Strategy One
The Clustered Architecture
The diagram below shows report distribution in a four-tier clustered environment. The clustered Intelligence Servers are shown in gray.
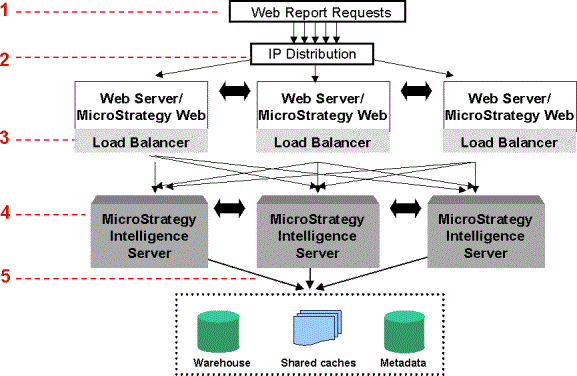
The node of the cluster that performs all job executions is the node that the client application, such as Developer, connects to. This is also the node that can be monitored by an administrator using the monitoring tools.
The following steps describe a typical job process in a clustered, four-tier environment. They correspond to the numbers in the report distribution flow diagram above.
- Strategy Web users log into a project and request reports from their Web browsers.
- A third-party IP distribution tool such as Cisco Local Router, Microsoft Network Load Balancing, or Microsoft Windows Load Balancing Service distributes the user connections from the Strategy Web clients among web servers.
- The Strategy Web product load balancers on each server collect load information from each cluster node and then connect the users to the nodes that carry the lightest loads and that run the project the user requested. All report requests are then processed by the nodes to which the users are connected.
- The Intelligence Server nodes receive the requests and process them. In addition, the nodes communicate with each other to maintain metadata synchronization and cache accessibility across nodes.
- The nodes send the requests to the warehouse as queries.
Query flow in a clustered environment is identical to a standard query flow in an unclustered environment (see Processing Jobs), with two exceptions:
- Result (report and document) caches and Intelligent Cubes: When a query is submitted by a user, if an Intelligent Cube or a cached report or document is not available locally, the server will retrieve the cache (if it exists) from another node in the cluster. For an introduction to report and document caching, see Result Caches. For an introduction to Intelligent Cubes, see Managing Intelligent Cubes.
- History Lists: Each user's History List, which is held in memory by each node in the cluster, contains direct references to the relevant cache files. Accessing a report through the History List bypasses many of the report execution steps, for greater efficiency. For an introduction to History Lists, see Saving Report Results: History List.