Version 2021
MicroStrategy에서 빅 데이터 분석
비즈니스 인텔리전스 및 분석 업계에서 빅 데이터는 주로 기존 시스템에서 처리할 수 없는 많은 양의 데이터를 사용하는 것과 관련이 있습니다. 빅 데이터에는 큰 데이터세트를 저장, 처리, 검색, 분석 및 시각화하기 위한 새로운 기술이 요구됩니다.
자세한 내용은 다음 항목을 참조하십시오.
새 사용자: 개요 – 빅 데이터에 대한 일반적인 소개를 제공합니다.
경험이 있는 사용자:
- MicroStrategy에서 빅 데이터 소스 연결 및 분석 – MicroStrategy를 사용하여 빅 데이터 소스에 연결하는 방법을 설명합니다.
- 빅 데이터 소스에 연결하는 작업 흐름의 예 – 연결 구성의 예를 보여 줍니다.
빅 데이터 개요
이 섹션에서는 빅 데이터에 대한 일반적인 소개와 함께 가장 일반적인 사용 사례 및 기술을 요약해 설명합니다. 다음 항목을 다룹니다.
빅 데이터 사용 사례
활성화된 빅 데이터 기술은 대량의 데이터 또는 복잡한 분석으로 인해 이전에는 불가능했던 사례를 가능하게 했습니다. 오늘날 빅 데이터를 통한 정보와 통찰력을 활용하면 다음과 같은 모든 비즈니스 유형에 유용합니다.
- 소매업체는 고객의 구매 행위, 현재 제품, 가격 및 프로모션에 대한 정보를 연결하여 보다 우수하고 맞춤화된 고객 서비스를 제공하려고 합니다. MicroStrategy에서 빅 데이터 분석을 실행하면 맞춤화된 관련 고객 환경을 제공하는 인적 정보를 저장할 수 있습니다.
- 제조업체는 높은 효율성, 낮은 가격 및 일관된 서비스 수준을 지속적으로 유지하면서 공급망에 따른 비용을 절감해야 합니다. 또한 소비자의 인구 통계 및 구매 행위와 관련된 제품 판매량을 조사하는 소비 분석도 필요합니다. 제조업체는 MicroStrategy를 통해 서로 다른 소스에 대한 빅 데이터 분석을 실행하여 완벽한 주문율과 품질을 얻을 수 있으며 자세한 소비 패턴을 알 수 있습니다.
- 통신사는 네트워크 사용량, 가입자 밀도와 트래픽 및 위치 데이터를 상호 연관시켜 네트워크 용량을 계획하고 최적화해야 합니다. MicroStrategy를 사용하는 통신사는 분석을 실행하여 네트워크 용량을 정확하게 모니터링하고 예측하며 정전 가능성에 효과적으로 대비하고 프로모션을 실행할 수 있습니다.
- 의료업체는 의료 기관이 보유한 페타바이트 단위의 환자 데이터를 사용하여 의약품 판매를 향상하고, 환자 분석을 개선하며, 더 나은 지불 솔루션을 제공하는 것을 목표로 합니다. MicroStrategy는 이러한 사용 사례를 만족시킬 수 있도록 응용 프로그램을 효과적으로 빌드하고 실행할 수 있습니다.
- 정부는 규모가 큰 작업 중에서도 안보 위협, 인구 동태, 예산 및 금융을 다룹니다. 복잡한 대량의 데이터세트에 대한 MicroStrategy의 분석 기능은 정부 인사에게 심도 있는 통찰력을 제공하여 정보에 입각한 정책 결정을 내리고, 비용의 낭비와 부정 행위를 없애고, 잠재적 위협을 식별하며, 시민의 미래를 대비할 수 있습니다.
빅 데이터의 특징
빅 데이터는 새로운 문제를 수반하며 이러한 문제를 처리하기 위해서는 새로운 접근 방법이 필요합니다. 빅 데이터 사용 사례를 가능하게 해주는 엔터프라이즈 개발 계획으로 빅 데이터의 5V 특징 5V(Volume, Variety, Velocity, Variability, Value)를 고려해야 합니다.
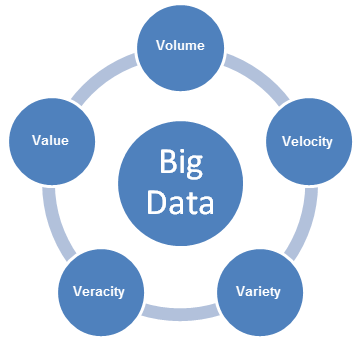
- Volume(볼륨)은 분석해야 할, 생성된 데이터 콘텐츠의 크기를 말합니다.
- Velocity(속도)는 새 데이터가 생성되는 속도 및 데이터가 이동하는 속도를 말합니다.
- Variety(다양성)는 분석할 수 있는 데이터의 유형을 말합니다. 이전에 분석 업계는 테이블 및 열에 맞는, 일반적으로 관계형 데이터베이스에 저장되는 구조적 데이터에 중점을 두었습니다. 하지만 이제 대부분의 데이터는 비구조적 데이터이며 쉽게 테이블에 추가할 수 없습니다. 더 넓은 차원에서 데이터는 다음 세 개의 범주로 나눌 수 있습니다. 각 범주의 데이터를 분석하려면 서로 다른 접근 방법이 필요합니다.
- 구조적 데이터는 구조가 알려진 데이터입니다. 파일이나 레코드 내의 고정 필드에 데이터가 있습니다.
- 비구조적 데이터는 정의된 데이터 모델 또는 구성이 없는 정보입니다. 텍스트 데이터(전자 메일 본문, 인스턴트 메시지, Word 문서, PowerPoint 프레젠테이션, PDF)일 수도 있고 텍스트가 아닌 데이터(오디오/비디오/이미지 파일)일 수도 있습니다.
- 반구조적 데이터는 구조적 데이터와 비구조적 데이터 사이의 교차 데이터입니다. 데이터가 이벤트 로그 데이터 또는 문자열 키-값 쌍과 같이 정확한 데이터 모델 없이 구조화됩니다.
- Veracity(진실성)는 데이터의 신뢰성을 말합니다. 빅 데이터의 여러 소스 및 폼을 사용하면 품질 및 정확성이 제어하기가 쉽지 않습니다.
- Value(가치)는 빅 데이터를 명확한 비즈니스 가치로 전환하는 기능을 말합니다. 의미 있는 출력 값을 위해서는 액세스 및 분석 권한이 필요합니다.
빅 데이터 채택 시 문제점
엔터프라이즈가 빅 데이터 시스템에 있는 정보를 찾기 위한 솔루션을 개발함에 따라 다음과 같은 문제가 발생합니다.
- 성능: 빅 데이터의 향상된 분석 기능을 구현하려는 조직은 대화형 성능을 갖추기 위해 노력합니다.
- 데이터 연합: 실제 응용 프로그램은 프로젝트 간에 데이터 통합을 필요로 합니다. 서로 다른 포맷으로 다양한 소스에 저장된 데이터를 연합하는 것은 쉽지 않습니다.
- 데이터 정리: 엔터프라이즈는 분석 준비 과정에서 다양한 데이터 폼을 정리하는 방법을 찾고 있습니다.
- 보안: 적절한 암호화 사용, 데이터 액세스 내역 기록, 다양한 업계 표준 인증 메커니즘을 통한 데이터 액세스를 비롯하여 대부분의 데이터 레이크 보안 유지를 도전 과제로 삼고 있습니다.
- 가치 창출 시간: 엔터프라이즈는 데이터로부터 가치를 창출하는 데 걸리는 시간을 줄이기 위해 상당히 애쓰고 있습니다. 다양한 데이터 유형의 수많은 소스를 처리하고 이를 위해 웹을 사용하여 해결하다 보면 상당한 시간이 소모됩니다.
Hadoop 구성 요소 개요
이 섹션에서는 Hadoop 에코시스템의 기본 구성 요소에 대해 설명합니다.
Apache Hadoop은 조직이 기존의 데이터베이스 데이터보다 더 큰 규모의 주문인 데이터를 저장하고 쿼리하여 비용 효율적인 방법으로 클러스터링된 환경에서 수행할 수 있도록 하는 분산 저장소 및 분산 처리를 위한 오픈 소스 소프트웨어 프레임워크입니다. 아래 그림은 Apache Hadoop 구성 요소의 아키텍처 다이어그램을 보여 줍니다.
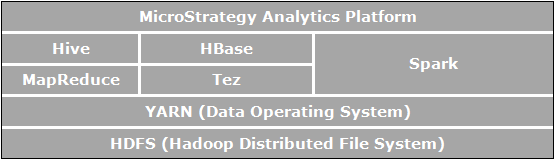
비즈니스 분석에 직접 관련되고 MicroStrategy를 통해 가능해진 사용 사례와 연관되는 요소는 다음과 같습니다.
- HDFS(Hadoop 분산 파일 시스템)는 상용 시스템의 클러스터에서 실행되는 Hadoop 응용 프로그램에서 사용하는 데이터 저장소 파일 시스템입니다. HDFS 클러스터는 파일 시스템 메타데이터를 관리하는 NameNode 및 실제 데이터를 저장하는 DataNode로 구성됩니다. HDFS를 사용하면 Hadoop 에코시스템 외부의 응용 프로그램에서 가져온 큰 파일의 저장소 및 가져온 파일의 스테이징을 Hadoop 응용 프로그램에서 처리할 수 있습니다.
- YARN(Yet Another Resource Negotiator)은 리소스 관리 기능을 제공하며 Hadoop에서 실행 중인 응용 프로그램에 대한 Hadoop 클러스터 간에 작업, 보안 및 데이터 관리 도구를 제공하는 중앙 플랫폼입니다.
- MapReduce는 상용 시스템의 큰 클러스터에서 실행되는 분산 데이터 처리 모델이며 실행 환경입니다. 모든 작업을 Map 및/또는 Reduce 함수로 세분화하는 MapReduce 알고리즘을 사용합니다.
- Tez는 MapReduce에 비해 성능이 향상된 SQL 쿼리 작업 흐름을 제공하도록 디자인된 일반 데이터 흐름 프로그래밍 프레임워크입니다.
- Hive는 대량의 데이터를 관리하고 구성할 수 있도록 HDFS의 맨 위에 작성된 분산 데이터 웨어하우스입니다. Hive는 대량의 원시 데이터를 보관하기 위해 구조화된 데이터 저장소를 제공하며 HDFS에서 원시 데이터에 대한 분석 및 쿼리 작업을 실행하기 위한 SQL과 같은 환경을 제공합니다, Hive의 SQL과 같은 환경은 Hadoop을 쿼리하는 가장 일반적인 방법입니다. 또한 Hive는 Map-Reduce, Tez, Spark 등과 같은 다양한 쿼리 엔진에 SQL 쿼리를 지시하는 데도 사용할 수 있습니다.
- Spark는 클러스터 계산 프레임워크입니다. Spark는 ETL, 기계 학습, 스트림 처리 및 그래프 계산을 비롯하여 광범위한 응용 프로그램을 지원하는 간단하고 효과적인 프로그래밍 모델을 제공합니다.
- HBase 열 지향 분산 데이터베이스입니다. 기본 저장소로 HDFS를 사용하고, 트랜잭션인 지점 쿼리(임의 읽기) 및 MapReduce를 사용하는 일괄 처리 스타일 계산을 지원합니다.
MicroStrategy에서 빅 데이터 소스 연결 및 분석
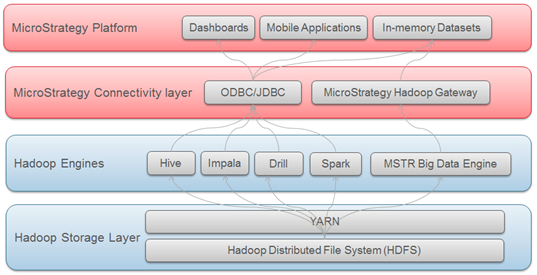
빅 데이터 에코시스템에는 사용자가 SQL 쿼리를 빅 데이터 소스에 전달하고 기존 관계형 데이터베이스와 마찬가지로 데이터를 분석할 수 있도록 해주는 많은 SQL 엔진(Hive, Impala, Drill 등)이 있습니다. 따라서 사용자는 SQL을 통해 구조적 데이터에 액세스할 때와 동일한 분석 프레임워크를 활용할 수 있습니다.
MicroStrategy는 여러 개의 빅 데이터 SQL 엔진과의 연결을 지원하고 인증합니다. 기존 데이터베이스와 유사하게 ODBC 또는 JDBC 드라이버를 통해 이러한 SQL 엔진에 연결합니다.
MicroStrategy는 사용자가 데이터를 Hadoop 파일 시스템(HDFS)에서 직접 가져올 수 있는 방법도 제공합니다. 이 방법은 MicroStrategy Hadoop Gateway를 사용하여 클라이언트가 SQL 쿼리 엔진을 무시하고 분석을 위해 파일 시스템에서 데이터를 직접 MicroStrategy 메모리 내부 큐브로 로드할 수 있도록 하는 방법입니다.
아래 다이어그램은 데이터가 Hadoop 시스템에서 MicroStrategy에 도달하기까지의 이동 레이어를 보여 줍니다.
데이터 액세스 모드 선택
MicroStrategy를 사용하면 빅 데이터 시스템과 BI 시스템의 리소스를 동시에 효과적으로 활용하여 분석을 실행하는 데 최상의 성능을 얻을 수 있습니다. 다음과 같은 옵션이 있습니다.
- 메모리로 데이터 가져오기(메모리 내부 접근법) - 분석할 데이터를 메모리 내부 큐브에서 단독으로 가져옵니다. MicroStrategy를 사용하여 최대 수백 GB인 데이터 하위 집합을 빅 데이터 소스에서 메모리 내부 큐브로 가져오고 큐브에서 리포트/관련 문서를 작성할 수 있습니다. 일반적으로 큐브는 정기적으로 게시되고 서버의 주 메모리에 저장되도록 설정되므로 빅 데이터 데이터베이스를 쿼리하는 데 많은 시간이 걸리지 않습니다.
- 해당 소스에서 직접 데이터에 액세스(실시간 연결 접근법) - 데이터가 데이터베이스에서 단독으로 액세스됩니다. MicroStrategy는 다양한 빅 데이터 소스에 연결하여 실시간으로 소스에 대해 리포트 및 관련 문서를 동적으로 실행할 수 있습니다.
- 하이브리드 접근법 채택 - 필요에 따라 메모리 내부 큐브 및 데이터베이스에서 데이터를 가져옵니다. 하이브리드 접근법은 사용자가 제출한 쿼리에 따라 접근법을 원활하게 전환할 수 있도록 하여 위의 강력한 두 가지 방법을 효과적으로 활용합니다. MicroStrategy는 큐브 또는 데이터베이스가 특정 쿼리에 응답할 수 있는지 여부를 자동으로 결정하고 그에 맞게 쿼리를 지시할 수 있는 동적 소싱 기술을 보유하고 있습니다.
다음은 세 접근법을 요약한 그림입니다.
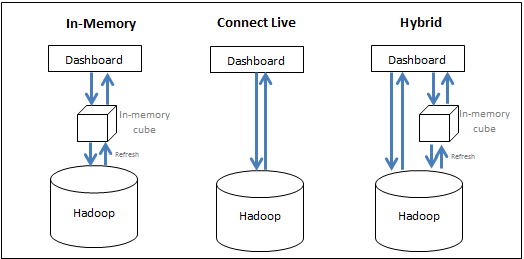
일반적으로 메모리 내부 접근법이 가장 빠른 분석 성능을 보여 주지만 대량의 데이터로 인해 실용적이지 않을 수 있습니다. 다음 섹션에서는 데이터 액세스 방법을 결정할 때의 디자인 고려 사항에 대해 설명합니다.
- 메모리 내부 접근법: 이 접근법은 더 빠른 성능을 제공하지만 주 메모리에 맞는 소규모 집합의 데이터로 제한되며 메모리 내부 데이터의 업데이트 빈도에 따라 데이터가 오래된 것일 수 있습니다. 이 접근법은 다음 경우에 사용합니다.
- 최종 데이터가 집계 폼에 있고 BI 시스템의 주 메모리에 맞는 경우
- 대화형 분석에서 데이터베이스가 너무 느린 경우
- 사용자가 트랜잭션 데이터베이스의 부하를 제거해야 하는 경우
- 사용자가 오프라인이어야 하는 경우
- BI 레벨에서 데이터 보안이 설정될 수 있는 경우
- 실시간 연결 접근법: 관련 문서의 데이터가 현재 상태를 유지해야 하는 경우 또는 모든 데이터가 메모리 내부 큐브에 저장될 수 없는 세부 수준의 데이터인 경우에는 실시간 연결 옵션을 사용하여 관련 문서를 작성하는 것이 적합한 접근법이 될 수 있습니다. 이렇게 하면 실행할 때마다 웨어하우스에서 최신 데이터를 가져올 수 있습니다. 이 접근법은 보안이 데이터베이스 레벨로 설정되고 웨어하우스 실행 시 각 사용자의 액세스 권한이 있는 데이터가 표시되어야 할 경우에도 유용합니다. 이 접근법은 다음 경우에 사용합니다.
- 데이터베이스가 빠르고 즉각적인 경우
- 사용자가 데이터베이스에서 자주 업데이트되는 데이터에 액세스하는 경우
- 데이터 볼륨이 메모리 내부 제한보다 큰 경우
- 사용자가 미리 실행된 관련 문서를 예약 전송하려는 경우
- 데이터 보안이 데이터베이스 레벨에서 설정된 경우
- 하이브리드 접근법: 이 접근법은 관련 문서의 시작 화면에서 사용자가 세부 사항으로 드릴할 수 있는 고급 집계 정보가 포함된 사용 사례의 경우에 적합합니다. 이 경우 관리자는 메모리 내부 큐브에 집계 데이터를 게시하여 Dossier의 기본 화면이 빠르게 표시되도록 하고 사용자가 드릴 다운할 때 빅 데이터 시스템의 하위 레벨 데이터에 대한 Dossier가 표시되도록 할 수 있습니다. MicroStrategy의 동적 소싱 기능은 선택한 리포트를 큐브로 전환할 수 있고 사용자가 요청 중인 데이터에 따라 큐브 또는 데이터베이스에 대해 실행할 것인지 여부를 MicroStrategy가 자동으로 결정하기 때문에 이러한 응용 프로그램을 쉽게 작성할 수 있게 해줍니다.
지원되는 빅 데이터 드라이버 및 공급업체
Hadoop SQL 엔진은 특정 데이터 조작에 최적화되어 있습니다. 데이터 액세스를 위해 실행된 쿼리 및 데이터 유형을 기반으로 사용 사례를 다음 5개의 그룹으로 나눌 수 있습니다.
- 일괄 처리 SQL – 빅 데이터에서 대규모 변형 수행에 사용됩니다.
- 대화형 SQL - 빅 데이터에서 대화형 분석을 사용합니다.
- NoSQL – 일반적으로 대규모 데이터 저장소 및 빠른 트랜잭션 쿼리에 사용됩니다.
- 비구조적 데이터/검색 엔진 – 텍스트 데이터 또는 로그 데이터를 분석하고 주로 검색 기능을 사용합니다.
- 데이터 정리 및 메모리에 로드/Hadoop Gateway – 빠른 메모리 내부 큐브 게시에 주로 사용되고 최적화됩니다.
다음은 사용 사례 간의 매핑 및 현재 MicroStrategy에서 지원되는 엔진을 보여 주는 그림입니다.
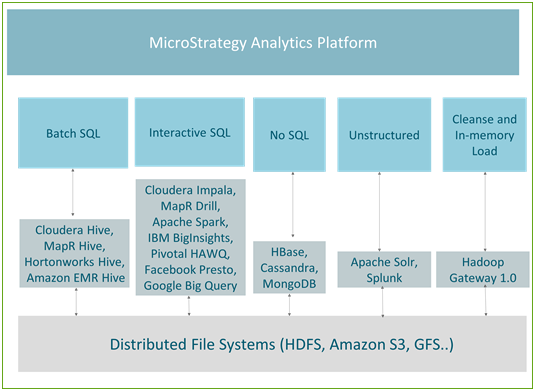
일괄 처리
Hive는 일괄 처리를 위해 가장 많이 사용되는 쿼리 메커니즘입니다. 내결함성이 있으므로 ETL 유형의 작업에 권장됩니다. 모든 주요 Hadoop 배포판(예: Hortonworks, Cloudera, MapR 및 Amazon EMR)에서는 Hive ODBC 커넥터를 제공합니다. MicroStrategy는 위의 모든 Hadoop 공급업체와 파트너 관계를 맺고 있으며 Hive를 통해 Hadoop에 인증 연결을 제공합니다.
Hive는 MicroStrategy에서 메모리 내부 접근법과 함께 사용하거나 배포 서비스와 연결될 때 실시간 접근법의 일부로 사용하여 데이터베이스 대기 시간이 최종 사용자에게 영향을 미치지 않도록 하는 좋은 엔진입니다. MapReduce를 사용하여 쿼리를 처리하므로 일괄 처리의 대기 시간이 길어 대화형 쿼리에는 적합하지 않습니다.
다음 표에는 지원되는 Hive 배포에 대한 연결 정보가 나와 있습니다.
| 공급업체 | 연결 | 사용 사례 | 드라이버 이름 | 작업 흐름 |
|---|---|---|---|---|
| Cloudera Hive | ODBC | SQL을 가져와 MapReduce로 변환하는 도구이며 데이터에서 ETL과 같은 대규모 변환을 수행하는 데 사용할 수 있습니다. | MicroStrategy Hive ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Hortonworks Hive |
ODBC |
SQL을 가져와 MapReduce로 변환하는 도구이며 데이터에서 ETL과 같은 대규모 변환을 수행하는 데 사용할 수 있습니다. | MicroStrategy Hive ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| MapR Hive | ODBC | SQL을 가져와 MapReduce로 변환하는 도구이며 데이터에서 ETL과 같은 대규모 변환을 수행하는 데 사용할 수 있습니다. | MicroStrategy Hive ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Amazon EMR Hive | ODBC | SQL을 가져와 MapReduce로 변환하는 도구이며 데이터에서 ETL과 같은 대규모 변환을 수행하는 데 사용할 수 있습니다. | MicroStrategy Hive ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
대화형 쿼리
여러 Hadoop 공급업체에서 대화형 쿼리를 사용할 수 있도록 하는 빠른 수행 엔진을 개발했습니다. 이러한 엔진은 공급업체/기술 특정 메커니즘을 사용하여 HDFS를 쿼리하지만 Hive를 계속 metastore로 사용합니다. 이러한 모든 기술은 고급 분석 기능과 함께 큰 데이터세트에서 더 빠른 응답 시간을 제공하도록 빠르게 발전하고 있습니다. Impala, Drill 또는 Spark 같은 대화형 엔진은 MicroStrategy Dossier과(와) 효율적으로 연결하여 Hadoop에서 셀프서비스 데이터 검색을 사용할 수 있습니다. 엔진은 MicroStrategy와 함께 작동하도록 인증되었습니다.
다음 표에는 지원되는 배포에 대한 연결 정보가 나와 있습니다.
| 공급업체 | 연결 | 사용 사례 | 드라이버 이름 | 작업 흐름 |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Apache Hadoop을 실행 중인 컴퓨터 클러스터에 저장된 데이터에 대한 오픈 소스 MPP(대규모 병렬 처리) SQL 쿼리 엔진입니다. Impala는 고유한 처리 엔진을 사용하며 메모리 내부 작업을 수행할 수 있습니다. | MicroStrategy Impala ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Apache Drill | ODBC | MapR에서 지원되는 대기 시간이 짧은 오픈 소스 쿼리 엔진입니다. 셀프 서비스 데이터 탐색 기능을 제공할 수 있도록 즉시 스키마를 검색하는 기능이 있습니다. | MicroStrategy Drill ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Apache Spark | ODBC | 가장 큰 오픈 소스 커뮤니티 중 하나에서 개발한, 분산 데이터 컬렉션에서 작동하는 데이터 처리 도구입니다. 메모리 내부 처리를 사용하며 Spark가 MapReduce보다 더 빠릅니다. | Apache Spark SQL용 MicroStrategy ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| IBM BigInsights | ODBC | 엔터프라이즈가 Hadoop에서 기본 형식으로 대량의 구조적 및 비구조적 데이터를 분석할 수 있는 풍부한 고급 분석 기능 집합입니다. | BigInsights ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Pivotal HAWQ | ODBC | 기본적으로 HDFS에 데이터를 읽고 쓰는 병렬 SQL 쿼리 엔진입니다. 사용자에게 전체 ANSI 표준 호환 SQL 인터페이스를 제공합니다. | Greenplum Wire Protocol용 MicroStrategy ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Google BigQuery | ODBC | Google 인프라를 활용하여 사용자가 페타바이트 단위의 데이터를 대화형으로 쿼리할 수 있는 클라우드 기반 서비스입니다. | MicroStrategy Google BigQuery ODBC 드라이버 | MicroStrategy Architect 및 MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
NoSQL 소스
NoSQL 소스는 큰 정보 저장소 및 트랜잭션 쿼리에 최적화됩니다. NoSQL 소스는 MicroStrategy에서 다중 소스 옵션 또는 데이터 혼합 옵션과 효과적으로 연결하여 기존의 데이터베이스에서 상위 레벨 정보를 사용자에게 표시하고 NoSQL 소스를 사용하여 NoSQL 소스와 통합을 통해 최저 레벨 트랜잭션 데이터로 드릴 다운하는 기능을 제공합니다.
다음 표에는 MicroStrategy에서 인증 연결을 제공하는 NoSQL 소스가 나와 있습니다.
| 공급업체 | 연결 | 사용 사례 | 드라이버 이름 | 작업 흐름 |
|---|---|---|---|---|
| Apache Cassandra | JDBC | 모든 데이터가 인덱싱된 키와 값으로 구성되는 키 값 저장소입니다. | Cassandra JDBC 드라이버 | MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| HBase | JDBC | 데이터를 행에 저장하지 않고 테이블에 데이터 열 섹션으로 저장하는 열 저장소 NoSQL 데이터베이스입니다. 뛰어난 성능과 확장 가능한 아키텍처를 제공합니다. | Phoenix JDBC 드라이버 | MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| MongoDB | ODBC | 기존의 테이블 기반 관계형 데이터베이스 구조가 아닌 문서 지향 데이터베이스로, 특정 유형의 응용 프로그램에서 더 쉽고 빠르게 데이터를 통합합니다. | MicroStrategy MongoDB ODBC 드라이버 | MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
비구조적 데이터/검색 엔진
검색 엔진은 사용자가 대량의 텍스트 데이터를 통해 검색하고 해당 관련 문서 내의 데이터에 컨텍스트를 추가할 수 있는 효과적인 도구입니다. MicroStrategy에서 데이터 혼합과 함께 활용할 때 강력한 기능을 제공하며, 검색 데이터가 기존의 엔터프라이즈 소스와 연결될 수 있습니다.
다음 표에는 지원되는 Hive 배포에 대한 연결 정보가 나와 있습니다.
| 공급업체 | 연결 | 사용 사례 | 드라이버 이름 | 작업 흐름 |
|---|---|---|---|---|
| Apache Solr | 기본 | 전체 텍스트 검색, 패싯 검색 및 실시간 색인을 허용하는 가장 많이 사용되는 오픈 소스 검색 엔진입니다. MicroStrategy는 Solr과 통합하기 위한 커넥터를 작성했습니다. 이 커넥터는 Solr에서 색인화된 데이터에 대해 동적 검색을 수행하고 분석 및 시각화하는 기능을 제공합니다. | 내장 | MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
| Splunk Enterprise | ODBC | 광범위하게 사용되는 자체 검색 엔진입니다. | Splunk ODBC 드라이버 | MicroStrategy 데이터 가져오기를 통해 지원됩니다. |
MicroStrategy Hadoop Gateway
MicroStrategy는 Hadoop Gateway를 사용하여 HDFS에 대한 기본 연결을 제공합니다. Hadoop Gateway는 Hive를 무시하고 HDFS에서 직접 데이터에 액세스합니다. Hadoop Gateway는 HDFS 노드에 별도로 설치됩니다.
Hadoop Gateway는 Hadoop에 연결할 때 큰 메모리 내부 큐브를 만드는 사용 사례를 최적화하도록 디자인되었습니다. 다음 기술을 사용하여 Hadoop에서 효과적인 일괄 데이터 가져오기를 수행할 수 있습니다.
- Hive를 무시하고 데이터에 직접 액세스: Hive/ODBC를 무시하고 Yarn 응용 프로그램으로 실행 중인 HDFS와 기본적으로 연결합니다. 이렇게 하면 데이터 쿼리 및 액세스 시간이 줄어듭니다.
- HDFS에서 데이터 병렬 로드: 병렬 스레드를 통해 MicroStrategy Intelligence Server로 데이터를 로드하여 처리량은 많아지고 로드 시간은 감소합니다.
- 메모리 내부 사용 사례에 대한 데이터 정리 푸시다운 활성화: 데이터 랭글링 작업이 Hadoop에서 실행되어 대규모로 랭글링을 사용할 수 있습니다.
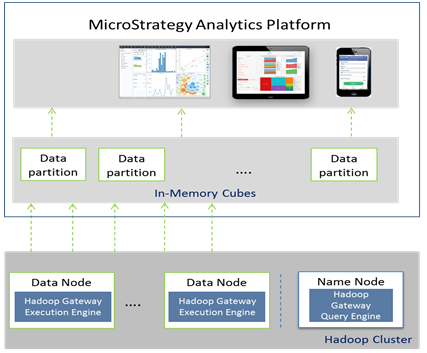
Hadoop Gateway의 아키텍처 개요
- Hadoop Gateway는 MicroStrategy 소유의 별도 설치 프로그램이며 다음을 설치하여 HDFS 데이터 및 이름 노드에 설치해야 합니다.
- HDFS 이름 노드에 Hadoop Gateway 쿼리 엔진 설치
- HDFS 실행 엔진에 Hadoop Gateway 실행 엔진 설치
- MicroStrategy Intelligence Server에서 Hadoop Gateway 실행 엔진으로 쿼리를 보내면 쿼리를 구문 분석하여 처리를 위해 데이터 노드로 보냅니다. 그런 다음 쿼리에서 가져온 데이터가 데이터 노드에서 MicroStrategy Intelligence Server에 병렬 스레드로 푸시되어 메모리 내부 큐브에 게시됩니다.
다음 그림은 아키텍처 다이어그램의 MicroStrategy Hadoop Gateway를 보여 줍니다.
Hadoop Gateway 제한
현재 Hadoop Gateway에는 다음과 같은 몇 가지 제한이 있습니다.
- 텍스트 및 csv 파일만 지원됩니다.
- 데이터 랭글링은 메모리 내부 사용 사례에만 지원됩니다.
- 다중 테이블 데이터 가져오기는 지원되지 않습니다.
- 분석 기능에서는 집계 및 필터링만 지원됩니다. JOIN 작업은 지원되지 않습니다.
- 공유 서비스 사용자 및 특정 사용자에 대한 위임의 경우 Kerberos 보안이 지원됩니다.
빅 데이터 소스에 연결하는 작업 흐름의 예
이 섹션에는 MicroStrategy에서 빅 데이터 소스에 연결하기 위한 다양한 작업 흐름의 예가 나와 있습니다.
- Web 데이터 가져오기를 통해 Hortonworks Hive에 연결하려면
- Web 데이터 가져오기를 통해 Hortonworks Hive에 연결하려면
- Hadoop Gateway를 통해 연결하려면
Developer를 통해 Hortonworks Hive에 연결
비즈니스 인텔리전스 관리자/개발자는 MicroStrategy Developer를 사용하여 아래에 설명된 단계에 따라 빅 데이터 소스에 연결할 수 있습니다. 작업 흐름은 기존의 데이터베이스가 MicroStrategy와 통합되는 방법과 유사합니다. 다음과 같이 개념에 따라 세 가지 단계로 구분할 수 있습니다.
- MicroStrategy에서 소스에 대한 연결을 만듭니다. 적절한 연결 세부 사항이 포함된 ODBC 데이터 소스 만들기 및 ODBC 소스를 가리키는 데이터베이스 인스턴스 개체 만들기가 여기에 포함됩니다.
- 웨어하우스 카탈로그 인터페이스를 통해 소스에서 테이블을 가져옵니다.
- 리포트 및 Dossier 작성에 필요한 스키마 개체(예: 속성, 팩트)를 만듭니다.
아래 단계에 Hortonworks Hive의 예가 나와 있습니다.
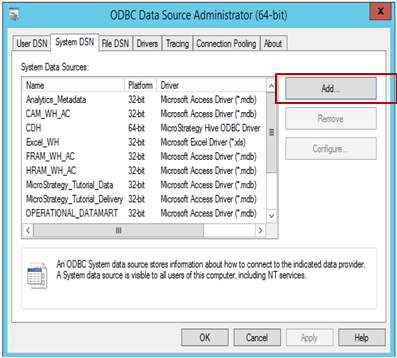
MicroStrategy에서 소스에 대한 연결을 만들려면:
-
소스에 대한 데이터 소스 연결을 만들기 위해 ODBC 데이터 원본 관리자를 엽니다. 추가를 클릭하여 새 연결을 만듭니다.
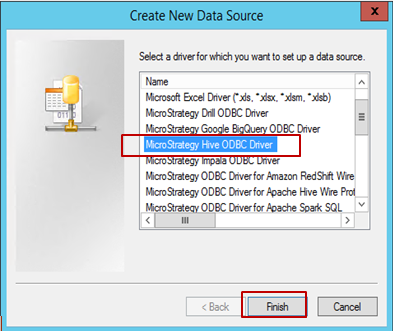
-
드라이버(이 예에서는 Hive ODBC가 선택됨)를 선택하고 완료를 클릭합니다.
-
해당 연결 세부 사항을 입력합니다.
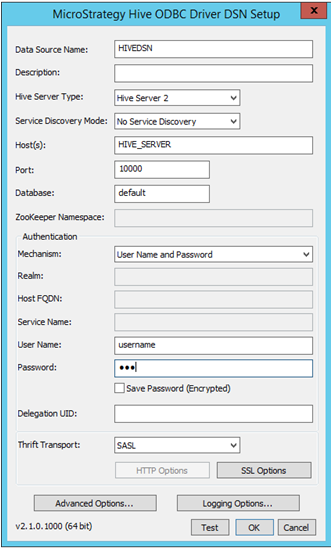
- 데이터 소스 이름: 연결이 저장되는 이름입니다.
- 설명: 선택 사항
- Hive 서버 유형: 환경별로 서버를 선택합니다.
-
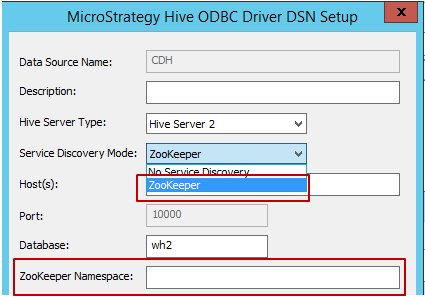
서비스 검색 모드: 아래 그림과 같이 사용할 수 있는 두 개의 서비스 검색 모드가 있습니다. ‘Zookeeper’를 선택하면 아래와 같이 Zookeeper 네임스페이스에 입력할 수 있습니다.
- 호스트, 포트 및 데이터베이스 이름: 환경별로 입력하는 필수 필드입니다.
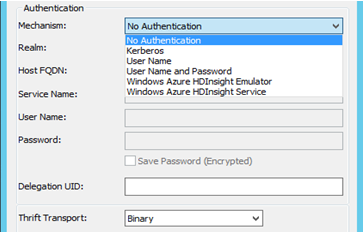
- 인증: MicroStrategy는 Hortonworks Hive에 대해 다양한 인증 메커니즘(인증 없음, Kerberos, 사용자 이름, 사용자 이름 및 암호)을 인증합니다. 선택한 메커니즘에 따라 Thrift 전송 매개 변수가 변경됩니다. 예를 들면 다음과 같습니다.
- 인증 없음 - Thrift 전송 매개 변수는 ‘Binary’입니다.
- Kerberos - Thrift 전송 매개 변수는 ‘SASL’입니다.
사용자 이름, 사용자 이름 및 암호 - Thrift 전송 매개 변수는 ‘SASL’입니다.
- 연결 세부 사항을 선택하고 입력한 후 ‘테스트’ 버튼을 사용하여 테스트할 수 있습니다.
-
MicroStrategy Developer를 엽니다. 프로젝트에 로그인 -> 구성 관리자로 이동 -> 데이터베이스 인스턴스 -> 새 데이터베이스 인스턴스 만들기를 수행합니다.
Windows에서 MicroStrategy Developer를 처음 실행하는 경우 관리자 권한으로 실행하십시오.
프로그램 아이콘을 마우스 오른쪽 버튼으로 클릭하고 관리자 권한으로 실행.
이는 Windows 레지스트리 키를 올바르게 설정하는 데 필요합니다. 자세한 내용은 KB43491을 참조하십시오.
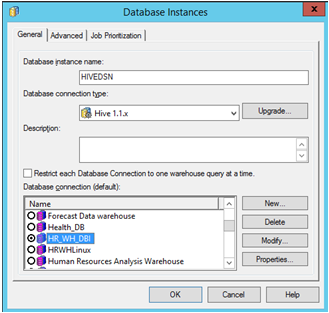
소스의 경우 이전에 만든 ‘데이터 소스 이름’을 선택합니다. 필수 사용자 로그인 및 암호를 입력합니다.
-
소스에서 테이블을 가져옵니다. 스키마로 이동 -> 웨어하우스 카탈로그 -> 데이터베이스 인스턴스 선택 -> 소스에서 필요한 테이블을 드래그 앤 드롭합니다.
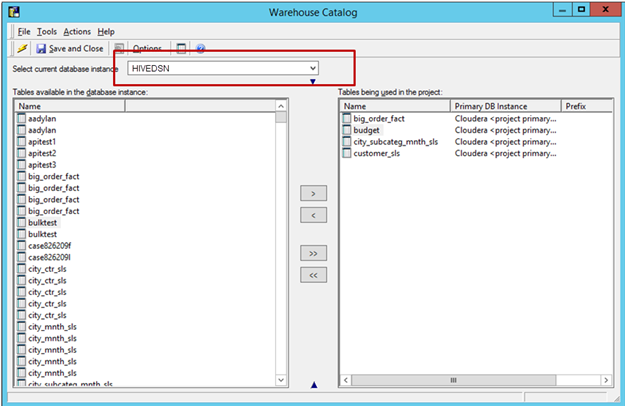
카탈로그를 저장하고 닫습니다.
-
필요에 따라 속성 및 메트릭을 작성합니다. 새 MicroStrategy 리포트를 시작하여 분석을 작성합니다.
Web 데이터 가져오기를 통해 Hortonworks Hive에 연결하려면
비즈니스 분석가 및 최종 사용자는 MicroStrategy Web 데이터 가져오기 작업 흐름을 활용하여 관계형 데이터 소스와 마찬가지로 데이터를 연결하고 분석할 수 있습니다. 세 가지 개념, 즉 연결, 가져오기 및 분석으로 나눌 수 있습니다.
MicroStrategy Web 데이터 가져오기에서 Hortonworks Hive에 연결하는 연결 창이 아래에 나와 있습니다.
-
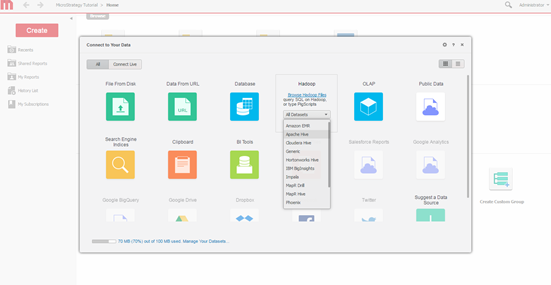
쿼리 엔진을 선택합니다. MicroStrategy 데이터 가져오기 화면을 통해 연결할 엔진을 선택합니다.
-
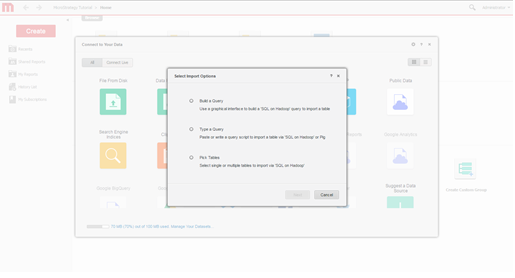
가져오기 옵션을 선택합니다. 쿼리 작성, 쿼리 입력 또는 테이블 선택 여부를 선택합니다. MicroStrategy의 모델링 기능을 최대한 활용할 수 있으므로 테이블 선택 접근 방법이 권장됩니다.
-
연결을 만듭니다. Hadoop 시스템에 대한 새 연결을 정의합니다.
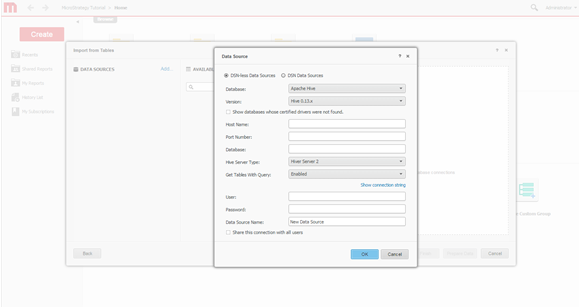
-
테이블을 선택합니다. 데이터에 액세스할 테이블을 선택합니다.
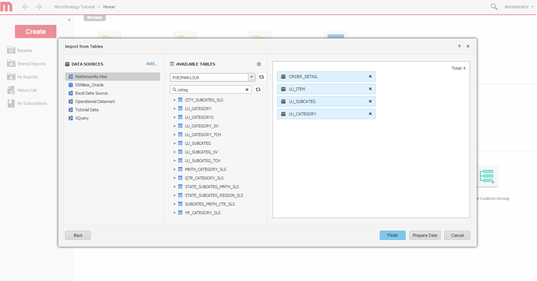
-
데이터를 모델링합니다. 필요에 따라 테이블을 모델링하고 속성 및 메트릭의 이름을 변경하고 가져오기에서 열을 제외합니다.
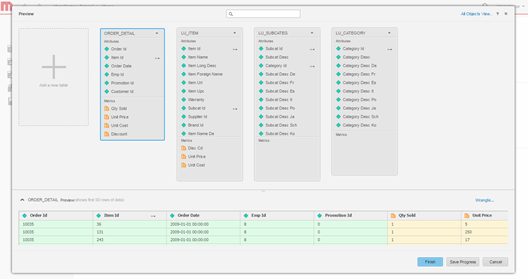
-
데이터 액세스 모드를 정의합니다. 데이터를 메모리 내부 큐브로 게시할지 아니면 실시간 연결 모드를 통해 게시할지 선택합니다.
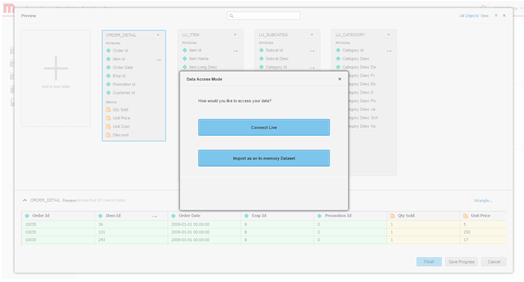
- 관련 문서를 작성합니다.
Hadoop Gateway를 통해 연결하려면
일반적인 데이터 가져오기 작업 흐름에 따라 MicroStrategy Web 데이터 가져오기에서 Hadoop Gateway를 활용할 수 있습니다.
- Hadoop/HDFS 클러스터에 대한 연결을 만듭니다.
- HDFS에서 폴더를 찾아 가져옵니다.
- 데이터를 정리합니다(선택 사항).
- MicroStrategy Intelligence Server에서 데이터를 메모리 내부 큐브로 게시하고 관련 문서를 통해 데이터를 분석합니다.
각 단계에 대한 세부 사항은 아래와 같습니다.
-
연결을 만듭니다.
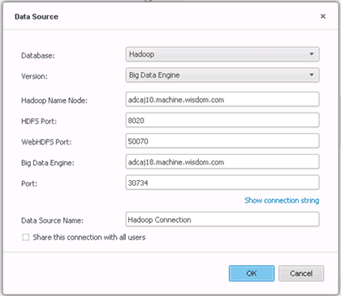
-
가져올 테이블을 선택합니다.
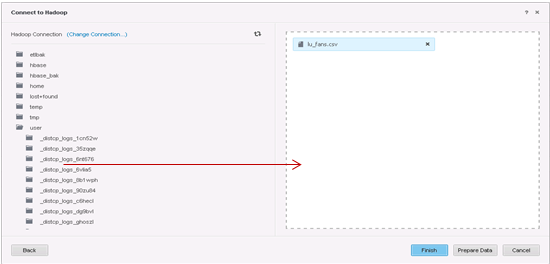
-
Data Wrangler를 사용하여 데이터를 준비합니다.
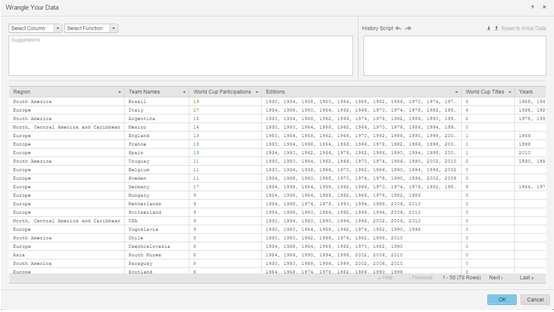
- 다음 단계는 메모리 내부 큐브를 MicroStrategy Intelligence Server에 게시하고 시각적 인사이트 인터페이스를 사용하여 관련 문서를 작성하는 것입니다.