Strategy ONE
Platform Analytics Architecture Examples
The following examples are not intended to be a comprehensive list of all supported architectures. Instead, they illustrate the best practices and general recommendations noted in Architecture Best Practices and Details.
Single Node for all Platform Analytics Components
In this configuration, all Platform Analytics components are installed on the same machine. All Library and Intelligence server environments (single nodes or clusters) must be configured to produce data on the same telemetry-server node. The Platform Analytics warehouse is represented by an out-of-the-box MicroStrategy Repository.
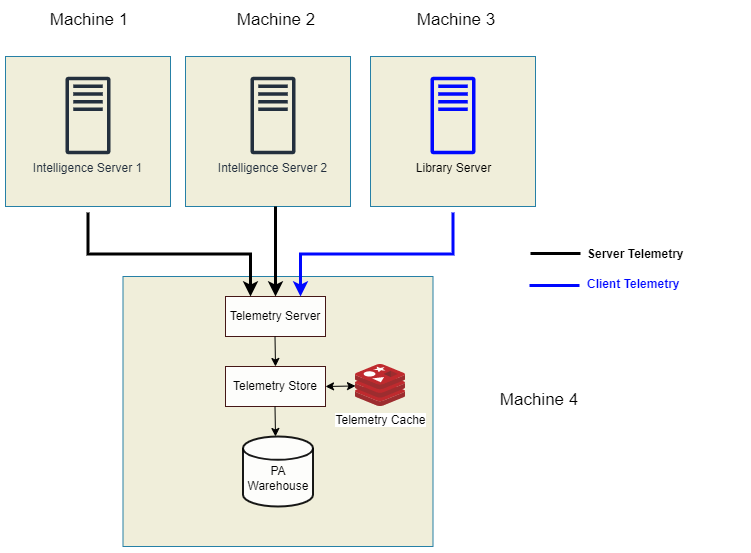
This is one of the simplest representation of Platform Analytics, where all components are installed on a single machine (Machine 4 in the above example).
Remote Platform Analytics Warehouse
In this architecture, all Platform Analytics components are on the same machine except for the Platform Analytics warehouse. You can opt for an out-of-the-box MicroStrategy Repository, or provision proprietary instance of PostgreSQL.
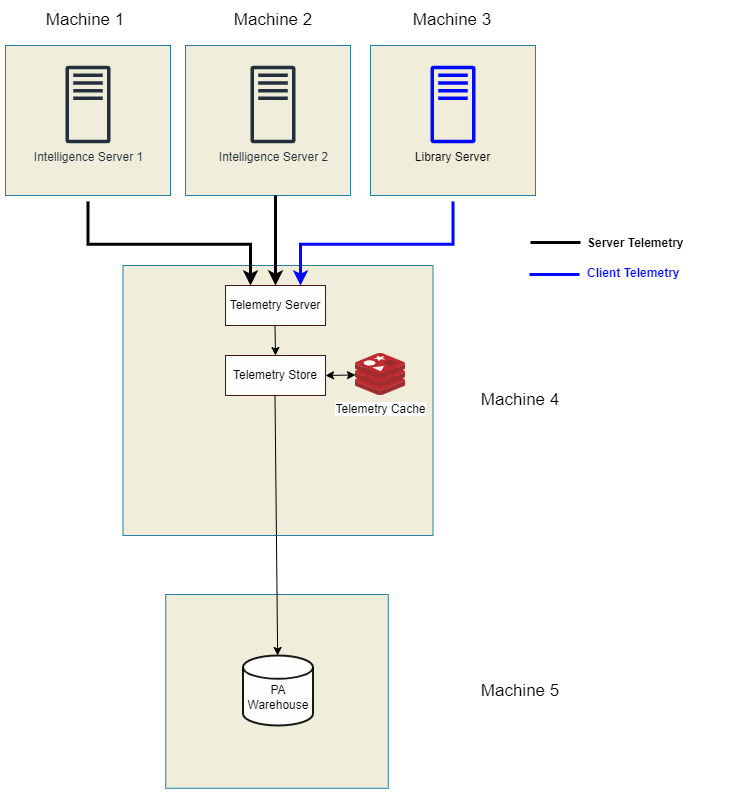
How to evaluate if this architecture is right for you:
-
If using Amazon RDS (Relational Database Service), it's easy to setup replicas for read access if there are use cases for heavy read queries against Platform Analytics data.
-
RDS provides an easy option to increase system resources in the future as your database grows over time.
-
If you are using RDS or self managed PostgreSQL, it's easier to manage system resources and perform capacity planning.
High Throughput/Advanced Architecture
High throughput architecture must be carefully considered, as its advantages come with significant configuration and maintenance requirements.
Generally, this approach is considered when:
-
You have numerous Intelligence server nodes with substantial telemetry (high object, user, jobs count).
-
High availability properties of the architecture are required.
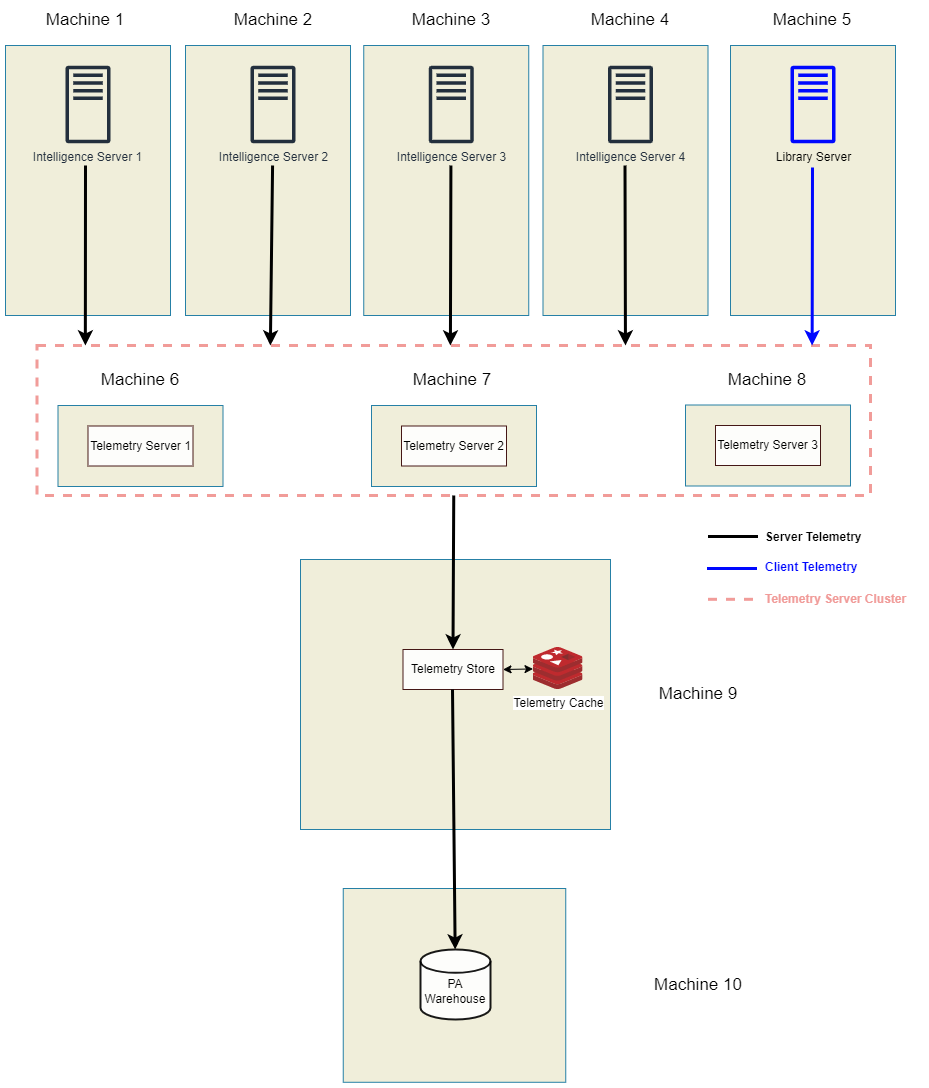
For high throughput architecture, we recommend using a cluster of Telemetry server nodes. One telemetry store can consume data from a single Telemetry server node or a Telemetry server cluster. This implies that all the Telemetry server nodes should be in a single cluster.
Currently, Telemetry server is represented by Zookeeper and Kafka components. You can install Telemetry server on a subset of nodes. The only requirement is to maintain an odd number of Telemetry server nodes (3, 5, and so on). See the Zookeeper documentation for more information. Multiple Telemetry server clusters are not supported.
Telemetry Server Nodes on the Same Machines as Intelligence Server Nodes
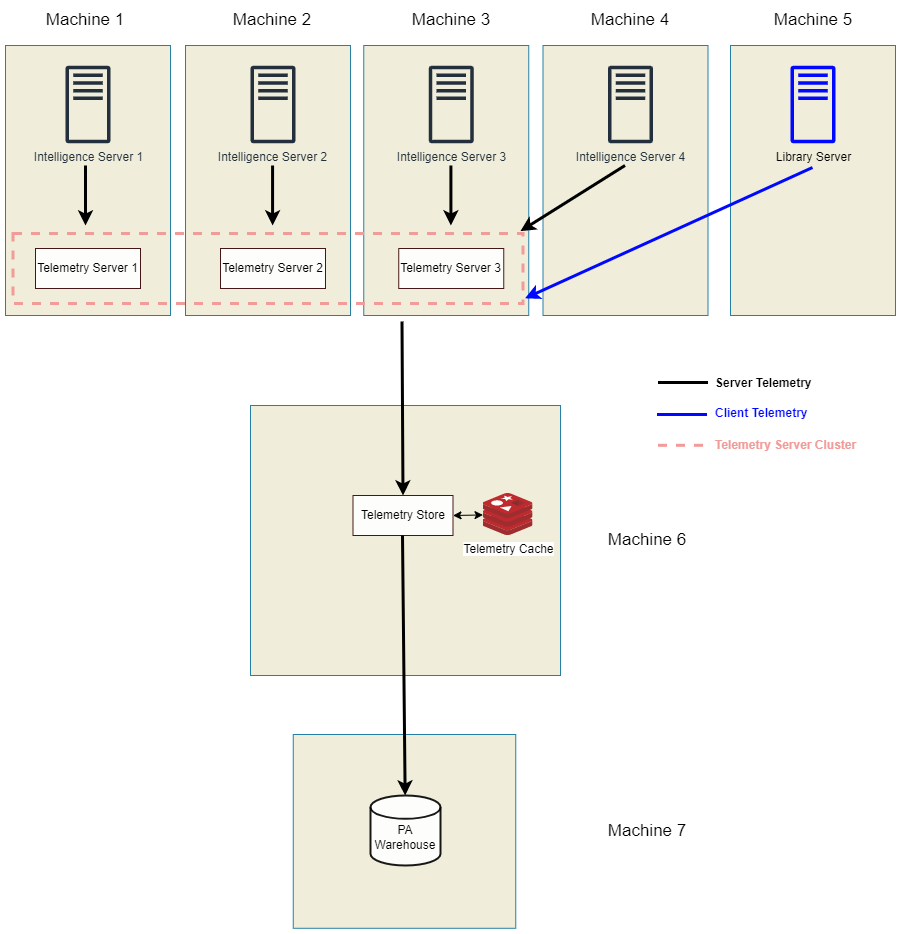
Telemetry Server Nodes Not on the Same Machines as Intelligence Server Nodes