MicroStrategy ONE
Python 데이터 소스 스크립트 작성
MicroStrategy ONE 에서 시작 업데이트 11, Python 데이터 소스를 사용하려면 데이터 소스에 대한 연결로 사용할 Python 스크립트를 작성해야 합니다.
데이터 소스 스크립트 함수
데이터 소스 스크립트에서 다음 세 함수를 사용해야 합니다.
-
browse()복사def browse():
"""
Description: retrieve the catalog information.
Input: no input is needed for this function.
Return: the result is returned as a dict object.The keys of the dict should be
table names of the python data source, and the values are normalized in Pandas
DataFrame format. Each DataFrame value will contain a table's column infos.
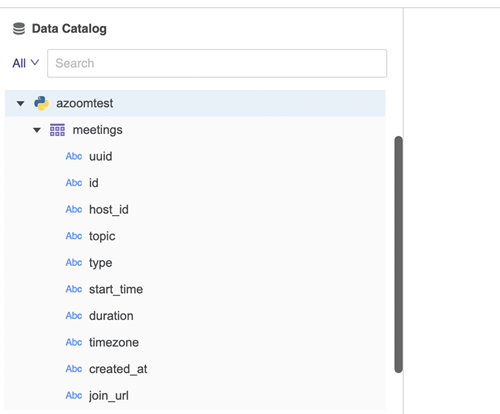
"""이 찾아보기 기능은 사용자가 Python 커넥터를 통해 데이터 소스에 연결하려고 할 때 트리거됩니다. 데이터 소스가 연결되면 데이터 소스의 모든 카탈로그 정보를 반환합니다. 테이블 이름 및 열이 데이터 소스 아래에 표시됩니다.
-
preview()복사def preview(table_name, row_limit):
"""
Description: get partial data for preview, data refine and schema change
Input: there are 2 parameters for preview.
- table_name: a table name should be selected if someone want to preview
the table.
- row_limit: the row limitation is used to define the scale when only
partial data is retrieved during the preview.
Return: the result is returned as a Pandas DataFrame format object. Only the
"row_limit" rows would be returned in the DataFrame object.
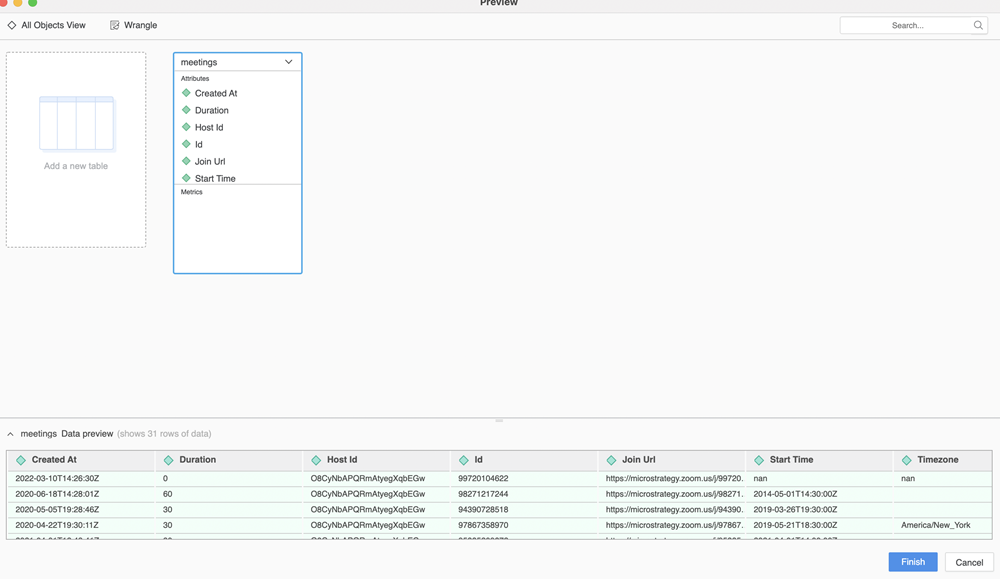
"""미리 보기 기능은 사용자가 을(를) 두 번 클릭하여 테이블을 추가하거나 을(를) 클릭하여 테이블을 미리 볼 때 트리거됩니다.
-
publish()복사def publish(table_name):
"""
Description: get the data published and stored the data into the cube
Input: the table_name parameter is needed to define witch table should
be published.
Return: the result is returned as a Pandas DataFrame format object. All
data needs to be returned for publishing.
"""게시 함수는 사용자가 저장을 클릭하여 큐브를 게시할 때 트리거됩니다. 테이블의 모든 데이터는 사용자가 소비할 수 있도록 검색됩니다.
판다 데이터 프레임에 대한 자세한 내용은 다음을 참조하십시오. 판다까지 10분 .
데이터 소스 스크립트 예
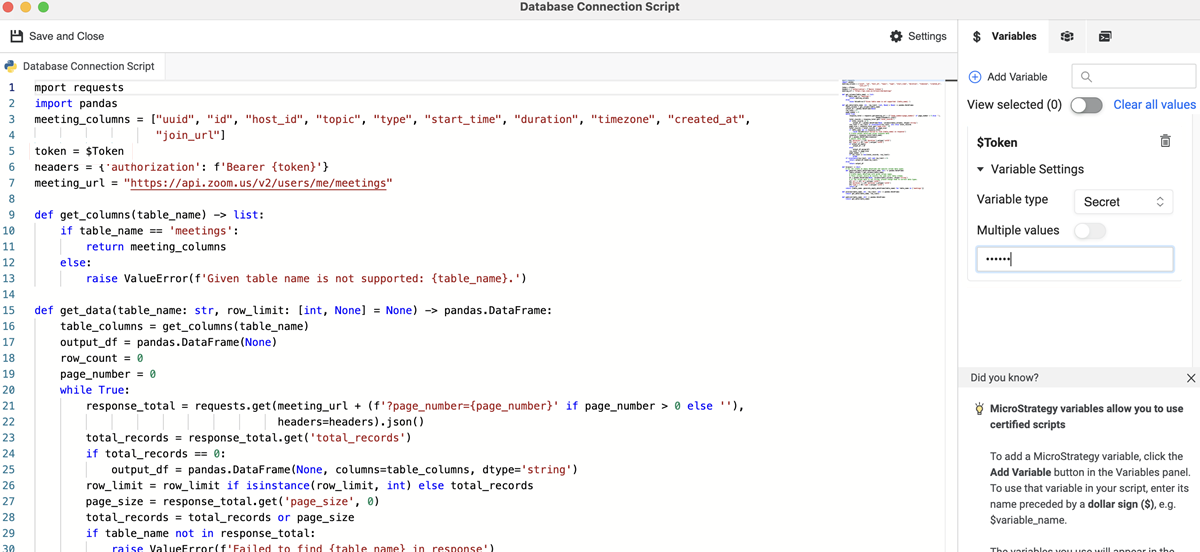
다음 확대/축소 커넥터 예를 참조하십시오. 사용자는 Python 데이터 소스의 API로 확대/축소 리소스에 연결하여 원하는 데이터를 검색할 수 있습니다. 예에서는 인증을 위한 데이터 소스 스크립트에 토큰이라는 변수를 포함합니다.
import requests
import pandas
meeting_columns = ["uuid", "id", "host_id", "topic", "type", "start_time", "duration", "timezone", "created_at",
"join_url"]
token = $Token
headers = {'authorization': f'Bearer {token}'}
meeting_url = "https://api.zoom.us/v2/users/me/meetings"
def get_columns(table_name) -> list:
if table_name == 'meetings':
return meeting_columns
else:
raise ValueError(f'Given table name is not supported: {table_name}.')
def get_data(table_name: str, row_limit: [int, None] = None) -> pandas.DataFrame:
table_columns = get_columns(table_name)
output_df = pandas.DataFrame(None)
row_count = 0
page_number = 0
while True:
response_total = requests.get(meeting_url + (f'?page_number={page_number}' if page_number > 0 else ''),
headers=headers).json()
total_records = response_total.get('total_records')
if total_records == 0:
output_df = pandas.DataFrame(None, columns=table_columns, dtype='string')
row_limit = row_limit if isinstance(row_limit, int) else total_records
page_size = response_total.get('page_size', 0)
total_records = total_records or page_size
if table_name not in response_total:
raise ValueError(f'Failed to find {table_name} in response')
# Create pandas dataframe using response data
response = response_total[table_name]
df = pandas.DataFrame(response)
# Adjust data types
df['duration'] = df['duration'].astype('int32')
df['type'] = df['type'].astype('int32')
if output_df.empty:
output_df = df
else:
output_df.merge(df)
row_count += page_size
page_number += 1
if row_count >= min(total_records, row_limit):
break
if isinstance(row_limit, int) and row_limit > 0:
return output_df.head(row_limit)
else:
return output_df
def browse() -> dict:
# You can create an empty dataframe and specify column data types.
def generate_empty_dataframe(table_name: str) -> pandas.DataFrame:
table_columns = get_columns(table_name)
# Create empty dataframe with given column names.
# These columns should be exactly the same with table schema.
df = pandas.DataFrame(None, columns=table_columns, dtype='string')
# If the column data is not string, please change them to correct data types.
df['id'] = df['id'].astype('int64')
df['duration'] = df['duration'].astype('int32')
df['type'] = df['type'].astype('int32')
return df
return {table_name: generate_empty_dataframe(table_name) for table_name in ['meetings']}
def preview(table_name: str, row_limit: int) -> pandas.DataFrame:
return get_data(table_name, row_limit)
def publish(table_name: str) -> pandas.DataFrame:
return get_data(table_name)