MicroStrategy ONE
조직 계층 가져오기
해당 기관의 HR 조직 계층을 Platform Analytics 프로젝트에 추가할 수 있습니다. HR 사용자 계층 애트리뷰트는 Platform Analytics 프로젝트의 사용자 레벨 분석을 강화하기 위해 사용됩니다. CSV 파일을 가져와서 HR 조직 계층에 해당하는 모든 애트리뷰트 및 테이블을 수동으로 제공해야 합니다.
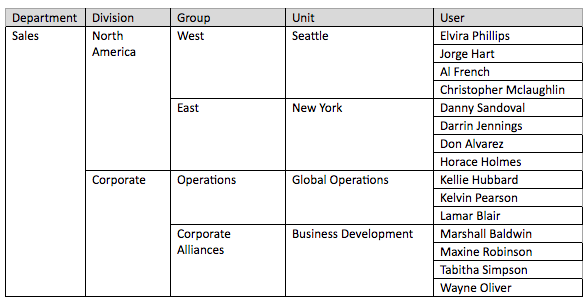
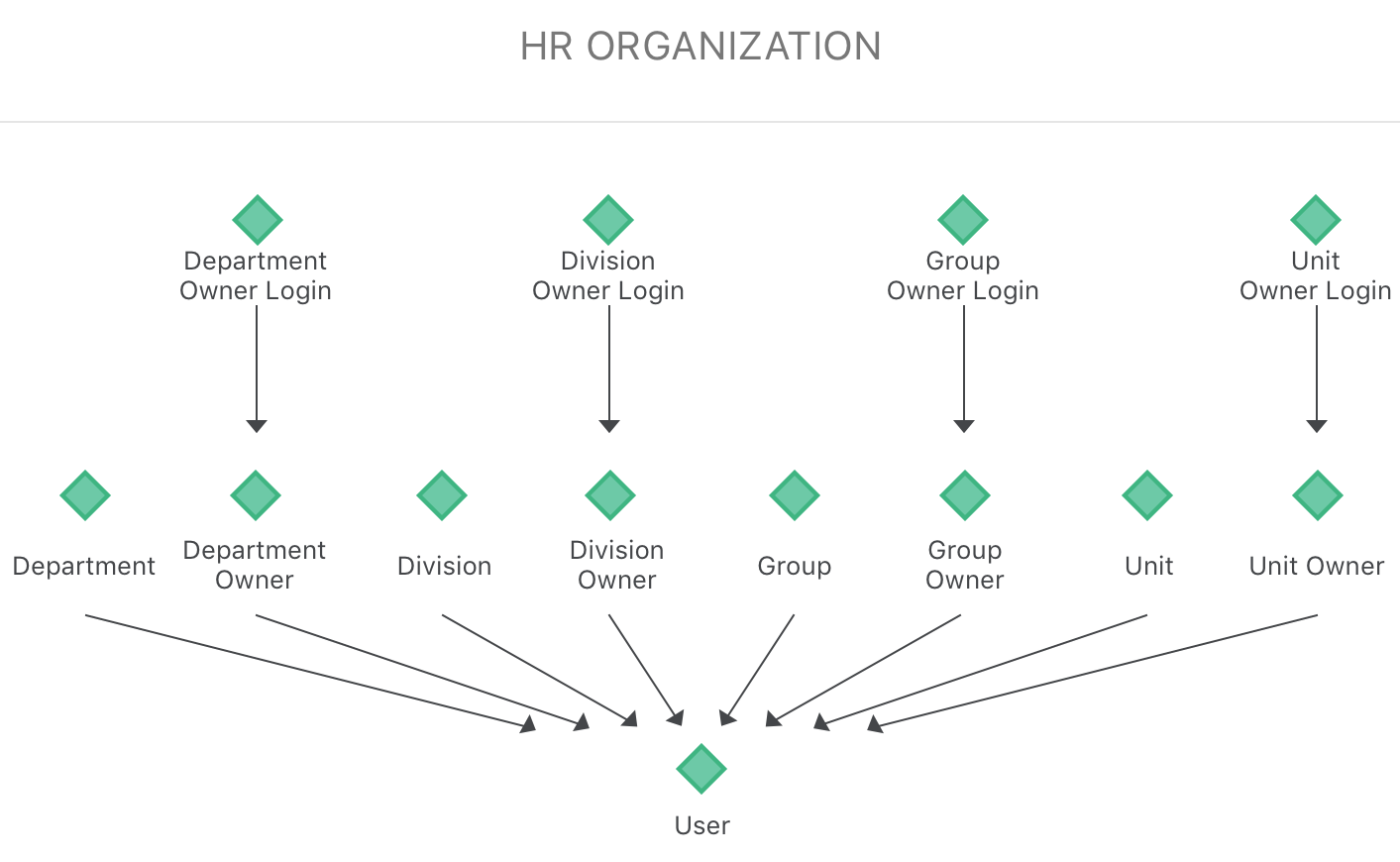
부서 애트리뷰트는 HR 조직 계층의 최상위 레벨 상위이며 여러 사업부가 통합된 것입니다. 계층 관계는 부서 > 사업부 > 그룹 > 유닛 > 사용자입니다. 로그인 애트리뷰트는 관리자와 그 직속 보고자만 사용할 수 있도록 데이터를 제한하는 보안 필터로 사용할 수 있습니다. 이러한 애트리뷰트와 테이블은 분석을 강화하기 위해 선택하여 사용할 수 있지만 Platform Analytics의 필수 기능은 아닙니다.
.CSV를 가져오기 전 파일에서 다음을 수행했는지 확인합니다.
- Platform Analytics 설치 및 구성. 자세한 내용은 Platform Analytics 설치를 참조하십시오.
- Platform Analytics 저장소에서 데이터베이스의 IP 주소 및 포트 찾기.
- Platform Analytics 데이터 저장소에 액세스할 수 있는 데이터베이스 사용자 자격 증명 획득.
- MySQL Workbench 6.3 이상 또는 그에 상응하는 데이터베이스 클라이언트 획득.
.CSV 준비 파일
데이터를 가져오기 전에 .CSV 파일에 다음과 같은 열 헤더가 있어야 합니다.
- employee_email: 직원의 이메일 주소입니다. 제공된 이메일 주소는 MicroStrategy 메타데이터 사용자 또는 사용자의 MicroStrategy 배지의 이메일 주소와 일치해야 합니다.
- department_desc: 조직의 부서 이름입니다. 예를 들어 영업, 재무, 기술 부서 등이 있습니다.
- department_owner_id: 부서 책임자의 직원 번호입니다. 부서 소유자는 해당 부서의 관리자입니다. 각 부서에는 한 명의 부서 소유자만 있을 수 있습니다.
- division_desc: 조직의 사업부 이름입니다. 예를 들어 북미 영업 사업부, 기업 재무 사업부 등이 있습니다. 사업부는 조직 계층 내의 여러 그룹을 하나로 통합한 것입니다.
- division_owner_id: 사업부 소유자의 직원 번호입니다. 각 사업부에는 한 명의 사업부 소유자만 있을 수 있습니다.
- group_desc: 조직의 그룹 이름입니다. 그룹은 조직 계층 내의 여러 유닛을 하나로 통합한 것입니다.
- group_owner_id: 그룹 소유자의 직원 번호입니다. 각 그룹에는 한 명의 그룹 소유자만 있을 수 있습니다.
- business_unit_desc: 그룹 유닛의 이름입니다. 유닛은 조직 계층 내 사용자의 상위 레벨입니다.
- business_unit_owner_id: 유닛 소유자의 직원 번입니다. 각 유닛에는 한 명의 유닛 소유자만 있을 수 있습니다.
- employee_first_name: 직원의 이름입니다.
- employee_last_name: 직원의 성입니다.
선택적인 열을 추가하여 Platform Analytics 프로젝트로 가져올 수 있습니다.
- ceo_employee_id: 조직의 CEO 직원 번호입니다.
- employee_id: 조직의 직원 번호입니다.
예 .CSV 파일
| employee_email | department_desc |
부서 소유자_id |
division_desc | division_owner_id | group_desc | group_owner_id | business_unit_desc | business_unit_owner_id | employee_first_name | employee_last_name |
|---|---|---|---|---|---|---|---|---|---|---|
| e1@email.com | HR | 1 | 채용 | 2 | 캠퍼스 | 3 | 동부 | 5 | Leisa | Drake |
| e2@email.com | HR | 1 | 채용 | 2 | 캠퍼스 | 3 | 서 | 5 | Vella |
일반 |
| e3@email.com | HR | 1 | 채용 | 2 | 캠퍼스 | 3 | 서 | 5 | Sofia | Strickler |
| e4@email.com | HR | 1 | 채용 | 2 | 기술 | 4 | 백엔드 | 5 | Fern |
Byun |
| e5@email.com | HR | 1 | 채용 | 2 | 기술 | 4 | 프런트엔드 | 5 | Dorthy | Gumps |
.CSV 가져오기 파일
- 다음 항목이 있는지 확인합니다. 이(가) .CSV를 준비했습니다. 개 파일을(를) 필요한 열 헤더로 포함합니다.
- MySQL Workbence 또는 이에 준하는 데이터베이스 클라이언트를 열고 platform_analytics_warehouse.
- Stg_employee 테이블을 마우스 오른쪽 버튼으로 클릭하고 Table Data Import Wizard(테이블 데이터 가져오기 마법사)를 선택합니다.
- 준비된 .CSV 선택 파일 및 클릭업로드 .
- Select Destination(대상 선택)에서 Use existing table(기존 테이블 사용)을 선택하고 드롭다운에서 stg_employee 테이블을 선택합니다.
- 다음을 클릭합니다.
- Configure Import Settings(가져오기 설정 구성) 대화 상자에서 .csv 파일이 올바로 업로드되었는지 확인합니다.
- 다음을 클릭합니다.
- 저장을 클릭합니다.
-
조직 계층을 즉시 채우려면 Platform Analytics Consumer를 다시 시작합니다.
사용자 누락 시 제안되는 문제 해결조직 계층을 가져온 후에는 각 직원이 이미 MicroStrategy 메타데이터에 있거나 MicroStrategy Badge를 보유하고 있어야 합니다. 가져오기 프로세스의 일부로 .csv 파일의 사용자가 stg_employee 테이블에 로드된 후 이메일 주소를 통해 lu_user 테이블에 맞추어 조직 계층 값이 추가됩니다.
가져오기 프로세스에서 stg_employee와 lu_user 간에 일치하는 이메일 주소를 찾지 못하는 경우 열이 stg_employee_reprocess에 삽입되어 누락된 사용자를 추적합니다. 이러한 누락된 사용자를 다시 가져오려면 .CSV에서 이메일 주소가 올바른지 확인합니다. 파일을 MicroStrategy 메타데이터 사용자 및 MicroStrategy Badge와 비교합니다. 이 값이 정확하면 환경이 올바르게 구성되었는지 확인합니다.
일치하지 않는 이메일 주소의 루트 원인을 해결한 경우 Platform Analytics 일별 ETLS 은(는) 누락된 사용자를 자동으로 해결합니다.
가져온 .CSV에서 생성된 리포트 예 파일