Version 2021
Analyse des données volumineuses dans MicroStrategy
Dans le secteur Business Intelligence et de l’analyse, les données volumineuses impliquent l’utilisation de grands volumes de données qui ne peuvent pas être traités par des systèmes traditionnels. Les données volumineuses nécessitent de nouvelles technologies pour stocker, traiter, rechercher, analyser et visualiser de grands ensembles de données.
Pour plus d’informations, voir les sections ci-après :
Nouveaux utilisateurs : Présentation : fournit une introduction générale aux données volumineuses
Utilisateurs expérimentés
- Connexion et analyse des sources du Big Data dans MicroStrategy : aborde la façon d’utiliser MicroStrategy pour se connecter à des sources de données volumineuses
- Exemple de workflows pour connexion à des sources du Big Data : affiche des exemples de configuration de connexion
Présentation du Big Data
Cette section sert d’introduction générale aux données volumineuses et résume la terminologie et les cas d’utilisation les plus courants. Elle couvre les rubriques suivantes :
- Cas d'utilisation pour le Big Data
- Caractéristiques du Big Data
- Défis liés à l'adoption du Big Data
- Présentation des composants Hadoop
Cas d'utilisation pour le Big Data
Les technologies des données volumineuses ont permis des cas d’utilisation qui n’étaient pas possibles avant, soit à cause des volumes importants de données, soit à cause des analyses complexes. Maintenant, l’exploitation des informations et des aperçus dans les données volumineuses aide tous les types d’activités :
- Les commerçants veulent offrir un service client personnalisé et supérieur en ciblant des associés avec des informations sur le comportement d’achat des clients, les produits en cours, la tarification et les promotions. L’exécution d’analyse de données volumineuses avec MicroStrategy peut aider les employés d’un magasin à offrir une expérience client personnalisée et pertinente.
- Les fabricants font constamment face à une demande de plus d’efficacité, de prix inférieurs et de niveaux de service durables, ce qui les force à réduire les coûts tout au long de la chaîne d’approvisionnement. Ils ont également besoin d’analyses de consommation en examinant les ventes de produits par rapport à la démographie des consommateurs et les comportements d’achat. A l’aide de MicroStrategy, les fabricants peuvent exécuter des analyses de données volumineuses sur diverses sources pour atteindre des taux de commandes et une qualité d’exception et pour obtenir des modèles de consommation détaillés.
- Telcos a besoin d’optimisation et de planification de capacités réseau en corrélant l’utilisation du réseau, la densité des abonnés, en plus des données sur le trafic et l’emplacement. Telcos utilisant MicroStrategy peut exécuter des analyses pour surveiller et prévoir avec précision les capacités du réseau, planifier efficacement les coupures potentielles et lancer des promotions.
- Le secteur de la santé vise à utiliser les pétaoctets de données de patients dont disposent les organismes de santé pour améliorer les ventes pharmaceutiques, ainsi que les analyses de patients, et mettre en place de meilleurs solutions pour les payeurs. MicroStrategy peut créer et exécuter efficacement des applications pour aider à satisfaire ces cas d’utilisation.
- Les gouvernements gèrent les menaces de sécurité, les dynamiques de la population, les budgets et le finances parmi les opérations à grande échelle. Les capacités analytiques de MicroStrategy sur de larges jeux de données complexes peuvent fournir aux employés gouvernementaux des informations détaillées leur permettant de prendre des décisions de politiques informées, d'éliminer les gâchis et les fraudes, d'identifier des menaces potentielles et de planifier les besoins futurs des citoyens.
Caractéristiques du Big Data
Les données volumineuses apportent de nouveaux défis et nécessitent de nouvelles approches pour les gérer. Comme les entreprises développent des plans pour permettre des cas d’utilisation de données volumineuses, elles doivent prendre en compte les caractéristiques 5V des données volumineuses : Volume, Variété, Vélocité, Variabilité et Valeur.
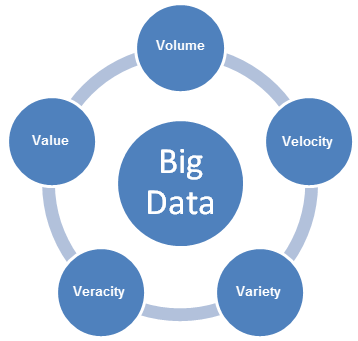
- Volume fait référence à la taille du contenu des données générées à analyser.
- Vélocité fait référence à la vitesse à laquelle les nouvelles données sont générées et à la vitesse à laquelle les données se déplacent.
- Variété fait référence aux types de données qui peuvent être analysés. Auparavant, le secteur de l’analyse se concentrait sur les données structurées qui s’ajustent dans des tables et des colonnes et étaient généralement stockées dans des bases de données relationnelles. Cependant, la plupart des données dans le monde sont maintenant non structurées et ne peuvent pas facilement être ajustées dans des tables. À un niveau plus large, les données peuvent être divisées en trois catégories. Chacune d’elles requiert différentes approches pour analyser les données
- Les données structurées sont des données dont la structure est inconnue. Les données résident dans un champ fixe dans un fichier ou un enregistrement.
- Les données non structurées sont des informations qui n’ont pas de modèle ou d’organisation de données défini. Les données peuvent être textuelles (corps d’e-mail, messages instantanés, documents Word, présentations PowerPoint, PDF) ou non textuelles (fichiers audio/vidéo/image).
- Les données semi-structurées sont un mélange de données structurées et non structurées. Les données sont structurées sans un modèle de données stricte, telles que les données de journaux d’événement ou les chaînes de paires de valeurs clés.
- La véracité fait référence à la fiabilité des données. Avec de si nombreuses sources et formes de données volumineuses, la qualité et la précision sont moins contrôlables.
- La valeur fait référence à la possibilité de transformer les données volumineuses en valeur professionnelle claire, ce qui nécessite un accès et une analyse pour produire un résultat significatif.
Défis liés à l'adoption du Big Data
Comme les entreprises développent des solutions pour extraire les informations présentes dans leurs systèmes de données volumineuses, elles font face aux défis suivants :
- Performances : Les organisations recherchant à implémenter des analyses avancées sur les données volumineuses ont des difficultés à atteindre des performances interactives.
- Fédération des données : Les applications concrètes nécessitent l’intégration des données sur l’ensemble des projets. Il est difficile de fédérer des données stockées dans divers formats et différentes sources.
- Nettoyage des données : Les entreprises trouvent qu’il est laborieux de nettoyer diverses formes de données lors de la préparation d’analyses.
- Sécurité : Conserver la sécurité du vaste lac de données est difficile, y compris la bonne utilisation du cryptage, l’enregistrement des histoires d’accès aux données et l’accès aux données par le biais de divers mécanismes d’authentification standard de l’industrie.
- Délai de rentabilité : Les entreprises sont désireuses de raccourcir le temps nécessaire pour exploiter la valeur des données. Gérer de nombreuses sources pour divers types de données et utiliser une solution de type Web of points pour y parvenir est souvent chronophage.
Présentation des composants Hadoop
Cette section décrit les principaux composants de l’écosystème Hadoop.
Apache Hadoop est une structure logicielle en open source pour le stockage et le traitement distribué qui permet aux organisations de stocker et interroger des données, qui sont d’ordres de grandeur plus larges que les données dans des bases de données traditionnelles, et de le faire dans un environnement en cluster et rentable. L’image ci-dessous illustre un diagramme architectural des composants Apache Hadoop.
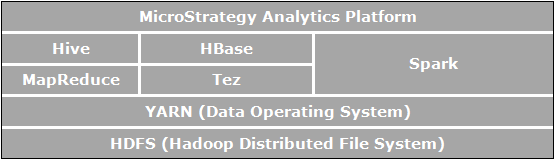
Les éléments qui sont directement liés aux analyses professionnelles et pertinentes aux cas d’utilisation possibles grâce à MicroStrategy sont :
- HDFS (Système de fichiers distribués Hadoop) est le système de fichiers de stockage des données utilisé par les applications Hadoop exécuté sur des clusters de machines fonctionnelles. Les clusters HDFS sont composés d’un NameNode qui gère les métadonnées du système de fichiers et de DataNodes qui stockent les données actuelles. HDFS permet le stockage de fichiers volumineux importés d’applications en dehors de l’écosystème Hadoop et aussi l’organisation de fichiers importés devant être traités par les applications Hadoop.
- YARN (Yet Another Resource Negotiator) fournit une gestion de ressources et est une plate-forme centrale pour offrir des outils de gouvernance de données, de sécurité et d’opérations sur l’ensemble des clusters Hadoop pour les applications exécutées sur Hadoop.
- MapReduce est un modèle de traitement de données distribuées et d’environnement d’exécution qui est exécuté sur de grands clusters de machines fonctionnelles. Il utilise l’algorithme MapReduce qui décompose toutes les opérations en fonctions de mappage et/ou de réduction.
- Tez est une structure de programmation de flux de données généralisée conçue pour fournir de meilleures performances pour les workflows de requête SQL, comme comparé à MapReduce.
- Hive est un entrepôt de données distribué créé par dessus HDFS pour gérer et organiser de grands volumes de données. Hive fournit un stockage de données schématisé pour héberger de grands volumes de données brutes et un environnement de type SQL pour exécuter les analyses et les tâches de requête sur des données brutes dans HDFS. L'environnement de type SQL de Hive est la façon la plus courante d'interroger Hadoop. De plus, Hive peut être utilisé pour canaliser les requêtes SQL vers une variété de moteurs de requêtes tels que Map-Reduce, Tez, Spark, etc.
- Spark est une structure de calcul de cluster. Elle fournit un modèle de programmation simple et expressif qui prend en charge une vaste gamme d’applications, y compris ETL, l’apprentissage machine, le traitement de flux et le calcul de graphique.
- HBase est une base de données orientée colonne et distribuée. Elle utilise HDFS pour son stockage sous-jacent et prend en charge les deux calculs de style par lot en utilisant MapReduce et les requêtes de point (lectures aléatoires) qui sont transactionnelles.
Connexion et analyse des sources du Big Data dans MicroStrategy
L’écosystème de données volumineuses a un nombre de moteurs SQL (Hive, Impala, Drill, etc.) qui permet aux utilisateurs de transmettre des requêtes SQL aux sources de données volumineuses et d’analyser les données de la même façon que pour les bases de données relationnelles traditionnelles. Les utilisateurs peuvent ainsi tirer profit de la même infrastructure analytique comme ils le feraient en accédant aux données structurées via SQL.
MicroStrategy prend en charge et certifie la connectivité avec plusieurs moteurs SQL de données volumineuses. Comme pour les bases de données traditionnelles, la connectivité à ces moteurs SQL se fait via les pilotes ODBC ou JDBC.
MicroStrategy offre également une méthode autorisant les utilisateurs à importer des données directement depuis le système de fichiers Hadoop (HDFS). Cela est obtenu en utilisant MicroStrategy Hadoop Gateway, qui permet aux clients de contourner les moteurs de requêtes SQL et de charger les données directement depuis le système de fichiers dans des cubes en mémoire MicroStrategy à des fins d’analyse.
Le diagramme ci-dessous affiche les couches par lesquelles les données voyagent pour atteindre MicroStrategy à partir des systèmes Hadoop.

Sélection d’un mode d’accès aux données
MicroStrategy permet aux utilisateurs de tirer efficacement parti des ressources du système de données volumineuses et du système BI en tandem pour offrir les meilleures performances d’exécution des analyses. Les utilisateurs disposent des options suivantes :
- Amener les données en mémoire (approche en mémoire) : les données pour l’analyse est obtenue exclusivement à partir du cube en mémoire. MicroStrategy permet aux utilisateurs d’extraire des sous-ensembles de données, allant jusqu’à plusieurs centaines de gigaoctets, d’une source de données volumineuses dans un cube en mémoire, et de créer des rapports/portfolios à partir du cube. En général, un cube est configuré pour être publié à intervalles réguliers et est enregistré dans la mémoire principale du serveur, éliminant le besoin chronophage d'interroger la base de données de données volumineuses.
- Accéder directement aux données à partir de leur source (approche de connexion en direct) : accès aux données exclusivement depuis la base de données. MicroStrategy offre une connectivité à diverses sources de données volumineuses pour exécuter des rapports et des portfolios dynamiquement en direct par rapport à la source.
- Adopter une approche hybride : les données sont obtenues à partir du cube en mémoire et de la base de données, comme nécessaire. L’approche hybride tire efficacement parti de la puissance des deux méthodes ci-dessus en autorisant l’utilisateur à passer en toute transparence de l’une à l’autre selon la requête soumise aux utilisateurs. MicroStrategy est doté d’une technologie d’approvisionnement dynamique qui détermine automatiquement si une réponse à une requête particulière peut être obtenue des cubes ou de la base de données et peut canaliser la requête en conséquence.
La figure suivante résume les trois approches :

Si l’approche en mémoire offre les performances d’analyse les plus rapides, elle peut ne pas être pratique à cause du grand volume de données. La section suivante aborde les considérations de conception pour décider de la façon d’accéder aux données.
- Approche en mémoire : Cette approche fournit des performances plus rapide. Cependant, les données sont limitées au petit jeu qui peut s’ajuster à la mémoire principale et selon la fréquence de mise à jour des données en mémoire, ces dernières peuvent être mauvaises. Utilisez cette approche quand :
- Les données finales sont sous une forme agrégée et peuvent s’ajuster dans la mémoire principale de la machine BI.
- La base de données est trop lente pour les analyses interactives
- L’utilisateur doit supprimer la charge d’une base de données transactionnelle
- L’utilisateur doit être hors ligne
- La sécurité des données peut être configurée au niveau du BI
- Approche de connexion en direct : Dans les situations où les données pour le portfolio doivent être actuelles, ou si les données sont à un niveau de détail où les données ne peuvent pas toutes être stockées dans le cube en mémoire, alors la création d’un portfolio utilisant l’option de connexion en direct peut être une approche appropriée. Cela permet aux données les plus récentes d’être extraites de l’entrepôt à chaque exécution. Cette approche est également utile dans les cas où la sécurité est configurée au niveau de la base de données et l’exécution de l’entrepôt est nécessaire pour chaque utilisateur afin d’afficher les données auxquelles ils souhaitent accéder. Utilisez cette approche quand :
- La base de données est rapide et réactive
- L’utilisateur accède à des données qui sont souvent mises à jour dans la base de données
- Les volumes de données sont supérieurs à la limite en mémoire
- Les utilisateurs veulent une livraison planifiée d’un portfolio pré-exécuté
- La sécurité des données peut être configurée au niveau de la bases de données
- Approche hybride : Cette approche est appropriée pour les cas d’utilisation où l’écran de démarrage du portfolio contient des informations agrégées de haut niveau à partir desquelles les utilisateurs peuvent développer les détails. Dans de tels cas, les administrateurs peuvent publier des données agrégées dans un cube en mémoire afin que l'écran principal du portfolio s'affiche rapidement, et pour que le portfolio aille à l'encontre des données de niveau inférieur dans le système de données volumineuses lorsque l'utilisateur développe les données. La capacité d’approvisionnement dynamique dans MicroStrategy permet de créer de telles applications très facilement car les rapports sélectionnés peuvent être transformés en cubes et MicroStrategy détermine automatiquement d’aller à l’encontre des cubes ou de la base de données en fonction des données que l’utilisateur demande.
Pilotes et fournisseurs de données volumineuses pris en charge
Les moteurs SQL Hadoop sont optimisés pour la manipulation spécifique des données. En fonction du type de données et des requêtes exécutées pour accéder aux données, nous pouvons diviser les cas d’utilisation dans les cinq groupes suivants :
- SQL par lot : utilisé pour effectuer des transformations à grande échelle sur les données volumineuses
- SQL interactif : permet des analyses interactives sur les données volumineuses
- Pas SQL : utilisé en général pour le stockage de données à grande échelle et les requêtes transactionnelles rapides
- Données non structurées/moteurs de recherche : analyse de données de texte et de journaux, utilisant principalement les fonctionnalités de recherche
- Nettoyage et chargement des données dans la mémoire/Hadoop Gateway : optimisé et utilisé principalement pour une publication rapide dans les cubes en mémoire
La figure suivante affiche le mappage entre les cas d’utilisation et les moteurs actuellement pris en charge dans MicroStrategy.
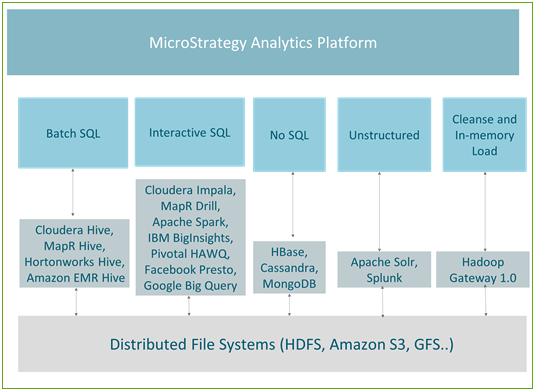
Traitement par lot
Hive est le mécanisme d’interrogation le plus populaire pour le traitement par lot. Tolérant aux défaillances, il est recommandé pour les tâches de type ETL. Toutes les distributions Hadoop principales (comme Hortonworks, Cloudera, MapR et Amazon EMR) offrent des connecteurs ODBC Hive. MicroStrategy s’associe à tous les fournisseurs Hadoop et offre une connectivité certifiée à Hadoop via Hive.
Hive est un bon moteur à utiliser avec l’approche en mémoire dans MicroStrategy ou comme faisant parti de l’approche de connexion directe quand elle est associée aux services de distribution afin que la latence de la base de données n’affecte pas l’utilisateur final. Dans la mesure où il utilise MapReduce pour traiter ses requêtes, le traitement par lot a une latence élevée et n’est pas approprié pour les requêtes interactives.
La table suivante répertorie les informations de connectivité pour les distributions Hive prises en charge.
| Fournisseur | Connectivité | Cas d’utilisation | Nom du pilote | Workflow |
|---|---|---|---|---|
| Cloudera Hive | ODBC | Un outil qui prend SQL et le convertit en Map Reduce et qui peut être utilisé pour effectuer une transformation de type ETL à grande échelle sur les données | MicroStrategy Hive ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Hortonworks Hive |
ODBC |
Un outil qui prend SQL et le convertit en Map Reduce et qui peut être utilisé pour effectuer une transformation de type ETL à grande échelle sur les données | MicroStrategy Hive ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| MapR Hive | ODBC | Un outil qui prend SQL et le convertit en Map Reduce et qui peut être utilisé pour effectuer une transformation de type ETL à grande échelle sur les données | MicroStrategy Hive ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Amazon EMR Hive | ODBC | Un outil qui prend SQL et le convertit en Map Reduce et qui peut être utilisé pour effectuer une transformation de type ETL à grande échelle sur les données | MicroStrategy Hive ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
Requêtes interactives
Plusieurs fournisseurs Hadoop ont développé des moteurs aux performances rapides pour permettre les requêtes interactives. Ces moteurs utilisent des mécanismes spécifiques à un fournisseur/une technologie pour interroger HDFS, mais utilisent toujours Hive comme metastore. Toutes ces technologies évoluent à un rythme rapide pour offrir des temps de réponse plus rapides sur de grands jeux de données conjointement avec des capacités d’analyse avancées. Les moteurs interactifs tels que Impala, Drill ou Spark peuvent être associés efficacement à MicroStrategy Portfolio pour permettre la découverte de données en libre-service sur Hadoop. Les moteurs sont certifiés pour fonctionner avec MicroStrategy.
La table suivante répertorie les informations de connectivité pour les distributions prises en charge.
| Fournisseur | Connectivité | Cas d’utilisation | Nom du pilote | Workflow |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Un moteur de requête MPP (massively parallel processing) en open source pour les données stockées dans un cluster d’ordinateurs exécutant Apache Hadoop. Impala utilise son propre moteur de traitement et peut effectuer des opérations en mémoire. | MicroStrategy Impala ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Apache Drill | ODBC | Un moteur de requête de faible latente en open source qui est pris en charge par MapR. Il a la capacité de découvrir des schémas instantanément pour pouvoir fournir des capacités d’exploration de données en libre-service. | MicroStrategy Drill ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Apache Spark | ODBC | Un outil de traitement de données qui fonctionne sur des collections de données distribuées et qui est développé par l’une des plus grandes communautés open source. Avec son traitement en mémoire, Spark est d’un ordre de grandeur plus rapide que MapReduce | MicroStrategy ODBC Driver for Apache Spark SQL | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| IBM BigInsights | ODBC | Un ensemble riche de capacités d’analyse avancées qui permet aux entreprises d’analyser des volumes massifs de données structurées et non structurées dans leur format natif sur Hadoop | BigInsights ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Pivotal HAWQ | ODBC | Un moteur de requête SQL parallèle qui lit et écrit des données dans HDFS de manière native. Il fournit aux utilisateurs une interface SQL compatible standard ANSI complète | MicroStrategy ODBC Driver for Greenplum Wire Protocol | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
| Google BigQuery | ODBC | Un service basé sur le Cloud pour exploiter l'infrastructure de Google et permettre aux utilisateurs d'interroger des pétaoctets de données de manière interactive | MicroStrategy Google BigQuery ODBC Driver | Pris en charge via MicroStrategy Architect et l’importation de données MicroStrategy |
Sources non SQL
Les sources non SQL sont optimisées pour le stockage d’informations volumineuses et les requêtes transactionnelles. Elles peuvent être associées efficacement à une option de source multiple ou à une option de mélange de données dans MicroStrategy afin que les utilisateurs puissent voir des informations de niveau supérieur des bases de données traditionnelles et utiliser la source non SQL pour fournir la possibilité de développer les données de transaction du niveau le plus bas via l’intégration avec des sources non SQL.
La table suivante répertorie les sources non SQL pour lesquelles MicroStrategy offre une connectivité certifiée.
| Fournisseur | Connectivité | Cas d’utilisation | Nom du pilote | Workflow |
|---|---|---|---|---|
| Apache Cassandra | JDBC | Un stockage de valeur clé, toutes les données sont composées d’une clé indexée et d’une valeur | Cassandra JDBC Driver | Pris en charge via l’importation de données MicroStrategy |
| HBase | JDBC | Une base de données non SQL de stockage de colonne qui, au lieu de stocker des données dans des lignes, stocke des données dans des tables comme sections de colonnes de données. Elle offre des performances élevées et une architecture évolutive | Phoenix JDBC Driver | Pris en charge via l’importation de données MicroStrategy |
| MongoDB | ODBC | Une base de données orientée document qui évite la structure traditionnelle de base de données relationnelles basées sur les tables, pour une intégration plus facile et plus rapide de données dans certains types d’applications | MicroStrategy MongoDB ODBC Driver | Pris en charge via l’importation de données MicroStrategy |
Données non structurées/Moteurs de recherche
Les moteurs de recherche sont des outils efficaces qui permettent aux utilisateurs d’effectuer des recherches dans de larges volumes de données textuelles et d’ajouter du contexte aux données dans leurs portfolios. Cette fonctionnalité est puissante lorsque exploitée avec le mélange de données dans MicroStrategy, permettant à la recherche de données d’être associée aux sources d’entreprise traditionnelles.
La table suivante répertorie les informations de connectivité pour les distributions Hive prises en charge.
| Fournisseur | Connectivité | Cas d’utilisation | Nom du pilote | Workflow |
|---|---|---|---|---|
| Apache Solr | Natif | Le moteur de recherche open source le plus populaire qui permet la recherche de texte complet, les recherches à facette et l’indexation en temps réel. MicroStrategy a créé un connecteur pour l’intégration avec Solr. Il offre la possibilité d’effectuer des recherches dynamiques, d’analyser et de visualiser les données indexées de Solr | intégré | Pris en charge via l’importation de données MicroStrategy |
| Splunk Enterprise | ODBC | Un moteur de recherche propriétaire très utilisé | Splunk ODBC Driver | Pris en charge via l’importation de données MicroStrategy |
MicroStrategy Hadoop Gateway
MicroStrategy offre une connectivité native à HDFS pour utiliser Hadoop gateway. Hadoop Gateway contourne Hive, accédant aux données directement depuis HDFS. Hadoop Gateway est une installation distincte sur des nœuds HDFS.
Hadoop Gateway a été conçue pour optimiser un cas d’utilisation de création de grands cubes en mémoire lors de la connexion à Hadoop. Elle utilise les techniques suivantes pour atteindre l’importation efficace de données par lot de Hadoop :
- Contourne Hive pour accéder directement aux données : Communique nativement avec HDFS exécuté comme une application Yarn contournant Hive/ODBC. Cela réduit davantage la requête de données et le temps d’accès.
- Chargement parallèle de données depuis HDFS : Charge des données dans MicroStrategy Intelligence Server via des threads parallèles, générant un plus grand débit et réduisant le temps de chargement.
- Permet le nettoyage de données Push Down pour des cas d’utilisation en mémoire : Les opérations d’organisation des données sont exécutées dans Hadoop, permettant un arrangement à grande échelle.
Présentation architecturelle de Hadoop Gateway
- Hadoop Gateway est une installation propriétaire MicroStrategy distincte, devant être installée sur les données HDFS et NameNodes en installant :
- Moteur de requête Hadoop Gateway sur HDFS NameNode
- Moteur d’exécution Hadoop Gateway sur le moteur d’exécution HDFS
- MicroStrategy Intelligence Server envoie la requête au moteur d’exécution Hadoop Gateway. La requête est ensuite analysée et envoyée aux nœuds de données pour traitement. Les données extraites pour la requête sont ensuite poussées des nœuds de données vers MicroStrategy Intelligence Server dans des threads parallèles pour être publiées dans des cubes en mémoire.
La figure suivante illustre MicroStrategy Hadoop Gateway dans un diagramme d’architecture.

Limitations d’Hadoop Gateway
Actuellement, Hadoop Gateway a quelques limitations :
- Seuls les fichiers texte et csv sont pris en charge
- L’arrangement des données est uniquement pris en charge pour les cas d’utilisation en mémoire
- L’importation de données de plusieurs tables n’est pas prise en charge
- Pour les capacités d’analyse, seuls l’agrégation et le filtrage sont pris en charge. L’opération JOIN n’est pas prise en charge
- La sécurité Kerberos est prise en charge avec un utilisateur de service partagé par rapport à une délégation pour des utilisateurs spécifiques
Exemple de workflows pour connexion à des sources du Big Data
Cette section contient des exemples de divers workflows pour une connexion à des sources de données volumineuses depuis MicroStrategy :
- Pour se connecter à Hortonworks Hive via Web Data Import
- Pour se connecter à Hortonworks Hive via Web Data Import
- Pour se connecter via Hadoop Gateway
Connexion via Developer à Hortonworks Hive
Les administrateurs/développeurs Business Intelligence peuvent utiliser MicroStrategy Developer pour connecter une source de données volumineuses en utilisant les étapes mentionnées ci-dessous. Le workflow est semblable à la façon dont les bases de données traditionnelles sont intégrées à MicroStrategy. Les étapes peuvent être divisées en trois zones conceptuelles :
- Création d’une connexion à la source depuis MicroStrategy. Cela inclut la création d’une source de données ODBC avec des détails de connectivité appropriés et la création d’un objet d’instance de base de données pointant vers la source ODBC.
- Importation des tables depuis la source via l’interface de catalogue de l’entrepôt.
- La création d’objets de schéma requis (tels que les attributs, les faits, etc.) pour créer des rapports et des portfolios.
Dans les étapes ci-dessous, Hortonworks Hive est indiqué comme exemple.
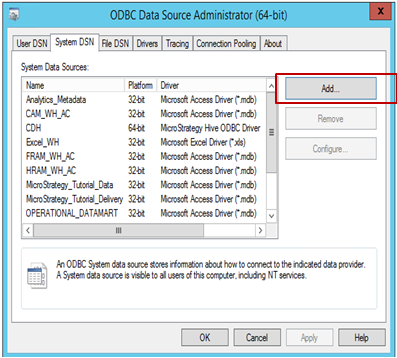
Pour créer une connexion à la source depuis MicroStrategy :
-
Ouvrez la boîte de dialogue Administrateur de source de données ODBC pour créer une connexion de source de données à la source. Cliquez sur Ajouter pour créer une nouvelle connexion.
-
Sélectionnez le pilote (dans cet exemple, Hive ODBC est sélectionné), puis cliquez sur Terminer

-
Remplissez les détails de connectivité appropriés :

- Nom de la source de données : Nom avec lequel la connexion est enregistrée
- Description : Facultatif
- Type de serveur Hive : Sélectionnez le serveur en fonction de l’environnement
-
Mode de découverte de service : Deux modes de découverte de service peuvent être utilisés, comme illustré ci-dessous. Lorsque l'utilisateur sélectionne ‘Gardien de zoo', MicroStrategy permet de taper Gardien de zoo dans l'espace de nom, comme illustré ci-dessous.

- Hôte, Port et Nom de base de données : Champs requis, renseignés en fonction de l’environnement.
- Authentification : MicroStrategy certifie différents mécanismes d’authentification pour Hortonworks Hive : Aucune authentification, Kerberos, Nom d’utilisateur, Nom d’utilisateur et mot de passe. En fonction de la sélection de mécanisme, le paramètre de transport Thrift changera. Tel que :
- Pour aucune authentification : le paramètre de transport Thrift est ‘Binaire'
- Pour Kerberos : le paramètre de transport Thrift est ‘SASL'
Nom d'utilisateur, Nom d'utilisateur et mot de passe : le paramètre de transport Thrift est ‘SASL'

- Une fois que les détails de connexion sont sélectionnés et renseignés, il est possible de la tester en utilisant le bouton 'Test'.
-
Ouvrez MicroStrategy Developer. Connectez-vous au projet -> Accédez à Configuration Manager -> Instances de base de données -> Créer une instance de base de données.
Si vous exécutez MicroStrategy Developer sur Windows pour la première fois, exécutez-le en tant qu'administrateur.
Cliquez avec le bouton droit sur l'icône du programme et sélectionnez Exécuter en tant qu'administrateur.
Cela est nécessaire pour définir correctement les clés de registre Windows. Pour plus d’informations, voir KB43491.

Sélectionnez le ‘nom de la source de données' créé précédemment pour la source. Renseignez la connexion utilisateur et le mot de passe.
-
Importez des tables de la source : Accédez à Schéma -> Catalogue de l’entrepôt -> Sélectionnez l’instance de la base de données -> Faites glisser et déplacez les tables nécessaires depuis la source

Enregistrez et fermez le catalogue.
-
Créez des attributs et des mesures comme requis. Lancez un nouveau rapport MicroStrategy pour créer votre analyse.
Pour se connecter à Hortonworks Hive via Web Data Import
Les analystes commerciaux et les utilisateurs finaux peuvent tirer parti du workflow MicroStrategy Web Data Import pour se connecter aux données et les analyser comme ils le feraient avec des sources de données relationnelles. Ce processus peut être divisé en trois zones conceptuelles : Connexion, importation et analyse.
Ci-dessous se trouve la fenêtre de connectivité de MicroStrategy Web Data Import, se connectant à Hortonworks Hive.
-
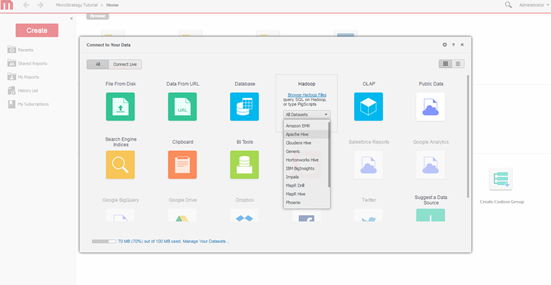
Sélectionnez le moteur de requête. Sélectionnez le moteur pour se connecter via l’écran d’importation des données MicroStrategy.
-
Sélectionnez des options d’importation. Choisissez de créer une requête, taper une requête ou de choisir des tables. L'approche du choix de tables est recommandée car elle offre la meilleure utilisation des capacités de modélisation de MicroStrategy.

-
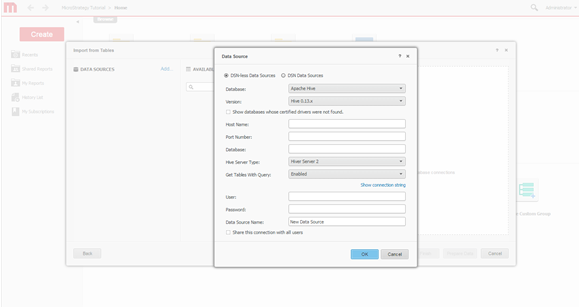
Créez une connexion. Définissez une nouvelle connexion au système Hadoop.
-
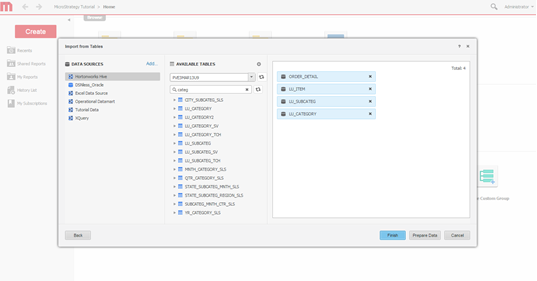
Sélectionnez des tables. Sélectionnez des tables desquelles accéder aux données.
-
Modélisez les données. Alternativement, modélisez les tables, changez le nom des attributs et des mesures, excluez les colonnes de l’importation, etc.
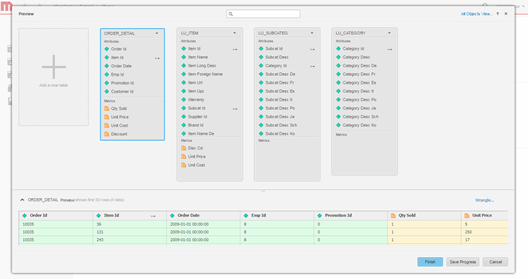
-
Définissez un mode d’accès aux données. Choisissez ou non de publier des données en tant que cube en mémoire ou via le mode de connexion directe.
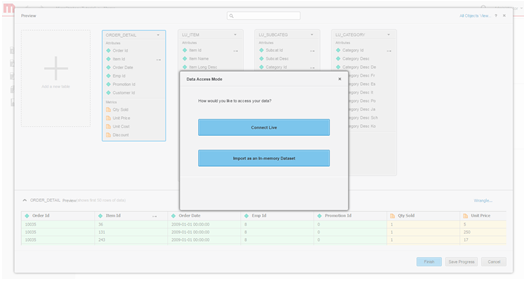
- Créez le portfolio.
Pour se connecter via Hadoop Gateway
Hadoop Gateway peut être exploité depuis MicroStrategy Web Data Import, suivant le workflow classique d’importation de données :
- Créer une connexion au cluster Hadoop/HDFS
- Parcourir et importer les dossiers de HDFS
- Nettoyer les données (facultatif)
- Publier les données comme cube en mémoire dans MicroStrategy Intelligence Server et analyser les données via un portfolio
Ci-dessous se trouve les détails pour chacune des étapes.
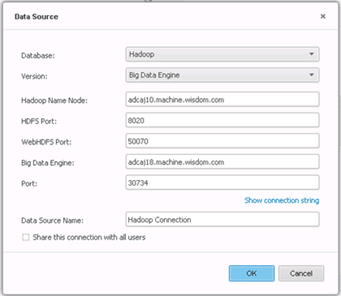
-
Créez une connexion.
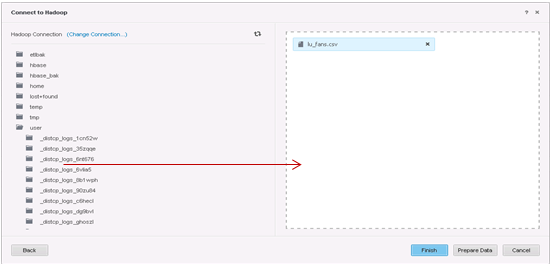
-
Sélectionnez les tables à importer.
-
Préparer les données avec l'arrangement de données.
- Les étapes suivantes sont ensuite publiées dans les cubes en mémoire dans MicroStrategy Intelligence Server et utilisent l’interface d’Aperçu visuel pour créer un portfolio.