Version 2021
Partitioning
No PostgreSQL specific customizations were made for this feature.
When dealing with large volumes of data, data is often partitioned to improve performance. Partitioning is the division of a larger table into smaller tables. It can be implemented in a data warehouse to improve query performance by reducing the number of records that queries must scan to retrieve a result set. It can decrease the amount of time necessary to load data into data warehouse tables and perform batch processing.
For instance, instead of storing detailed sales order records for all months in a single table, database administrators often break this table down into a set of tables partitioned by month so that any one table contains only orders for a single month. Most databases allow for partitions to be created and the optimizer automatically routes the query to the correct table.
There are two basic types of partitioning:
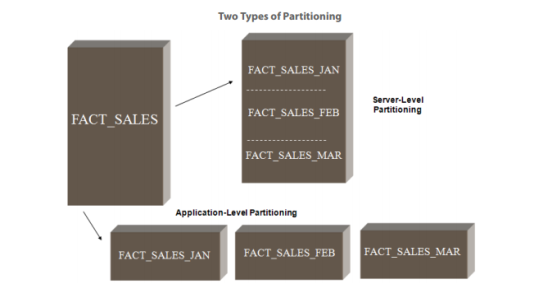
- Server-level partitioning involves dividing one physical table into logical partitions in the database environment. The database software handles this type of partitioning completely, so these partitions are effectively transparent to MicroStrategy software. Since only one physical table exists, the SQL engine only needs to write SQL against a single table, and the database manages which logical partitions are used to resolve the query. See Partition Tables for details about server-level partitioning.
-
Application-level partitioning involves dividing one large table into several separate, smaller physical tables called partition base tables. You can split the table into smaller tables in the database itself, and then, the application that is running queries against the database (in this case, MicroStrategy) manages which partitions are used for any given query. Since multiple physical tables exist, the SQL engine has to write SQL against different tables, depending on which tables are needed to retrieve the result set for a query.
MicroStrategy supports application-level partitioning for fact tables through one of two methods:
-
Warehouse Partition Mapping: This method is based on a physical warehouse partition mapping table (PMT) that resides in the data warehouse and describes the partition mapping relationship.
With warehouse partition mapping tables, you do not need to include the original fact table, rather only need to create and maintain a partition mapping table, which is used by MicroStrategy Architect to identify the partitioned base tables. See KB5529: How to set up a project using partition mapping tables in MicroStrategy Architect for more information.
-
Metadata Partition Mapping: This method is based on rules logically defined in MicroStrategy Architect and stored in the metadata.
In metadata partition mapping, the application running against the database still manages the physically partitioned fact tables, but the execution is different. Metadata partition mapping does not require a partition mapping table in the data warehouse. Instead, you define the data contained in each partition base table in a partition mapping object in MicroStrategy Architect. This object is stored in the metadata. You must partition mapping as new partition base tables are created.
-