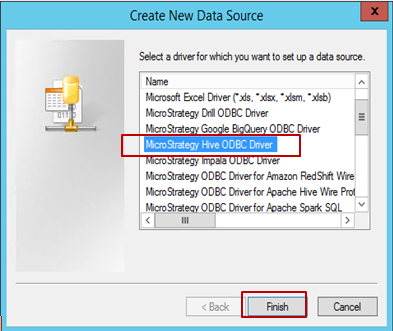
-
Geben Sie die entsprechenden Konnektivitätsdetails ein:
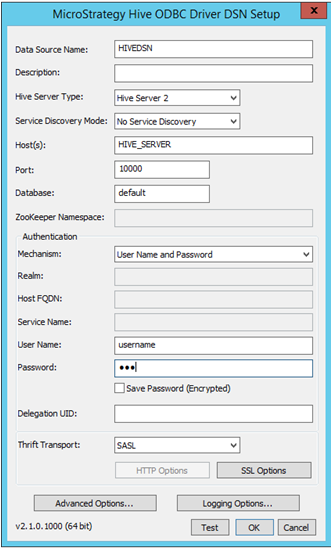
- Datenquellenname: Name, unter dem die Verbindung gespeichert wird
- Beschreibung: Optional
- Hive-Servertyp: Wählen Sie den Server pro Umgebung aus
-
Diensterkennungsmodus: Es gibt, wie dies im Folgenden dargestellt ist, zwei Diensterkennungsmodi, die verwendet werden können. Wenn der Benutzer ‚Zookeeper‘ auswählt, ermöglicht MicroStrategy es, ‚Zookeeper Namespace‘ einzugeben, wie dies im Folgenden dargestellt ist.
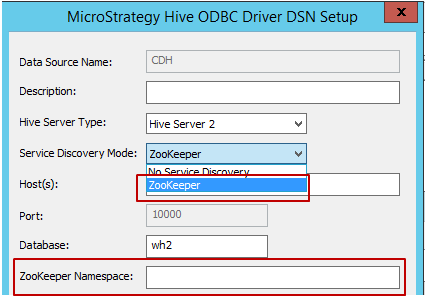
- Host, Port und Datenbankname: Erforderliche Felder, Eingabe pro Umgebung.
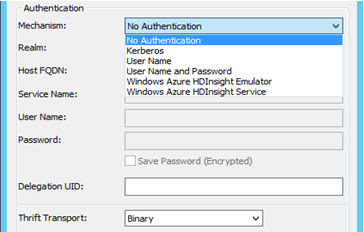
- Authentifizierung: MicroStrategy zertifiziert unterschiedliche Authentifizierungsmechanismen für Hortonworks Hive: Keine Authentifizierung, Kerberos, Benutzername, Benutzername und Kennwort. Basierend auf der Auswahl des Mechanismus ändert sich der Parameter „Thrift Transport“. Wie z. B.:
- Für Keine Authentifizierung – Der Parameter „Thrift Transport“ ist „Binär“.
- Für Kerberos - Der Parameter „Thrift Transport“ ist „SASL“.
Benutzername, Benutzername und Kennwort - Der Parameter „Thrift Transport“ ist „SASL“.
- Nachdem die Verbindungsdetails ausgewählt und eingetragen sind, kann dies unter Verwendung der Schaltfläche „Test“ getestet werden.
-
Öffnen Sie MicroStrategy Developer. Melden Sie sich beim Projekt an -> Wechseln Sie zum Konfigurationsmanager -> Datenbankinstanzen -> Erstellen Sie eine neue Datenbankinstanz.
Wenn Sie MicroStrategy Developer zum ersten Mal unter Windows ausführen, führen Sie es als Administrator aus.
Klicken Sie mit der rechten Maustaste auf das Programmsymbol und wählen Sie Als Administrator ausführen.
Dies ist erforderlich, um die Windows-Registrierungsschlüssel ordnungsgemäß festzulegen. Weitere Informationen finden Sie unter KB43491.
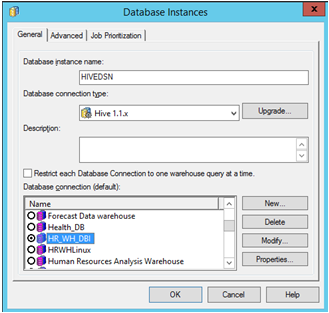
Wählen Sie den vorher für die Quelle erstellten „Datenquellennamen“. Geben Sie die erforderliche Benutzeranmeldung und das erforderliche Kennwort ein.
-
Importieren Sie Tabellen aus der Quelle: Wechseln Sie zu „Schema“ -> Warehouse-Katalog -> Wählen Sie die Datenbankinstanz aus -> Ziehen Sie die erforderlichen Tabellen aus der Quelle und legen Sie sie ab.
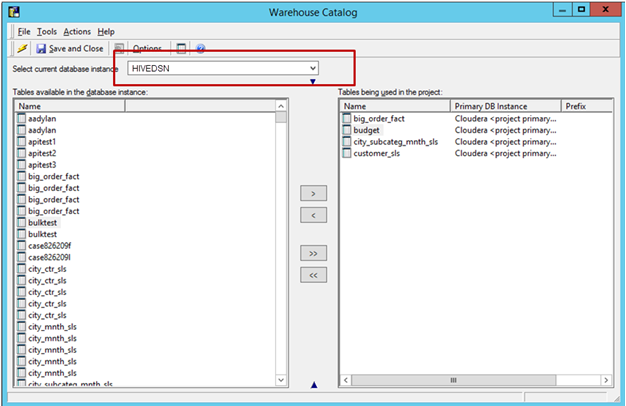
Speichern und schließen Sie den Katalog.
-
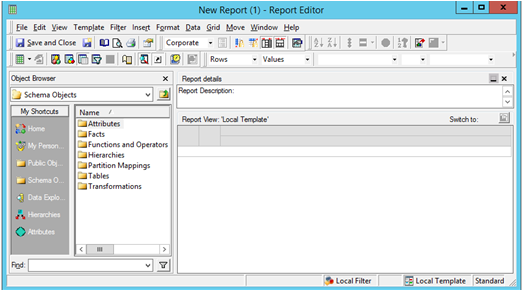
Erstellen Sie wie benötigt Attribute und Metriken. Starten Sie einen neuen MicroStrategy-Bericht, um Ihre Analyse zu erstellen.
So stellen Sie über den Web-Datenimport eine Verbindung mit Hortonworks Hive her
Geschäftsanalysten und Endbenutzer können den Datenimportarbeitsablauf in MicroStrategy Web wirksam einsetzten, um Daten zu verbinden und zu analysieren – genauso wie sie es mit relationalen Datenquellen machen würden. Dies kann in drei konzeptionelle Bereiche aufgeteilt werden: Verbinden, Importieren und Analysieren.
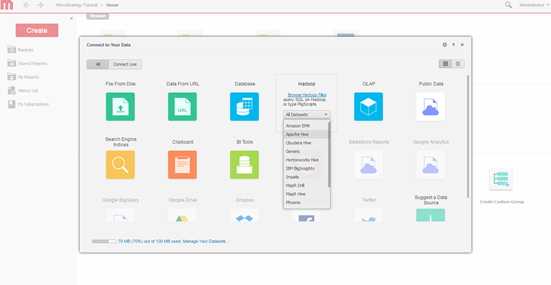
Nachfolgend sehen Sie das Konnektivitätsfenster aus dem MicroStrategy-Web-Datenimport bei der Verbindung zu Hortonworks Hive.
-
Wählen Sie „Abfragemodul“. Wählen Sie das Modul (Engine), zu dem über den Bildschirm „Datenimport“ von MicroStrategy eine Verbindung erstellt werden soll.
-
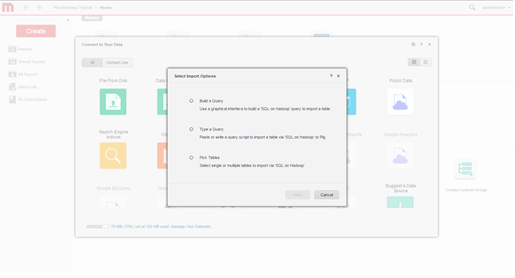
Wählen Sie Importoptionen aus. Wählen Sie aus, ob eine Abfrage erstellt, eine Abfrage eingegeben oder Tabellen ausgewählt werden sollen. Der Lösungsansatz „Tabellen auswählen“ wird empfohlen, da er die beste Verwendung der Modellierungsfunktionen von MicroStrategy bereitstellt.
-
Erstellen Sie die Verbindung. Definieren Sie eine neue Verbindung zum Hadoop-System.
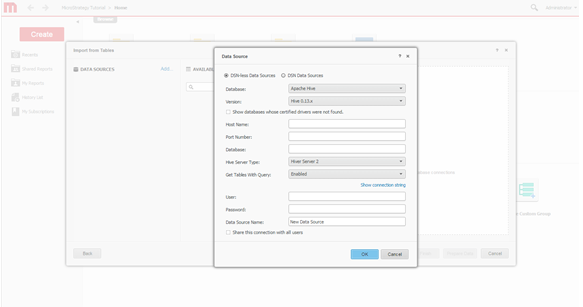
-
Wählen Sie Tabellen aus. Wählen Sie Tabellen, auf deren Daten zugegriffen wird.
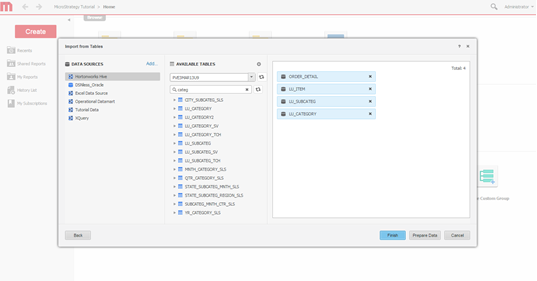
-
Modellieren Sie Daten. Optional modellieren Sie die Tabellen, ändern den Namen der Attribute und Metriken, schließen Spalten vom Import aus etc.
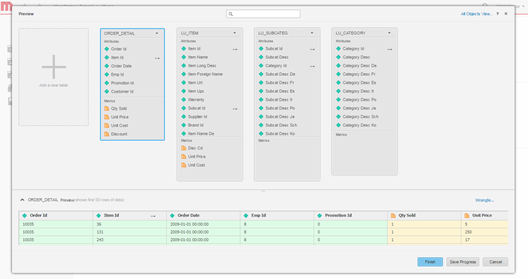
-
Definieren Sie den Datenzugriffsmodus. Wählen Sie aus, ob die Daten als ein Im-Speicher-Cube oder über den Modus „Live Connect“ veröffentlicht werden.
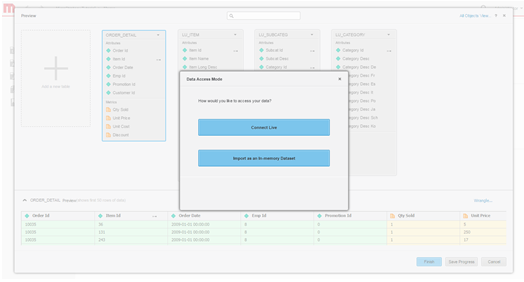
- Erstellen Sie das Dossier.
So stellen Sie eine Verbindung über Hadoop Gateway her
Hadoop Gateway kann vom Datenimport in MicroStrategy Web wirkungsvoll eingesetzt werden, wobei dem typischen Arbeitsablauf beim Datenimport gefolgt wird:
- Verbindung zum Hadoop/HDFS-Cluster erstellen
- Ordner von HDFS durchsuchen und importieren
- Die Daten bereinigen (optional)
- Veröffentlichen Sie die Daten als In-Memory-Cube im MicroStrategy Intelligence Server und analysieren Sie die Daten über ein Dossier
Nachfolgend sind die Details für jeden der Schritte.
-
Erstellen Sie die Verbindung.
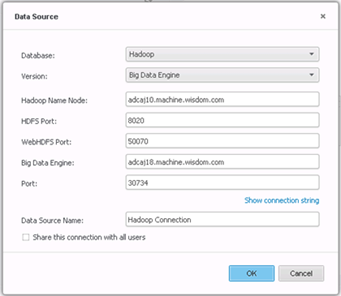
-
Wählen Sie zu importierende Tabellen aus.
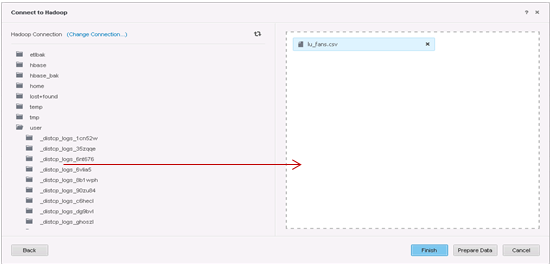
-
Bereiten Sie die Daten mit Data Wrangler vor.
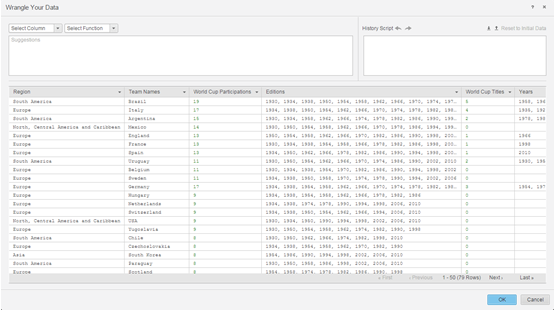
- Die nächsten Schritte sind dann die Veröffentlichung der In-Memory-Cubes zu MicroStrategy Intelligence Server und die Verwendung der Benutzeroberfläche „Visueller Einblick“, um ein Dossier zu erstellen.