Version 2021
Analisi dei Big Data in MicroStrategy
Nel settore del business intelligence e dell'analisi, i Big Data interessano principalmente il consumo di grandi volumi di dati che non possono essere gestiti dai sistemi tradizionali. I Big Data richiedono nuove tecnologie per archiviare, elaborare, ricercare, analizzare e visualizzare grandi set di dati.
Per ulteriori informazioni, vedere le seguenti sezioni:
Nuovi utenti: Panoramica – fornisce un'introduzione generale ai Big Data
Utenti esperti:
- Connessione e analisi delle origini dei Big Data in MicroStrategy – tratta le modalità di utilizzo di MicroStrategy per collegarsi alle origini di Big Data
- Flussi di lavoro di esempio per la connessione a origini di Big Data – presenta esempi di configurazione di connessioni
Panoramica dei Big Data
Questa sezione funge da introduzione generale ai Big Data e riassume la terminologia e i casi di utilizzo più comuni. Vengono trattati i seguenti argomenti:
- Casi di utilizzo per i Big Data
- Caratteristiche dei Big Data
- Sfide dell'adozione dei Big Data
- Panoramica dei componenti Hadoop
Casi di utilizzo per i Big Data
Le tecnologie Big Data consentono casi di utilizzo che non erano possibili in precedenza, a causa di volumi di dati troppo elevati o di analisi complesse. Oggi l'utilizzo di informazioni contenute nei Big Data aiuta tutti i tipi di aziende:
- I rivenditori al dettaglio desiderano offrire un servizio clienti superiore e personalizzato dotando i collaboratori di informazioni sui comportamenti di acquisto dei clienti, sui prodotti attuali, sui prezzi e sulle promozioni. L'esecuzione di analisi di Big Data con MicroStrategy può consentire al personale di fornire ai clienti un'esperienza personalizzata e pertinente.
- I produttori affrontano una richiesta costante di maggiore efficienza, prezzi più bassi e livelli di assistenza sostenuti, il che li spinge a ridurre i costi lungo l'intera supply chain. Hanno anche bisogno di poter disporre di analisi dei consumi esaminando le vendite di prodotti in relazione alle informazioni demografiche dei consumatori e al loro comportamento di acquisto. Con MicroStrategy, i produttori possono eseguire analisi Big Data in base a origini diverse per ottenere tassi e qualità delle vendite perfetti e per comprendere in dettaglio i modelli di consumo.
- Il settore delle telecomunicazioni ha bisogno di pianificazione e ottimizzazione delle capacità di rete mettendo in correlazione l'utilizzo della rete con la densità degli abbonati, assieme ai dati relativi a traffico e posizione. Le società di telecomunicazioni che utilizzano MicroStrategy sono in grado di eseguire analisi per monitorare e prevedere con precisione la capacità di rete, pianificare in modo efficace la strategia in caso di possibili interruzioni dei servizi e gestire promozioni.
- Il settore sanitario ambisce a utilizzare i petabyte dei dati relativi ai pazienti in possesso delle organizzazioni sanitarie per migliorare le vendite farmaceutiche, migliorare le analisi dei pazienti e consentire migliori soluzioni di pagamento. MicroStrategy può creare ed eseguire in modo efficace applicazioni volte a soddisfare tali casi di utilizzo.
- Il settore governativo deve gestire minacce per la sicurezza, dinamiche demografiche, interventi di bilancio e finanziari assieme ad altre operazioni su larga scala. Le capacità analitiche di MicroStrategy di dataset grandi e complessi possono fornire al personale governativo informazioni dettagliate, consentendo di prendere decisioni politiche ponderate, eliminando sprechi e frodi, identificando possibili minacce e pianificando soluzioni per le future esigenze dei cittadini.
Caratteristiche dei Big Data
I Big Data comportano nuove sfide e richiedono nuove strategie per gestirle. Quando le aziende sviluppano programmi per l'abilitazione dei casi di utilizzo dei Big Data, devono considerare le 5V caratteristiche dei Big Data: Volume, Varietà, Velocità, Variabilità e Valore.

- Volume fa riferimento alle dimensioni dei contenuti di dati generati che devono essere analizzati.
- Velocità fa riferimento alla velocità con cui i nuovi dati vengono generati, e alla velocità con cui tali dati si muovono.
- Varietà fa riferimento ai tipi di dati che possono essere analizzati. In precedenza, il settore delle analisi si concentrava su dati strutturati che rientravano in tabelle e colonne e che venivano solitamente archiviati in database relazionali. Tuttavia, gran parte dei dati globali non è attualmente strutturato e non può essere inserito facilmente in tabelle. A un livello più ampio, i dati possono essere suddivisi nelle tre seguenti categorie: Ognuna di esse richiede strategie diverse per l'analisi dei dati.
- Dati strutturati: sono i dati la cui struttura è nota. I dati sono contenuti in un campo fisso all'interno di un file o record.
- Dati non strutturati: sono informazioni che non possiedono un modello o un'organizzazione dati definiti. I dati possono essere di testo (corpo di un'e-mail, messaggeria istantanea, documenti Word, presentazioni di PowerPoint, PDF) o non testuali (file audio/video/immagine).
- Dati semistrutturati: sono un incrocio tra dati strutturati e non strutturati. I dati vengono strutturati senza alcun modello dati rigido, come dati di registro di eventi o stringhe di coppie chiave-valore.
- Veridicità: fa riferimento all'affidabilità dei dati. Con numerosi moduli e origini dei Big Data, qualità e precisione sono meno controllabili.
- Valore: fa riferimento alla capacità di tradurre Big Data in un chiaro valore aziendale, il che richiede possibilità di accesso e analisi per produrre un risultato significativo.
Sfide dell'adozione dei Big Data
Man mano che le aziende sviluppano soluzioni per accedere alle informazioni presenti nei loro sistemi Big Data, devono affrontare le seguenti sfide:
- Prestazioni: Le organizzazioni che desiderano implementare analisi avanzate sui Big Data fanno fatica a ottenere prestazioni interattive.
- Federazione di dati: le applicazioni nel mondo reale richiedono l'integrazione di dati tra diversi progetti. È difficile attuare una federazione di dati archiviati in diversi formati e origini.
- Pulizia dei dati: le imprese trovano difficoltà nel pulire diversi moduli di dati in preparazione all'analisi.
- Sicurezza: garantire la sicurezza di un grande data lake è difficile, compresi l'utilizzo adeguato della crittografia, la registrazione della cronologia di accesso dei dati e l'accesso di dati tramite diversi meccanismi di autenticazione standard del settore.
- Tempo prima di ottenere valore: le imprese desiderano ridurre il tempo necessario affinché i dati rilascino il loro valore. La gestione di numerose origini per diversi tipi di dati e l'utilizzo di una rete di soluzioni puntuali per farlo spesso richiedono molto tempo.
Panoramica dei componenti Hadoop
Questa sezione descrive i principali componenti dell'ecosistema Hadoop.
Apache Hadoop è un framework software open-source per l'archiviazione e l'elaborazione distribuite, che consente alle organizzazioni di archiviare e di eseguire query sui dati, in ordini di grandezza superiori rispetto ai dati nei database tradizionali e di farlo in un ambiente economico e raggruppato. L'immagine qui sotto mostra un diagramma dell'architettura dei componenti di Apache Hadoop.
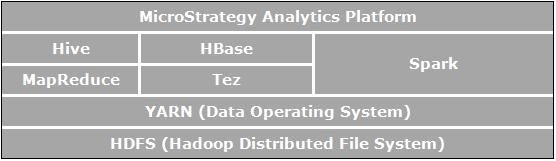
Gli elementi direttamente correlati all'analisi aziendale e che sono pertinenti per i casi di utilizzo abilitati da MicroStrategy sono:
- HDFS (Hadoop Distributed File System), il file system di archiviazione dei dati utilizzato dalle applicazioni Hadoop che viene eseguito su cluster di computer di comune utilizzo. I cluster HDFS sono costituiti da un NameNode che gestisce i metadata del file system e da DataNode che archiviano i dati. HDFS consente l'archiviazione di file importati di grandi dimensioni da applicazioni esterne all'ecosistema Hadoop e si occupa inoltre della preparazione di file importati da elaborare dalle applicazioni Hadoop.
- YARN (Yet Another Resource Negotiator) fornisce la gestione delle risorse ed è una piattaforma centrale per distribuire strumenti di operazioni, sicurezza e data governance tra i cluster di Hadoop per applicazioni in esecuzione su Hadoop.
- MapReduce è un modello di elaborazione distribuito e un ambiente di esecuzione che viene eseguito su grandi cluster di comuni PC. Utilizza l'algoritmo MapReduce che scompone tutte le operazioni in funzioni Map e/o Reduce.
- Tez è un framework generalizzato di programmazione di flusso di dati progettato per fornire prestazioni superiori ai flussi di lavoro di query SQL rispetto a MapReduce.
- Hive è un data warehouse distribuito creato sopra HDFS per gestire e organizzare grandi quantità di dati. Hive fornisce un archivio dati schematizzato per ospitare grandi quantità di dati non elaborati e un ambiente simile all'SQL per eseguire analisi e operazioni di query sui dati non elaborati in HDFS. L'ambiente di Hive simile a quello di SQL è il modo più diffuso per effettuare query su Hadoop. Inoltre, Hive può essere utilizzato per canalizzare le query SQL verso diversi motori di query quali Map-Reduce, Tez, Spark, ecc.
- Spark è un framework di elaborazione cluster. Fornisce un modello di programmazione semplice ed espressivo che supporta un ampio ventaglio di applicazioni, tra cui ETL, machine learning, stream processing e calcolo grafico.
- HBase è un database distribuito e orientato a colonne. Utilizza HDFS per la propria archiviazione sottostante e supporta sia i calcoli in stile batch con MapReduce che query puntuali (letture random) che sono transazionali.
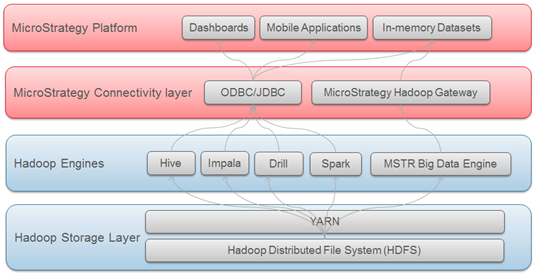
Connessione e analisi delle origini dei Big Data in MicroStrategy
L'ecosistema Big Data presenta diversi motori SQL (Hive, Impala, Drill, ecc.) che consentono agli utenti di trasmettere le query SQL a origini di Big Data e di analizzare i dati come farebbero con database relazionali tradizionali. Gli utenti possono quindi avvalersi dello stesso framework analitico che utilizzano quando accedono a dati strutturati tramite SQL.
MicroStrategy supporta e certifica la connettività con diversi motori SQL Big Data. Come per i database tradizionali, la connettività a questi motori SQL avviene tramite driver ODBC o JDBC.
MicroStrategy offre inoltre un metodo che consente agli utenti di importare i dati direttamente dal file system Hadoop (HDFS). Ciò si ottiene utilizzando MicroStrategy Hadoop Gateway, che consente ai client di ignorare i motori di query SQL e di caricare i dati direttamente dal file system nei cubi in memoria per procedere all'analisi.
Il diagramma sottostante visualizza i livelli attraverso i quali i dati viaggiano per raggiungere MicroStrategy dai sistemi Hadoop.
Selezione della modalità di accesso ai dati
MicroStrategy consente agli utenti di avvalersi in modo efficace di risorse del sistema Big Data e del sistema BI per offrire le migliori prestazioni di esecuzione di analisi. Gli utenti possono scegliere tra le opzioni seguenti:
- Portare i dati in memoria (approccio in memoria) - i dati per l'analisi vengono ottenuti esclusivamente dal cubo in-memoria. MicroStrategy consente agli utenti di estrarre subset di dati, che potrebbero raggiungere le centinaia di Gigabyte, da un'origine Big Data in un cubo in memoria e di creare report/dossier dal cubo. Solitamente un cubo è configurato per essere pubblicato a intervalli regolari e viene salvato nella memoria principale del server, eliminando le lunghe operazioni di query sul database Big Data.
- Accedere ai dati direttamente dall'origine (approccio di connessione in tempo reale) - l'accesso ai dati avviene esclusivamente dal database. MicroStrategy offre connettività a diverse origini Big Data per eseguire report e dossier in modo dinamico in tempo reale rispetto all'origine.
- Adottare un approccio ibrido - i dati vengono ottenuti dal cubo in memoria e dal database, in base alle necessità. Questo approccio ibrido si avvale in modo efficace dei vantaggi dei due metodi sopraelencati, consentendo all'utente di passare senza problemi dall'uno all'altro in base alla query inviata dagli utenti. MicroStrategy dispone di una tecnologia di sourcing dinamico che stabilisce automaticamente se una query specifica può ottenere risposta dai cubi o dal database e può indirizzare la query di conseguenza.
La seguente figura sintetizza le tre strategie:
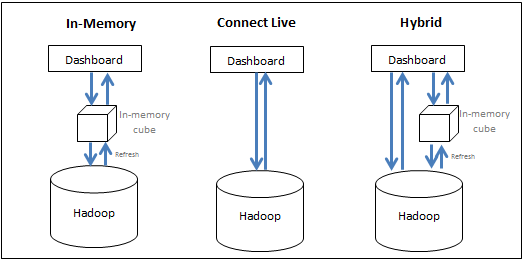
Sebbene l'approccio in memoria solitamente consenta di ottenere le prestazioni analitiche più rapide, potrebbe non essere pratico a causa dell'elevato volume di dati. La seguente sezione analizza le considerazioni di progettazione al momento di scegliere la modalità di accesso dei dati.
- Approccio in memoria: questa strategia fornisce prestazioni più rapide; tuttavia, i dati vengono limitati al piccolo gruppo che può rientrare nella memoria principale e in base alla frequenza di aggiornamento dei dati in memoria, i dati potrebbero risultare obsoleti. Utilizzare questo metodo quando:
- I dati finali sono in forma aggregata e possono rientrare nella memoria principale del computer BI
- Il database è troppo lento per l'analisi interattiva
- L'utente deve rimuovere il carico da un database transazionale
- L'utente deve trovarsi offline
- La sicurezza dei dati può essere impostata a livello BI
- Approccio di connessione in tempo reale: in situazioni in cui i dati per il dossier devono essere aggiornati o se i dati si trovano a un livello di dettaglio che non consente l'archiviazione di tutti i dati nel cubo in memoria, la creazione di un dossier con l'opzione di connessione in tempo reale potrebbe rappresentare una soluzione adeguata. Ciò consente ai dati più aggiornati di essere recuperati dal warehouse a ogni esecuzione. Questo approccio è utile anche in casi in cui la sicurezza è configurata a livello di database e un'esecuzione del warehouse è necessaria affinché ogni utente possa visualizzare i dati a cui ha accesso. Utilizzare questo metodo quando:
- Il database è rapido e reattivo
- L'utente accede a dati che vengono aggiornati con frequenza nel database
- I volumi dei dati sono superiori del limite in memoria
- Gli utenti desiderano una consegna programmata di un dossier pre-eseguito.
- La sicurezza dei dati è impostata a livello di database
- Approccio ibrido: questo approccio è adatto per i casi di utilizzo in cui la schermata iniziale del dossier contiene un livello elevato di informazioni aggregate da cui gli utenti possono eseguire il drilling nei dettagli. In tali casi, gli amministratori possono pubblicare i dati aggregati in un cubo in memoria in modo che la schermata principale del dossier compaia rapidamente e quindi il dossier si dirigerà verso il livello di dati inferiore nel sistema Big Data quando l'utente segue il drilling. La capacità di sourcing dinamico di MicroStrategy semplifica la creazione di tali applicazioni poiché i report selezionati possono essere tradotti in cubi e MicroStrategy stabilisce automaticamente se dirigersi verso i cubi o il database in base ai dati richiesti dall'utente.
Driver e rivenditori di Big Data supportati
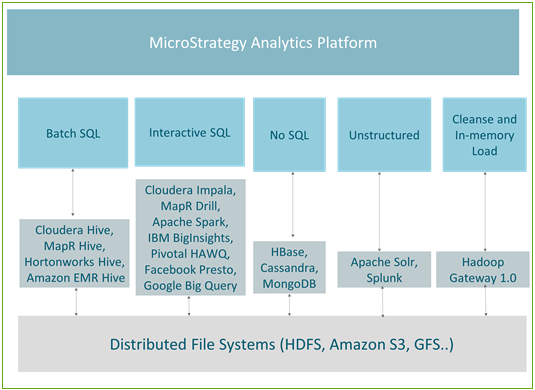
I motori SQL Hadoop sono ottimizzati per la manipolazione di dati specifici. In base al tipo di dati e alle query eseguite per accedere ai dati, è possibile suddividere i casi di utilizzo nei seguenti cinque gruppi:
- SQL in batch – utilizzato per l'esecuzione di trasformazioni in grande scala sui Big Data
- SQL interattivo - consente l'analisi interattiva sui Big Data
- NoSQL – solitamente utilizzato per l'archiviazione di dati su grande scala e per rapide query transazionali
- Dati non strutturati/motori di ricerca – analisi di dati di testo o di registro, principalmente utilizzando funzionalità di ricerca
- Pulizia e caricamento di dati in memoria/Hadoop Gateway – ottimizzato e utilizzato principalmente per la rapida pubblicazione di cubi in memoria
La seguente figura riporta la mappatura tra casi di utilizzo e i motori attualmente supportati in MicroStrategy.
Elaborazione in batch
Hive è il meccanismo di query più diffuso per l'elaborazione in batch. Poiché è a tolleranza d'errore, è consigliato per i lavori di tipo ETL. Tutte le principali distribuzioni Hadoop (come Hortonworks, Cloudera, MapR e Amazon EMR) offrono connettori Hive ODBC. MicroStrategy collabora con tutti i rivenditori Hadoop sopraelencati e offre una connettività certificata a Hadoop tramite Hive.
Hive è un buon motore da utilizzare con l'approccio in memoria in MicroStrategy o come parte di un approccio di connessione in tempo reale quando è accompagnato da servizi di distribuzione in modo che la latenza del database non penalizzi l'utente finale. Poiché utilizza MapReduce per elaborare le query, l'elaborazione in batch presenta una latenza elevata e non è adatta per le query interattive.
Nella seguente tabella vengono elencate le informazioni di connettività per le distribuzioni Hive supportate.
| Rivenditore | Connettività | Caso di utilizzo | Nome driver | Flusso di lavoro |
|---|---|---|---|---|
| Cloudera Hive | ODBC | Uno strumento che prende SQL e lo converte in Map Reduce e può essere utilizzato per trasformazioni su larga scala di tipo ETL sui dati | MicroStrategy Hive ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Hortonworks Hive |
ODBC |
Uno strumento che prende SQL e lo converte in Map Reduce e può essere utilizzato per trasformazioni su larga scala di tipo ETL sui dati | MicroStrategy Hive ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| MapR Hive | ODBC | Uno strumento che prende SQL e lo converte in Map Reduce e può essere utilizzato per trasformazioni su larga scala di tipo ETL sui dati | MicroStrategy Hive ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Amazon EMR Hive | ODBC | Uno strumento che prende SQL e lo converte in Map Reduce e può essere utilizzato per trasformazioni su larga scala di tipo ETL sui dati | MicroStrategy Hive ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
Query interattive
Diversi rivenditori di Hadoop hanno sviluppato motori con rapide prestazioni per abilitare le query interattive. Tali motori utilizzano meccanismi specifici per rivenditore/tecnologia per inviare query a HDFS, ma utilizzando ancora Hive come metastore. Tutte queste tecnologie stanno evolvendo rapidamente per fornire tempi di risposta più rapidi su dataset di grandi dimensioni assieme a capacità analitiche avanzate. Motori interattivi quali Impala, Drill o Spark possono essere affiancati in modo efficace con MicroStrategy Dossier per consentire una scoperta autonoma dei dati in Hadoop. I motori sono certificati per funzionare con MicroStrategy.
Nella seguente tabella vengono elencate le informazioni di connettività per le distribuzioni supportate.
| Rivenditore | Connettività | Caso di utilizzo | Nome driver | Flusso di lavoro |
|---|---|---|---|---|
| Cloudera Impala | ODBC | Un motore open source di query SQL per elaborazione a parallelismo massivo (MPP) per i dati archiviati in un cluster di computer che esegue Apache Hadoop. Impala utilizza il proprio motore di elaborazione e può eseguire operazioni in memoria. | MicroStrategy Impala ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Apache Drill | ODBC | Un motore per query open source a bassa latenza supportato da MapR. Ha la capacità di scoprire rapidamente schemi per offrire capacità di esplorazione dati self-service. | MicroStrategy Drill ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Apache Spark | ODBC | Uno strumento di elaborazione dei dati che opera su raccolte di dati distribuiti ed è sviluppato da una della più grandi community open source. Con la sua elaborazione in memoria, Spark è molto più rapido di MapReduce | MicroStrategy ODBC Driver per Apache Spark SQL | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| IBM BigInsights | ODBC | Una ricca serie di capacità analitiche avanzate che consentono alle aziende di analizzare enormi volumi di dati strutturati e non strutturati nel formato nativo in Hadoop | BigInsights ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Pivotal HAWQ | ODBC | Un motore di query SQL parallelo in grado di leggere e scrivere dati in HDFS in modalità nativa. Fornisce agli utenti un'interfaccia SQL totalmente conforme allo standard ANSI | MicroStrategy ODBC Driver per Greenplum Wire Protocol | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
| Google BigQuery | ODBC | Un servizio cloud-based che si avvale dell'infrastruttura di Google per consentire agli utenti di eseguire query in modo interattivo su petabyte di dati. | MicroStrategy Google BigQuery ODBC Driver | Supportato tramite MicroStrategy Architect e Importazione dati di MicroStrategy |
Origini NoSQL
Le origini NoSQL sono ottimizzate per l'archiviazione di grandi quantità di informazioni e per query transazionali. Possono essere accompagnate in modo efficace dall'opzione origine multipla o dall'opzione di fusione dei dati in MicroStrategy in modo che agli utenti possa essere mostrato un livello di informazioni superiore rispetto a quello dei database tradizionali e possano utilizzare l'origine NoSQL per ottenere la capacità di eseguire il drill down fino al livello più basso di dati transazionali tramite l'integrazione con origini NoSQL.
Nella seguente tabella vengono elencate le origini NoSQL per cui MicroStrategy offre connettività certificata.
| Rivenditore | Connettività | Caso di utilizzo | Nome driver | Flusso di lavoro |
|---|---|---|---|---|
| Apache Cassandra | JDBC | Un database chiave-valore, tutti i dati consistono in una chiave e in un valore indicizzati | Cassandra JDBC Driver | Supportato tramite Importazione dati MicroStrategy |
| HBase | JDBC | Un database NoSQL a colonne che anziché archiviare i dati in righe, li archivia in tabelle come sezioni di colonne di dati. Offre elevate prestazioni e un'architettura scalabile | Phoenix JDBC Driver | Supportato tramite Importazione dati MicroStrategy |
| MongoDB | ODBC | Un database orientato ai documenti che evita la tradizionale struttura del database relazionale basato su tabelle, rendendo l'integrazione dei dati in alcuni tipi di applicazioni più semplice e rapida | MicroStrategy MongoDB ODBC Driver | Supportato tramite Importazione dati MicroStrategy |
Dati non strutturati/motori di ricerca
I motori di ricerca sono strumenti efficaci che consentono agli utenti di effettuare ricerche in volumi elevati di dati di testo e di aggiungere contesto ai dati all'interno dei loro dossier. Tale funzionalità è potente se utilizzata con la fusione dei dati in MicroStrategy, che consente la ricerca di dati affiancata da origini aziendali tradizionali.
Nella seguente tabella vengono elencate le informazioni di connettività per le distribuzioni Hive supportate.
| Rivenditore | Connettività | Caso di utilizzo | Nome driver | Flusso di lavoro |
|---|---|---|---|---|
| Apache Solr | Nativo | Il motore di ricerca open source più diffuso che consente una ricerca full-text, ricerche in base a facet e indicizzazione in tempo reale. MicroStrategy ha sviluppato un connettore da integrare con Solr. Tale connettore fornisce la capacità di eseguire ricerche dinamiche, analizzare e visualizzare i dati indicizzati di Solr | Integrato | Supportato tramite Importazione dati MicroStrategy |
| Splunk Enterprise | ODBC | Un motore di ricerca proprietario ampiamente utilizzato | Splunk ODBC Driver | Supportato tramite Importazione dati MicroStrategy |
MicroStrategy Hadoop Gateway
MicroStrategy offre una connettività nativa a HDFS mediante Hadoop Gateway. Hadoop Gateway ignora Hive, accedendo ai dati direttamente da HDFS. Hadoop Gateway è un'installazione separata sui nodi HDFS.
Hadoop Gateway è stato sviluppato per ottimizzare un caso di utilizzo di creazione di grandi cubi in memoria al momento della connessione ad Hadoop. Utilizza le seguenti tecniche per ottenere un'importazione di dati in batch efficiente da Hadoop:
- Ignora Hive per accedere direttamente ai dati: comunica in modalità nativa con HDFS in esecuzione come un'applicazione Yarn, ignorando Hive/ODBC. Ciò riduce ulteriormente i tempi di accesso e le query sui dati.
- Utilizza il caricamento parallelo dei dati da HDFS: carica i dati in MicroStrategy Intelligence Server tramite thread paralleli, ottenendo una velocità effettiva più elevata e riducendo i tempi di caricamento.
- Abilita la pulizia di dati con scorrimento verso il basso per casi di utilizzo in memoria: le operazioni di wrangling dei dati vengono eseguite in Hadoop, consentendo il wrangling in larga scala.
Panoramica dell'architettura di Hadoop Gateway
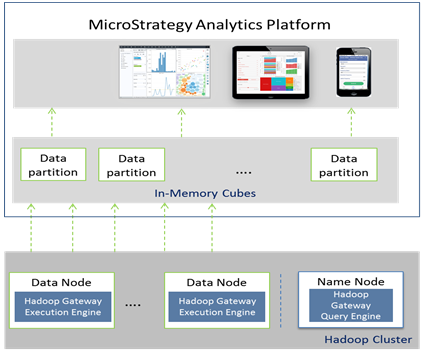
- Hadoop Gateway è un'installazione proprietaria separata di MicroStrategy, richiesta sui dati e sui namenode HDFS mediante l'installazione di:
- Motore di query Hadoop Gateway sul NameNode di HDFS
- Motore di esecuzione Hadoop Gateway sul motore di esecuzione HDFS
- MicroStrategy Intelligence Server invia la query al motore di esecuzione Hadoop Gateway; la query viene quindi analizzata e inviata ai datanode per l'elaborazione. I dati recuperati per la query vengono quindi inoltrati dai datanode a MicroStrategy Intelligence Server in thread paralleli per venire pubblicati in cubi in memoria.
La seguente figura mostra MicroStrategy Hadoop Gateway in un diagramma dell'architettura.
Limiti di Hadoop Gateway
Attualmente Hadoop Gateway presenta alcuni limiti:
- Solo i file di testo e csv sono supportati
- Il wrangling dei dati è supportato solo per i casi di utilizzo in memoria
- L'importazione di dati da tabelle multiple non è supportata
- Per le capacità analitiche, sono supportate solo l'aggregazione e il filtraggio L'operazione JOIN non è supportata
- Il sistema di sicurezza Kerberos è supportato con un servizio condiviso utenti o delegazione per utenti specifici
Flussi di lavoro di esempio per la connessione a origini di Big Data
La presente sezione contiene esempi di diversi flussi di lavoro per la connessione a origini di Big Data da MicroStrategy:
- Per connettersi tramite l'importazione di dati Web a Hortonworks Hive
- Per connettersi tramite l'importazione di dati Web a Hortonworks Hive
- Per connettersi tramite Hadoop Gateway
Connessione tramite Developer a Hortonworks Hive
Gli amministratori/sviluppatori di business intelligence possono utilizzare MicroStrategy Developer per connettersi all'origine Big Data, attenendosi alla procedura riportata di seguito. Il flusso di lavoro è simile al modo in cui i database tradizionali sono integrati in MicroStrategy. I passaggi possono essere suddivisi in tre aree concettuali:
- Creazione di una connessione all'origine da MicroStrategy. Questa include la creazione di un'origine dati ODBC con dettagli di connettività adeguati e la creazione di un oggetto di istanza di database che punti all'origine ODBC.
- Importazione di tabelle dall'origine tramite l'interfaccia del catalogo warehouse.
- Creazione degli oggetti dello schema richiesti (quali attributi fatti, ecc.) per creare report e dossier.
Nella procedura riportata di seguito, Hortonworks Hive viene visualizzato come esempio.
Per creare una connessione all'origine da MicroStrategy:
-
Aprire l'Amministratore origini dati ODBC per creare una connessione di origine dati all'origine. Fare clic su Aggiungi per creare una nuova connessione.
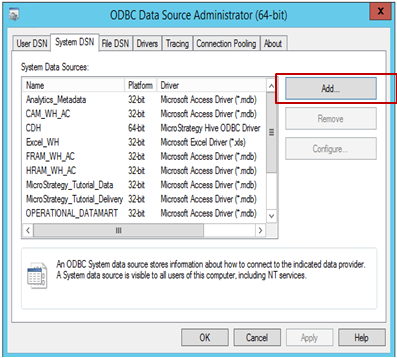
-
Selezionare il driver (in questo esempio è selezionato Hive ODBC) e fare clic su Fine.

-
Compilare i dati di connettività pertinenti:
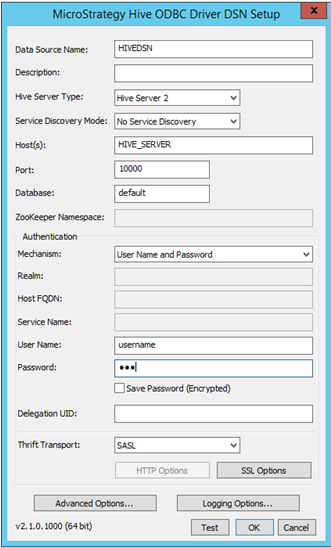
- Nome origine dati: nome con cui la connessione viene salvata
- Descrizione: Facoltativo
- Tipo server Hive: selezionare il server in base all'ambiente
-
Modalità di individuazione servizio (Service Discovery Mode): vi sono due modalità di individuazione del servizio che è possibile utilizzare, come indicato di seguito. Quando l'utente seleziona "Zookeeper", MicroStrategy consentirà la digitazione in Zookeeper Namespace, come illustrato di seguito.
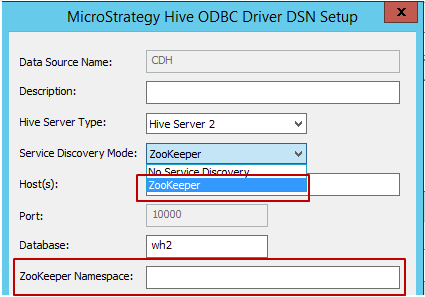
- Nome host, porta e database: campi obbligatori, compilare in base all'ambiente.
- Autenticazione: MicroStrategy certifica diversi meccanismi di autenticazione per Hortonworks Hive: nessun autenticazione, Kerberos, nome utente, nome utente e password. In base alla selezione del meccanismo, il parametro di trasporto Thrift verrà modificato. Ad esempio:
- Con nessuna autenticazione - il parametro di trasporto Thrift è "binario"
- Con Kerberos - il parametro di trasporto Thrift è "SASL"
Con nome utente, nome utente e password - il parametro di trasporto Thrift è "SASL"
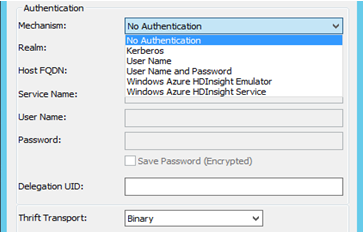
- Una volta selezionate e immesse le informazioni relative alla connessione, questa può essere testata usando il pulsante "Test".
-
Aprire MicroStrategy Developer. Accedere a Progetto -> andare a Configuration Manager -> Istanze di database -> Per creare una nuova istanza di database, fai clic su Nuovo.
Se si esegue MicroStrategy Developer su Windows per la prima volta, eseguirlo come amministratore.
Fare clic con il pulsante destro del mouse sull'icona del programma e selezionare Esegui come amministratore.
Ciò è necessario per impostare correttamente le chiavi di registro di Windows. Per ulteriori informazioni, vedere KB43491.
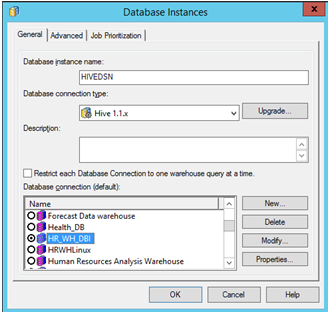
Selezionare il "Nome origine dati" creato in precedenza per l'origine. Immettere il login utente e la password.
-
Importare le tabelle dall'origine: Andare a Schema -> Catalogo Warehouse -> Selezionare l'istanza database -> Trascinare le tabelle desiderate dall'origine e rilasciarle.

Salvare il catalogo e chiuderlo.
-
Creare attributi e metriche in base alle esigenze. Aprire un nuovo report MicroStrategy per generare la propria analisi.

Per connettersi tramite l'importazione di dati Web a Hortonworks Hive
Gli analisti aziendali e gli utenti finali possono avvalersi del flusso di lavoro di importazione dati di MicroStrategy Web per collegare e analizzare i dati proprio come farebbero con origini dati relazionali. I passaggi possono essere suddivisi in tre aree concettuali: Connessione, importazione e analisi.
Di seguito viene riportata la finestra di connettività per l'importazione dati di MicroStrategy Web, in collegamento a Hortonworks Hive.
-
Selezionare il motore query. Selezionare il motore da collegare tramite la schermata di importazione dati di MicroStrategy.
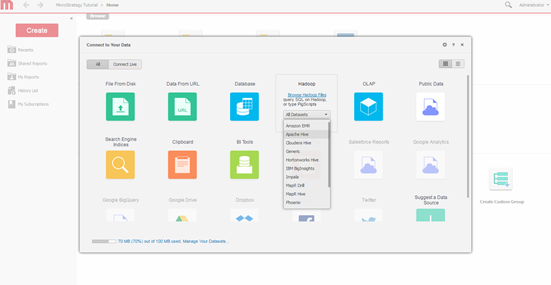
-
Selezionare le opzioni di importazione. Selezionare se creare una query, digitare una query o scegliere delle tabelle. Il metodo di scelta delle tabelle è consigliato perché consente di sfruttare al massimo le capacità di modellazione di MicroStrategy.

-
Creare una connessione Definire una nuova connessione al sistema Hadoop.

-
Selezionare le tabelle Selezionare le tabelle da cui sarà possibile accedere ai dati.
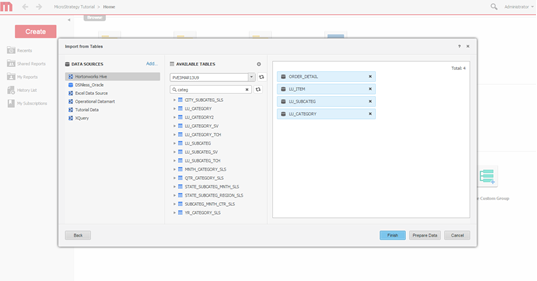
-
Modellare i dati. È inoltre possibile modellare le tabelle, modificare il nome degli attributi e delle metriche, escludere colonne dall'importazione, ecc.

-
Definire la modalità di accesso ai dati Scegliere se pubblicare i dati come un cubo in memoria o tramite la modalità di connessione in tempo reale.
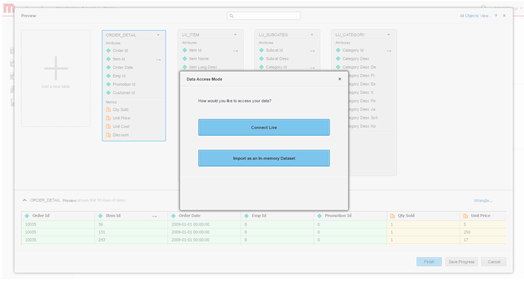
- Creare il dossier.
Per connettersi tramite Hadoop Gateway
È possibile utilizzare Hadoop Gateway dall'importazione dati di MicroStrategy Web, attenendosi al flusso di lavoro standard di importazione dei dati:
- Creare una connessione al cluster Hadoop/HDFS
- Navigare alle cartelle e importarle da HDFS
- Pulire i dati (opzionale)
- Pubblicare i dati come un cubo in memoria in MicroStrategy Intelligence Server e analizzare i dati attraverso un dossier.
Di seguito vengono riportati i dettagli per ognuno dei passaggi.
-
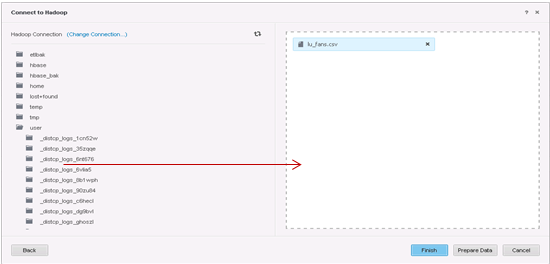
Creare una connessione.

-
Selezionare le tabelle da importare.
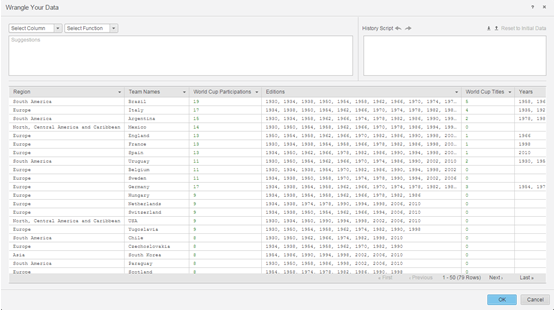
-
Preparare i dati utilizzando Data Wrangler.
- I passaggi successivi sono quindi la pubblicazione dei cubi in memoria in MicroStrategy Intelligence Server e l'utilizzo dell'interfaccia di Esplorazione visiva per creare un dossier.