Strategy One
Starting in MicroStrategy 2021 Update 4, Hadoop Gateway is no longer supported.
Analyzing Big Data in Strategy
Within the Business Intelligence and Analytics industry, Big Data primarily involves the consumption of large volumes of data that cannot be handled by traditional systems. Big Data requires new technologies to store, process, search, analyze, and visualize the large data sets.
For more information, see the following topics:
New Users: Overview – provides a general introduction to Big Data
Experienced Users:
- Connecting and Analyzing Big Data Sources in Strategy – discusses how to use Strategy to connect to Big Data sources
- Example Workflows to Connect to Big Data Sources – shows connection configuration examples
Overview of Big Data
This section serves as a general introduction to Big Data, and summarizes the terminology and the most common use cases. It covers the following topics:
- Use Cases for Big Data
- Characteristics of Big Data
- Challenges When Adopting Big Data
- Overview of the Hadoop Components
Use Cases for Big Data
Big Data technologies enabled use cases that were not feasible before, either due to large data volumes, or due to complex analytics. Today, harnessing the information and insights trapped in Big Data helps all business types:
- Retailers want to offer superior and personalized customer service by arming associates with information on customer buying behavior, current products, pricing, and promotions. Running Big Data analytics with Strategy can help store personnel provide personalized and relevant customer experience.
- Manufacturers face the constant demand for increased efficiency, lower prices, and sustained service levels, which forces them to reduce costs all along the supply chain. They also need consumption analysis by examining product sales in relation to consumer demographics and purchasing behavior. Using Strategy, manufacturers can run Big Data analytics on disparate sources to achieve perfect order rates and quality, and to get in-depth consumption patterns.
- Telcos need network capacity planning and optimization by correlating network usage, subscriber density, along with traffic and location data. Telcos using Strategy can run analytics to accurately monitor and forecast network capacity, plan effectively for potential outages, and run promotions.
- Healthcare aims to use of the petabytes of patient data that healthcare organizations possess to improve pharmaceutical sales, improve patient analysis, and allow for better payer solutions. Strategy can efficiently build and run applications to help fulfill such use cases.
- Government deals with security threats, population dynamics, budgeting and finance among other large scale operations. Strategy's analytical capabilities on large and complex datasets can provide government personnel deep insights allowing them to make informed policy decisions, eliminate waste and fraud, identify potential threats, and plan for the future needs of citizens.
Characteristics of Big Data
Big Data brings new challenges, and requires new approaches to deal with the challenges. As enterprises develop plans to enable Big Data uses cases, they need to consider the 5V characteristics of Big Data: Volume, Variety, Velocity, Variability and Value.
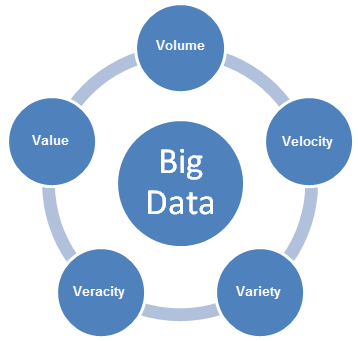
- Volume refers to the size of the data content generated that needs to be analyzed.
- Velocity refers to the speed at which new data is generated, and the speed at which data moves.
- Variety refers to the types of data that can be analyzed. Previously, the analytics industry focused on structured data that fit into tables and columns, and were typically stored in relational databases. However, much of the world's data is now unstructured, and can not be easily put into tables. On a broader level, the data can be divided into the following three categories. Each of them requires different approaches to analyze the data
- Structured Data is data whose structure is known. The data resides in a fixed field within a file or record.
- Unstructured Data is information that does not have a defined data model or organization. The data can be textual (body of email, instant messages, Word documents, PowerPoint presentations, PDFs) or non-textual (audio / video / image files).
- Semi-Structured Data is a cross between structured and unstructured data. The data is structured without a strict data model, such as event log data or strings of key-value pairs.
- Veracity refers to the trustworthiness of the data. With many sources and forms of Big Data, quality and accuracy are less controllable.
- Value refers to the ability to turn Big Data into clear business value, which requires access and analysis to produce meaningful output.
Challenges When Adopting Big Data
As enterprises develop solutions to mine the information present in their Big Data systems, they experience the following challenges:
- Performance: Organizations seeking to implement advanced analytics on Big Data struggle for achieving interactive performance.
- Data Federation: Real world applications require integration of data across projects. It is challenging to federate data stored in disparate formats and different sources.
- Data Cleansing: Enterprises find it challenging to cleanse varied forms of data in preparation for analytics.
- Security: Keeping the vast data lake secure is challenging, including proper use of encryption, recording data access histories, and accessing data through various industry standard authentication mechanisms.
- Time to Value: Enterprises are keen to shorten the time it takes to unleash the value from the data. Dealing with numerous sources for varied types of data, and using a web of point solutions to do so is often time consuming.
Overview of the Hadoop Components
This section describes the main components of the Hadoop ecosystem.
Apache Hadoop is an open-source software framework for distributed storage and distributed processing that enables organizations to store and query data, that is orders of magnitude larger than the data in traditional databases, and do it in a cost-effective, clustered environment. The picture below shows an architectural diagram of the Apache Hadoop components.
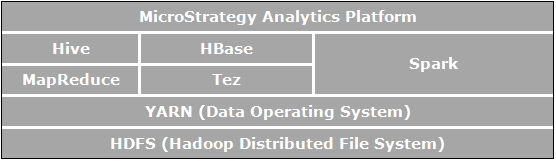
The elements which are directly related to business analytics and are relevant to the use cases enabled by Strategy are:
- HDFS (Hadoop Distributed File System) is the data storage file system used by Hadoop applications which runs on clusters of commodity machines. HDFS clusters consist of a NameNode that manages the file system metadata and DataNodes that store the actual data. HDFS allows storage of large imported files from applications outside of the Hadoop ecosystem and also staging of imported files to be processed by Hadoop applications.
- YARN (Yet Another Resource Negotiator) provides resource management and is a central platform to deliver operations, security, and data governance tools across Hadoop clusters for applications running on Hadoop.
- MapReduce is a distributed data processing model and execution environment that runs on large clusters of commodity machines. It uses the MapReduce algorithm which breaks down all operations into Map and/or Reduce functions.
- Tez is a generalized data flow programming framework that has been designed to provide improved performance for SQL query workflows as compared to MapReduce.
- Hive is a distributed data warehouse built on top of HDFS to manage and organize large amounts of data. Hive provides a schematized data store for housing large amounts of raw data and a SQL-like environment to execute analysis and query tasks on raw data in HDFS. Hive's SQL-like environment is the most popular way to query Hadoop. In addition, Hive can be used to channel SQL queries to a variety of query engines such as Map-Reduce, Tez, Spark, etc.
- Spark is a cluster computing framework. It provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
- HBase is a distributed, column-oriented database. It uses HDFS for its underlying storage, and supports both batch-style computations using MapReduce and point queries (random reads) that are transactional.
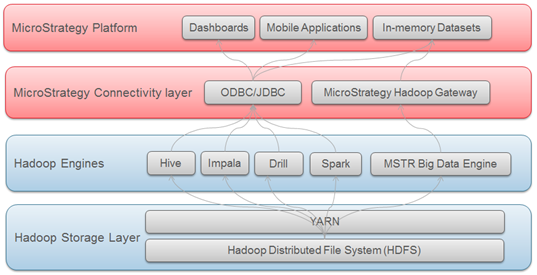
Connecting and Analyzing Big Data Sources in Strategy
The Big Data ecosystem has a number of SQL engines (Hive, Impala, Drill, etc.) that allow users to pass SQL queries to Big Data sources, and analyze the data as they would with traditional relational databases. The users can thus leverage the same analytical framework as they do when accessing structured data via SQL.
Strategy supports and certifies connectivity with several Big Data SQL engines. Similar to traditional databases, the connectivity to these SQL engines is via ODBC or JDBC drivers.
Strategy also offers a method allowing users to import data directly from the Hadoop file system (HDFS). This is achieved by using the Strategy Hadoop Gateway, which allows clients to by-pass the SQL query engines and load the data directly from the file system into Strategy in-memory cubes for analysis.
The diagram below shows the layers through which the data travels to reach Strategy from Hadoop systems.
Selecting Data Access Mode
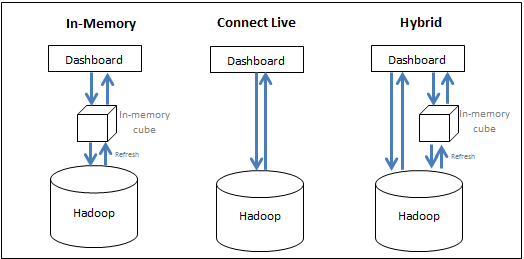
Strategy allows users to effectively leverage resources of the Big Data system and the BI system in tandem to deliver the best performance to run analytics. Users have the following options:
- Bring data into memory (in-memory approach) - data for the analysis is obtained exclusively from the in-memory cube. Strategy enables users to pull subsets of data, which could be up to hundreds of Gigabytes, from a Big Data source into an in-memory cube, and build reports/dashboards from the cube. Typically, a cube is setup to be published at regular intervals and is saved in the server's main memory, eliminating the time-consuming need to query the Big Data database.
- Access the data directly from its source (connect live approach) - data is accessed exclusively from the database. Strategy offers connectivity to various Big Data sources to run reports and dashboards dynamically live against the source.
- Adopt a hybrid approach - data is obtained from the in-memory cube and the database, as needed. The hybrid approach effectively leverages the power of both the above methods by allowing the user to seamlessly switch between them depending on the query submitted by the users. Strategy has dynamic sourcing technology that automatically determines whether a particular query can be answered by cubes or by the database and can channel the query accordingly.
The following figure summarizes the three approaches:
While the in-memory approach typically yields the fastest analytical performance, it may not be practical due to large volume of data. The following section discusses design consideration when deciding how the data should be accessed.
- In-Memory Approach: This approach provides faster performance; however, the data is limited to the small set that can be fit into the main memory, and depending on how often the in-memory data is updated, the data could be stale. Use this approach when:
- The final data is in an aggregated form and can be fit in the main memory of the BI machine
- The database is too slow for interactive analysis
- The user needs to remove the load off a transactional database
- The user needs to be offline
- Data Security can be setup at the BI level
- Connect Live Approach: In situations where the data for the dashboard needs to be current, or if the data is at a level of detail that all the data cannot be stored in the in-memory cube, then building a dashboard using the connect-live option could be a suitable approach. This allows the latest data to be fetched from the warehouse upon each execution. This approach is also useful in cases where the security is setup at the database level and a warehouse execution is needed for each user to be shown the data that they have access to. Use this approach when:
- The database is fast and responsive
- The user accesses data that is often updated in the database
- Data volumes are higher than the in-memory limit
- The users want a scheduled delivery of a pre-executed dashboard
- Data Security is setup at the database level
- Hybrid Approach: This approach is suitable for the use cases where the splash screen for the dashboard contains high level aggregated information from which the users can drill into the details. In such cases, the administrators can publish the aggregated data into an in-memory cube so that the dashboard's main screen is quick to appear, and then have the dashboard go against the lower level data in the Big Data system when the user drills down. The dynamic sourcing capability in Strategy makes building such applications easy as selected reports can be turned into cubes and Strategy automatically determines whether to go against the cubes or the database depending on the data that the user is requesting.
Supported Big Data Drivers and Vendors
Hadoop SQL engines are optimized for specific data manipulation. Based on the data type and the queries executed to access the data, we can divide use cases into the following five groups:
- Batch SQL – used for performing large scale transformations on Big Data
- Interactive SQL - enable interactive analysis on Big Data
- No-SQL – typically used for large scale data storage and quick transactional queries
- Unstructured data / search engines – analyzing text data or log data, mainly using search functionalities
- Cleansing and loading data into memory / Hadoop Gateway – optimized and used primarily for fast publishing of in-memory cubes
The following figure shows the mapping between the use cases and the engines currently supported in Strategy.
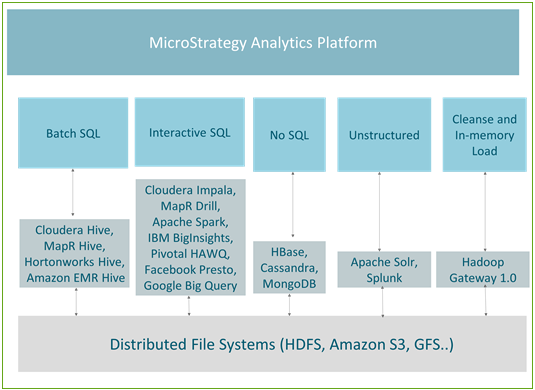
Batch Processing
Hive is the most popular querying mechanism for batch processing. As it is fault tolerant, it is recommended for ETL type jobs. All the leading Hadoop distributions (such as Hortonworks, Cloudera, MapR and Amazon EMR) offer Hive ODBC connectors. Strategy partners with all the above Hadoop vendors and offers a certified connectivity to Hadoop via Hive.
Hive is a good engine to use with the in-memory approach in Strategy or as a part of the Live-connect approach when it is paired with distribution services so that the database latency does not affect the end user. Since it uses MapReduce to process its queries, batch processing has high latency and is not suitable for interactive queries.
The following table lists connectivity information for the supported Hive distributions.
| Vendor | Connectivity | Use Case | Driver Name | Workflow |
|---|---|---|---|---|
| Cloudera Hive | ODBC | A tool that takes SQL and converts it into Map Reduce and can be used to do large scale ETL-like transformation on Data | Strategy Hive ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| Hortonworks Hive |
ODBC |
A tool that takes SQL and converts it into Map Reduce and can be used to do large scale ETL-like transformation on Data | Strategy Hive ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| MapR Hive | ODBC | A tool that takes SQL and converts it into Map Reduce and can be used to do large scale ETL-like transformation on Data | Strategy Hive ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| Amazon EMR Hive | ODBC | A tool that takes SQL and converts it into Map Reduce and can be used to do large scale ETL-like transformation on Data | Strategy Hive ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
Interactive Queries
Several Hadoop vendors developed fast performing engines to enable interactive queries. These engines use vendor/technology specific mechanisms to query HDFS, but still use Hive as a metastore. All such technologies are evolving at a fast pace to provide faster response times on large datasets in conjunction with advanced analytical capabilities. Interactive engines such as Impala, Drill, or Spark can be paired effectively with Strategy Dashboard to enable self-service data discovery on Hadoop. The engines are certified to work with Strategy.
The following table lists connectivity information for the supported distributions.
| Vendor | Connectivity | Use Case | Driver Name | Workflow |
|---|---|---|---|---|
| Cloudera Impala | ODBC | An open source massively parallel processing (MPP) SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala uses its own processing engine and can perform in-memory operations | Strategy Impala ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| Apache Drill | ODBC | An open source low latency query engine that is supported by MapR. It has the capability to discover schemas on-the-fly to be able to deliver self-service data exploration capabilities | Strategy Drill ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| Apache Spark | ODBC | A data-processing tool that operates on distributed data collections, and it is developed by one of the largest open source communities. With its in-memory processing; Spark is order of magnitude faster than MapReduce | Strategy ODBC Driver for Apache Spark SQL | Supported through MicroStrategy Architect and Strategy Data Import |
| IBM BigInsights | ODBC | A rich set of advanced analytics capabilities that allows enterprises to analyze massive volumes of structured and unstructured data in its native format on Hadoop | BigInsights ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
| Pivotal HAWQ | ODBC | A parallel SQL query engine that reads and writes data to HDFS natively. It provides users with a complete ANSI standard compliant SQL interface | Strategy ODBC Driver for Greenplum Wire Protocol | Supported through MicroStrategy Architect and Strategy Data Import |
| Google BigQuery | ODBC | A cloud based service that leverages Google's infrastructure to enable users to interactively query petabytes of data | Strategy Google BigQuery ODBC Driver | Supported through MicroStrategy Architect and Strategy Data Import |
NoSQL Sources
No SQL sources are optimized for large information storage and transactional queries. They can be paired effectively with the Multi-source option or the data blending option in Strategy so that the users can be shown higher level information from traditional databases and use the No-SQL source to provide the capability to drill down to the lowest level transaction data via integration with NoSQL sources.
The following table lists the NoSQL sources for which Strategy offers certified connectivity.
| Vendor | Connectivity | Use Case | Driver Name | Workflow |
|---|---|---|---|---|
| Apache Cassandra | JDBC | A key-value store, all the data consists of an indexed key and value | Cassandra JDBC Driver | Supported through Strategy Data Import |
| HBase | JDBC | A column store NoSQL database which instead of storing data in rows, stores data in tables as sections of columns of data. It offers high performance and a scalable architecture | Phoenix JDBC Driver | Supported through Strategy Data Import |
| MongoDB | ODBC | A document-oriented database that avoids the traditional table-based relational database structure, making the integration of data in certain types of applications easier and faster | Strategy MongoDB ODBC Driver | Supported through Strategy Data Import |
Unstructured Data/ Search Engines
Search engines are effective tools that allow users to search through large volumes of text data and add context to the data within their dashboards. This feature is powerful when leveraged with data blending in Strategy, allowing search data to be paired with traditional enterprise sources.
The following table lists connectivity information for the supported Hive distributions.
| Vendor | Connectivity | Use Case | Driver Name | Workflow |
|---|---|---|---|---|
| Apache Solr | Native | The most popular open source search engine that allows full text search, faceted searches and real time indexing. Strategy has built a connector to integrate with Solr. It provides the ability to perform dynamic searches, analyze and visualize the indexed data from Solr | built-in | Supported through Strategy Data Import |
| Splunk Enterprise | ODBC | A widely used proprietary search engine | Splunk ODBC Driver | Supported through Strategy Data Import |
Strategy Hadoop Gateway
Strategy offers a native connectivity to HDFS using Hadoop gateway. The Hadoop gateway bypasses Hive, accessing data directly from HDFS. Hadoop Gateway is a separate installation on HDFS nodes.
Hadoop gateway has been designed to optimize a use case of creating a large in-memory cubes when connecting to Hadoop. It employs the following techniques to achieve efficient batch data import from Hadoop:
- Bypasses Hive to access data directly: Communicates natively with HDFS running as a Yarn application bypassing Hive/ODBC. This further reduces data query and access time.
- Parallel loading of data from HDFS: Loads data into Strategy Intelligence Server via parallel threads, yielding higher throughput and reducing load time.
- Enables Push Down Data Cleansing for in-memory use case: Data wrangling operations are executed in Hadoop, enabling wrangling at scale.
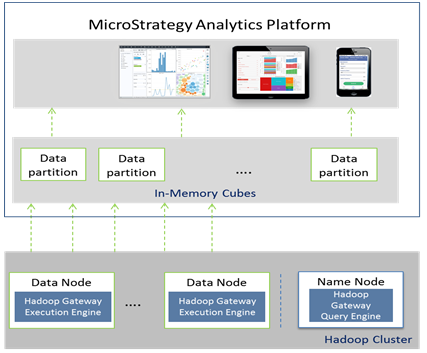
Architectural Overview of Hadoop Gateway
- Hadoop Gateway is a separate Strategy-proprietary installation, required to be installed on HDFS data and name nodes by installing:
- Hadoop Gateway Query Engine on HDFS Name Node
- Hadoop Gateway Execution Engine on HDFS Execution Engine
- Strategy Intelligence Server sends the query to Hadoop Gateway Execution Engine; the query then gets parsed and sent to data nodes for processing. Fetched data for the query then gets pushed from data nodes to Strategy Intelligence Server in parallel threads to get published into in-memory cubes.
The following figure shows Strategy Hadoop Gateway in an architecture diagram.
Hadoop Gateway Limitations
Currently, Hadoop Gateway has some limitations:
- Only text and csv files are supported
- Data wrangling is supported only for in-memory use case
- Multi-table data import is not supported
- For analytical capabilities, only aggregation and filtering is supported. The JOIN operation is not supported
- Kerberos security is supported with a shared service user vs. delegation for specific users
Example Workflows to Connect to Big Data Sources
This section contains examples of different workflows for connecting to Big Data sources from Strategy:
- To connect via Web Data Import to Hortonworks Hive
- To connect via Web Data Import to Hortonworks Hive
- To connect via Hadoop Gateway
Connecting via Developer to Hortonworks Hive
Business Intelligence administrators/developers can use MicroStrategy Developer to connect to a Big Data source using the steps mentioned below. The workflow is similar to the way traditional databases are integrated with Strategy. The steps can be divided into three conceptual areas:
- Building a connection to the source from Strategy. This includes creating an ODBC data source with appropriate connectivity details and creating a Database Instance object pointing to the ODBC source.
- Importing the tables from the source via Warehouse Catalog interface.
- Creating the required schema objects (such as attributes, facts, etc.) to build reports and dashboards.
In the steps below, Hortonworks Hive is shown as an example.
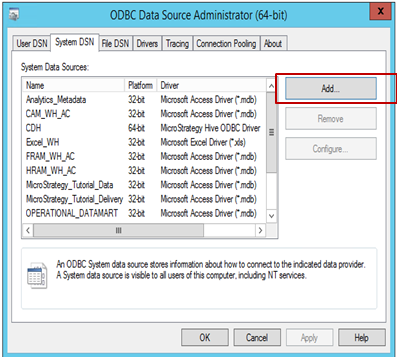
To build a connection to the source from Strategy:
-
Open the ODBC Data Source Administrator to build a data source connection to the source. Click Add to create a new connection.
-
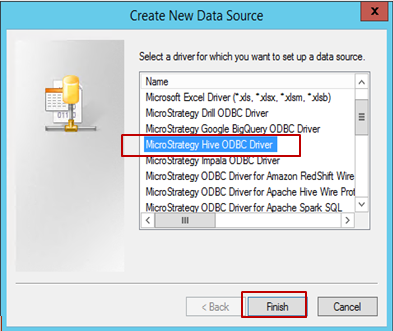
Select the driver (in this example, Hive ODBC is selected) and click Finish.
-
Fill in the appropriate connectivity details:
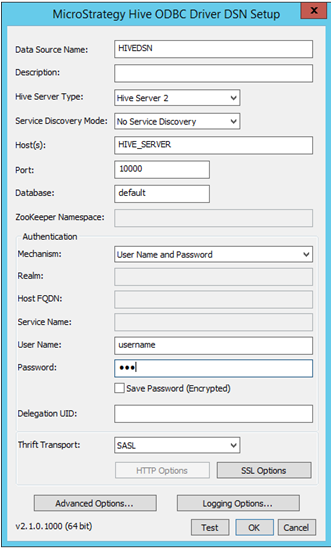
- Data Source Name: Name with which the connection gets saved
- Description: Optional
- Hive Server Type: Select the server as per environment
-
Service Discovery Mode: There are two Service Discovery Modes that can be used, as shown below. When the user selects 'Zookeeper', Strategy will allow to type in Zookeeper Namespace, as shown below.
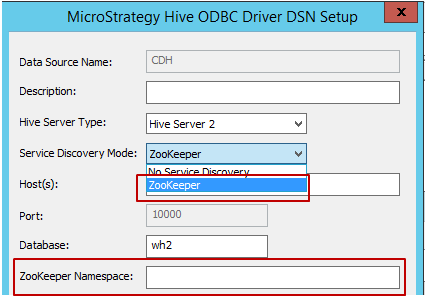
- Host, Port and Database Name: Required fields, fill in as per the environment.
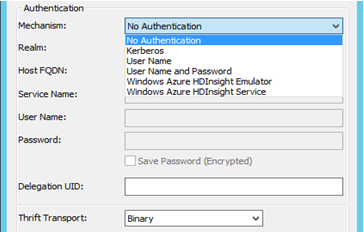
- Authentication: Strategy certifies different authentication mechanisms for Hortonworks Hive: No authentication, Kerberos, Username, Username and password. Based on the selection of Mechanism, the Thrift Transport Parameter will change. Such as:
- For No authentication – Thrift Transport Parameter is 'Binary'
- For Kerberos - Thrift Transport Parameter is 'SASL'
Username, Username and Password - Thrift Transport Parameter is 'SASL'
- After the connection details are selected and filled in, it can be tested using the 'Test' button.
-
Open MicroStrategy Developer. Log in to the Project -> Go to Configuration Manager -> Database Instances -> Create a New Database Instance.
If you are running Strategy Developer on Windows for the first time, run it as an administrator.
Right‑click the program icon and select Run as Administrator.
This is necessary in order to properly set the Windows registry keys. For more information, see KB43491.
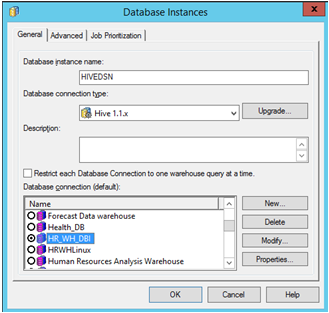
Select the 'Data Source Name' created previously for the source. Fill in the required user login and password.
-
Import Tables from the Source: Go to Schema -> Warehouse Catalog -> Select the Database Instance -> Drag and Drop the needed tables from the source.
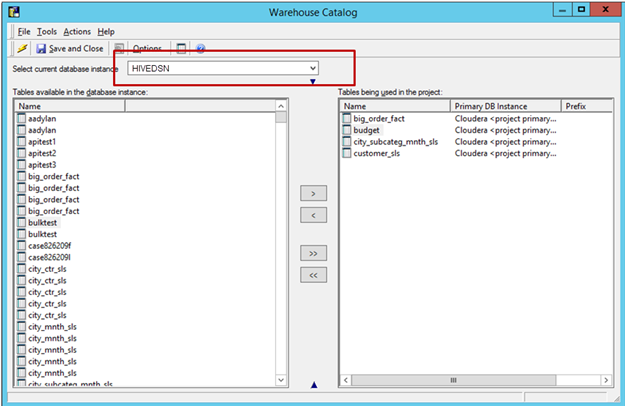
Save and close the catalog.
-
Build attributes and metrics as needed. Launch a new Strategy Report to build your analysis.
To connect via Web Data Import to Hortonworks Hive
Business Analysts and end users can leverage Strategy Web Data Import workflow to connect and analyze data just as they would with relational data sources. It can be broken into three conceptual areas: Connect, Import and Analyze.
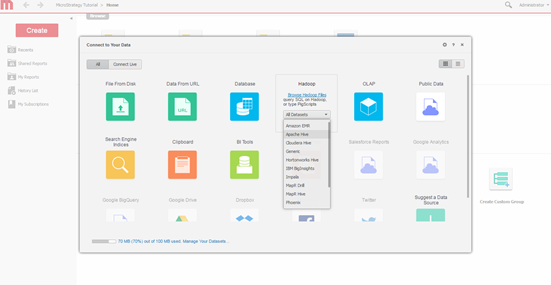
Below is the connectivity window from Strategy Web Data Import, connecting to Hortonworks Hive.
-
Select Query Engine. Select the engine to connect via the Strategy data import screen.
-
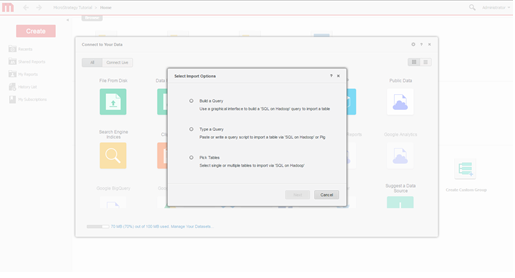
Select Import Options. Select whether to build a query, type a query, or pick tables. The pick tables approach is recommended because it provides the best use of Strategy's modelling capabilities.
-
Create connection. Define a new connection to the Hadoop system.
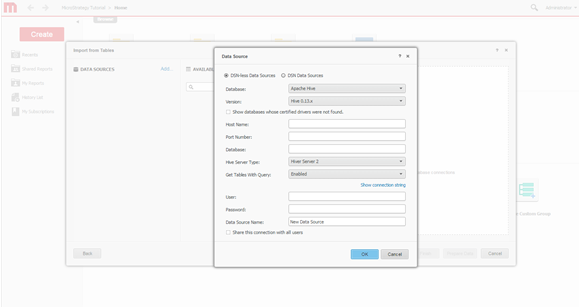
-
Select tables. Select tables from which the data will be accessed.
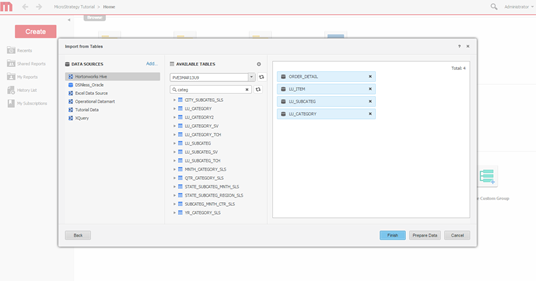
-
Model data. Optionally, model the tables, change the name of the attributes and metrics, exclude columns from import, etc.
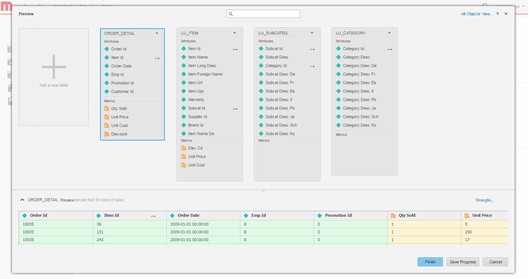
-
Define data access mode. Choose whether to publish the data as an in-memory cube or via Live connect mode.
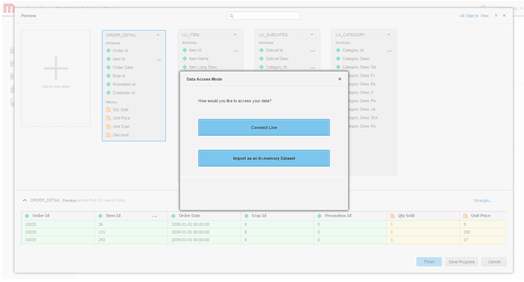
- Build dashboard.
To connect via Hadoop Gateway
Hadoop Gateway can be leveraged from Strategy Web Data Import, following the typical data import workflow:
- Build connection to the Hadoop/HDFS cluster
- Browse and import folders from HDFS
- Cleanse the data (optional)
- Publish the data as an in-memory cube in the Strategy Intelligence Server, and analyze the data through a dashboard
Below are the details for each of the steps.
-
Build connection.
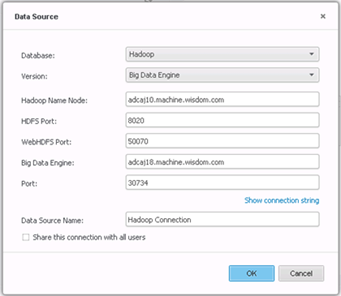
-
Select tables to be imported.
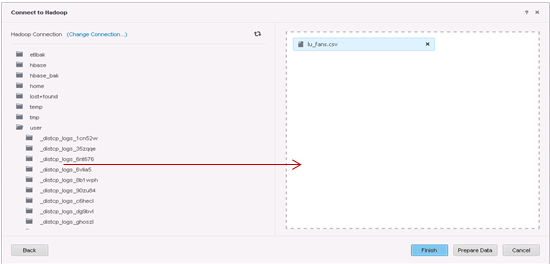
-
Prepare the data using Data Wrangler.
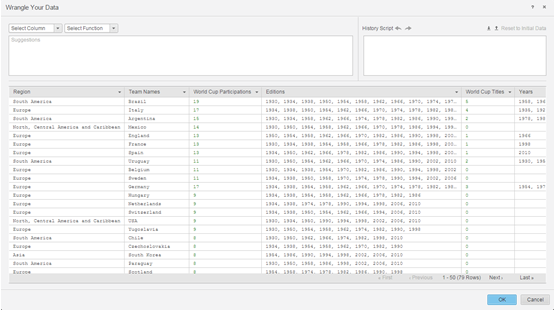
- The next steps are then publishing the in-memory cubes in to Strategy Intelligence Server and using the visual insight interface to build a dashboard.