Strategy ONE
Merging Intelligent Cubes
MicroStrategy Web allows you to merge two or more Intelligent Cubes. This enables the development of datasets via data importing, instead of creating and modifying each new dataset from scratch. This option allows users to collaborate and develop an application schema over time by merging smaller, independent datasets into one Intelligent Cube. The attribute IDs for attributes in the cubes will remain intact so that any dashboards or reports that were previously linked to the cubes will still execute correctly. The following diagram shows how two cubes are merged.
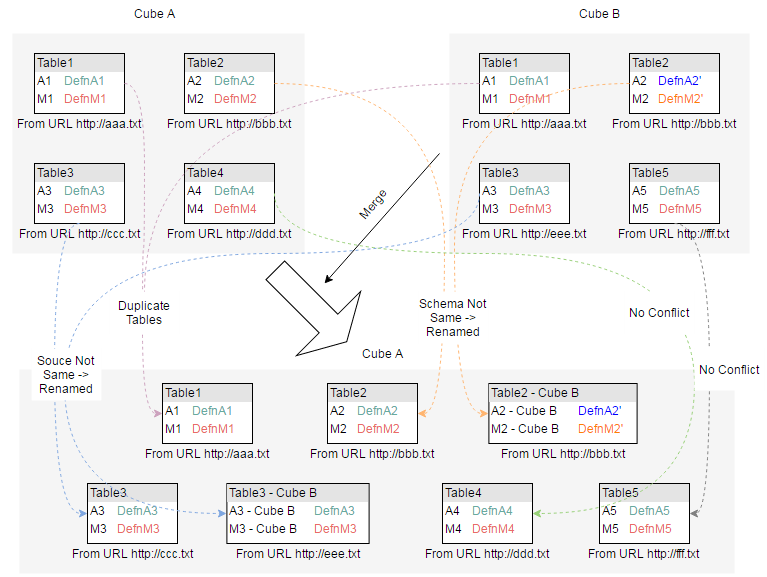
For descriptions of scenarios involving duplicate data between cubes, see Handling duplicate data when merging Intelligent Cubes.
Prerequisites
- User must have full control access rights to the cubes being merged.
- None of the cubes being merged are exclusive.
- Cubes must support the same access type. (For example, In-Memory only cubes cannot merge with Direct Data Access only cubes.)
Merging cubes in MicroStrategy Web
For simplicity, the following steps refer to Cube A and Cube B, where Cube B will be merged into Cube A.
-
From the MicroStrategy Web Home page navigate to the Intelligent Cube (Cube A) you want to merge data into.
Cube A must be selected here to maintain its attribute IDs after the merge. If you select Cube B, any dashboards or reports linked to Cube A before the merge may not function correctly.
-
Right-click on the cube and choose Edit.
-
In the Preview window select Add a new table.
-
From the Connect to Your Data window, choose MicroStrategy Datasets.

-
Navigate to the Intelligent Cube (Cube B) you want to add. Select the Cube and click OK.
- To add another cube, repeat Steps 4 and 5.
- To save the updated Cube A, click Save Progress.
-
If you are finished adding to Cube A, click Update Dataset.
-
In the Data Access Mode window choose how you access the new cube by selecting Connect Live or Import as an In-memory Dataset.
-
The Start your analysis window opens. You can choose from Create Dashboard, Create Document, or Create Report.
Handling duplicate data when merging Intelligent Cubes
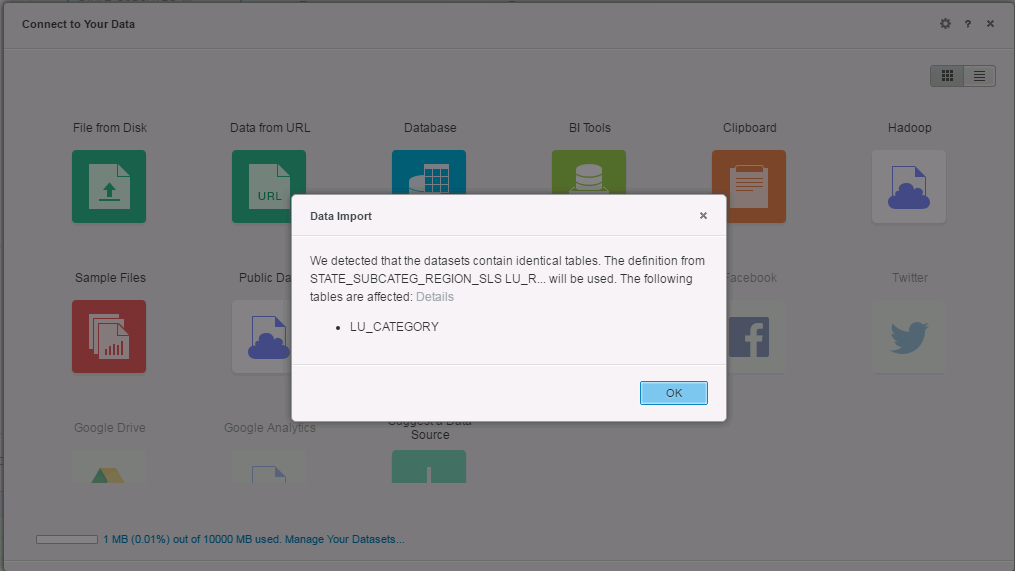
In some cases two Intelligent Cubes being merged will contain tables, attributes, or metrics that are complete or partial duplicates. MicroStrategy will detect and resolve these anomalies during the merge to preserve the original attribute IDs in the newly merged cube. A warning message like the one pictured below will notify you of the duplicate data and how it will be resolved.
Schema comparisons for duplicate tables
- If the schema for the duplicate tables from Cube A and Cube B is the same, the table from Cube A will be picked and the duplicate from Cube B will be skipped. The attribute IDs from Cube A will be retained.
- If the schema is different on both of the duplicate tables, Cube A will map as many attributes from the duplicate table as possible. These attributes will retain the IDs from Cube A and the remaining attributes will retain their IDs from Cube B.
- Columns are paired using column names
- Derived columns are skipped.
- Matched pairs of columns are compared using their mapping information, including object type, object name, data type, geo roles, etc.
- The schema will be treated as different if missing or redundant columns are found.
Source comparisons for duplicate tables
- If the data source table structure and schema for two identical tables is the same, they will be considered duplicates, and the table from Cube B will be skipped.
- If the data source for two identical tables is different, both tables will be merged. The name of the table from Cube B will be changed to "table name - Cube B".
Attribute and metric comparisons
- Attributes can be manually linked between two cubes before the merge.
-
For attributes and metrics, if the name is the same and the data type are compatible, they will be linked automatically.
-
If attributes or metrics have the same name, but are not data type compatible, the attribute or metric being merged will be renamed "attribute/metric name - Cube B".
Multiform attributes follow the same rules as above. When multiform and single form attributes are compared, the data types for the ID of the multiform attribute and the name of the single form attribute are checked for compatibility.
-
GeoRole related attributes
- If Cube A and Cube B have duplicate attributes, where one is missing the GeoRole, they will be linked and the GeoRole added to the attribute without one.
- If Cube A and Cube B have duplicate attributes with different GeoRole values, the attribute from Cube B will be renamed.
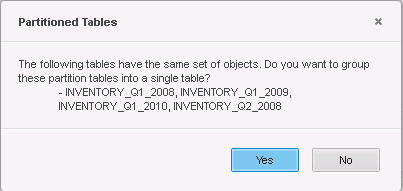
Partitioned Tables
-
If Cube A and Cube B both have two partition tables, they will merge successfully. To group the tables into a single table, select Yes in the reminder window. You can also group them together manually on the table menu.
- If all the sub tables are the same, the newly added duplicate database table will be removed.
-
If the tables in Cube B are not a subset of the group tables in Cube A, but they can be grouped, you will see the pop up window for the partition option. Click Yes to remove duplicate tables. Click No to keep the tables separate. The tables can be grouped manually on the table menu.