Version 2021
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (ADLS2) ist eine Data-Lake-Plattform, die vollständig in Azure Blob Storage integriert ist. MicroStrategy Cloud Object Connector bietet Zugriff auf ADLS2, um schnell Ordner und Dateien zu durchsuchen und diese in MicroStrategy-Cubes zu importieren.
Erkunden Sie die folgenden Themen auf dieser Seite:
Verbindungsparameter vorbereiten
Damit Cloud Object Connector erfolgreich das ADLS2-Dateisystem durchsuchen kann, benötigen Sie ein Speicherkonto mit einem hierarchischen Namespace. Weitere Details zum Erstellen eines Speicherkontos finden Sie im Microsoft-Dokumentation.
Nachdem das Speicherkonto erstellt wurde, werden zwei Zugriffsschlüssel gewährt. Beide können zum Erstellen einer Verbindung verwendet werden.
DB-Rolle erstellen
Greifen Sie in MicroStrategy Web oder Workstation auf den Azure Data Lake Storage Gen2-Cloud-Objektkonnektor zu.
- Web
- Workstation
- Wählen Sie Daten hinzufügen > Neue Daten.
-
Suchen und auswählen Azure Data Lake Storage Gen2 Cloud-Objekt-Konnektor aus der Datenquellenliste.
-
Klicken Sie neben Datenquellen aufNeue Datenquelle
 um eine neue Verbindung hinzuzufügen.
um eine neue Verbindung hinzuzufügen.
-
Geben Sie Ihre Verbindungsanmeldedaten ein.
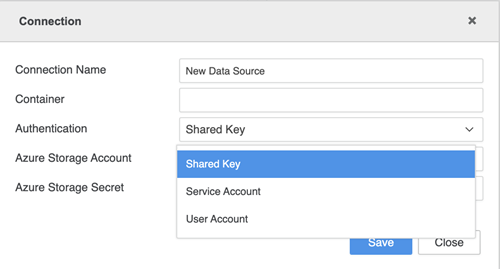
- Verbindungsname: Ein Name für die neue Verbindung
- Container: Der Container, auf den Sie zugreifen möchten
- Authentifizierung: Die gewünschte Authentifizierungsmethode
- Verzeichnis-ID (Tenant): Die ID, die den einzelnen Abonnements zugeordnet ist
- Azure Storage-Konto: Das Speicherkonto, das Ihre Azure Storage-Datenobjekte enthält
- Geheimer Azure Storage-Schlüssel: Der geheime Azure Storage zugeordnete
-
Klicken Sie im linken Bereich neben Datensätze auf Neuen Datensatz erstellen
.
-
Suchen und auswählen Azure Data Lake Storage Gen2 Cloud-Objekt-Konnektor aus der Datenquellenliste.
-
Klicken Sie neben Datenquellen aufNeue Datenquelle
um eine neue Verbindung hinzuzufügen.
-
Geben Sie Ihre Verbindungsanmeldedaten ein.
- Verbindungsname: Ein Name für die neue Verbindung
- Verzeichnis-ID (Tenant): Die ID, die den einzelnen Abonnements zugeordnet ist
- Azure Storage-Konto: Das Speicherkonto
- Container: Der Container, auf den Sie zugreifen möchten
- Client ID: Die verwendete Client-ID
- Clientgeheimnis: Der geheime Clientschlüssel, der der Client-ID zugeordnet ist
Datenimport
Nachdem Sie den Konnektor erfolgreich erstellt haben, können Sie Daten in MicroStrategy importieren.
- Wählen Sie die neu erstellte Verbindung aus.
- Ordner oder Dateien unter einem bestimmten Container durchsuchen,
-
Doppelklicken Sie auf Dateien oder ziehen Sie sie in den rechten Bereich.
Im Vorschaubereich können Sie die Beispieldaten sehen und den Spaltentyp anpassen.
- Veröffentlichen Sie den Cube mit den ausgewählten Daten in MicroStrategy.
Einschränkungen
Unterstützte Dateitypen
Es werden nur die folgenden Dateitypen unterstützt:
- .json
- .parkett
- .avro
- .orc
- .csv
- Deltaformat
Ordner auswählen
Wenn der gesamte Ordner ausgewählt wird, muss der Ordner die folgenden Anforderungen erfüllen:
- Alle Dateien in diesem Ordner müssen den gleichen Dateityp aufweisen. In einem Dialogfeld werden Sie aufgefordert, den Dateityp auszuwählen
- Alle Dateien verwenden dasselbe Schema
-
Verfügt der Ordner über Unterordner, sollten sich die Unterordner in einem gültigen partitionierten Format befinden. Folgendes ist ein Beispiel für eine gültige Ordnerstruktur
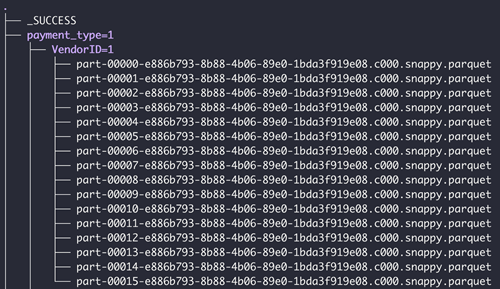
Einschränkungen bei Spark
- Nur JSON-Dateien mit jeder neuen Zeile als vollständige JSON können gelesen werden
- Parquet-Dateien mit Sonderzeichen (, ; { } \ = ".) können nicht gelesen werden
- Parquet-Dateien mit Spaltendatentypen als INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) werden nicht unterstützt
- Spalten mit dem Typ "Binary" können nicht im Cube veröffentlicht werden
- ORC-Dateien mit Feldnamen mit dem Präfix "_col" (z. B. _col0, _col1), wobei das Dateischema mindestens ein verschachteltes Struktur-, Feld- oder Zuordnungsfeld enthält, können nicht importiert werden
Funktionen
Die folgenden Funktionen werden nicht unterstützt:
- MicroStrategy-Dateien werden hochgeladen und eine Verbindung mit Cloud Object Connector hergestellt
- Datenumbau beim Datenimport
- Definition des Standorts beim Datenimport
- Erweiterte Ablaufplanung für Cube-Veröffentlichung planen
- Tabellen beim Datenimport gruppieren