Strategy ONE
Prerequisites
Administrators should verify that all environment settings are tuned to accommodate the cube to be published. The settings are dependent on data volume. For more information about the environment settings, see the following sections:
See the Tech Note on MSIFileTables for more information , (The information in the knowledge base article is applicable to Intelligence Server 10.x.)
Hardware configuration settings
Turn Off NUMA. For optimum performance with PRIME in-memory cubes, you must turn off NUMA.
Intelligence Server level settings
The Intelligence Server level settings are:
Number of connections by priority
All Data Import cube publishing jobs are currently initiated as low-priority jobs. The Number of connections by priority setting controls the number of processes that are available to in-parallel fetch data from external locations and read into memory. This setting specifies the total pool of processes available at the server level for the specific type of Data Import.
For OLAP and MTDI: Database, Hadoop, OLAP, Search index
- In MicroStrategy Developer, expand Administration, expand Configuration Managers, and select Database Instances.
- Right-click the database instance for which you want to define job prioritization and choose Edit.
- In the Database Instance editor, select the Job Prioritization tab.
-
In the Number of connections by priority section, enter the number of connections in the Low field.
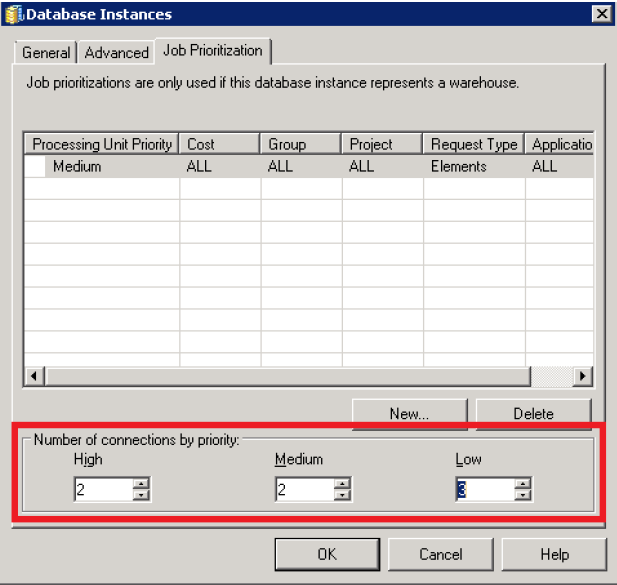
Click Help for more information about the Job Prioritization tab.
- Click OK.
For MTDI: File from URL
- In MicroStrategy Developer, from the Administration menu, select Server, and then select Configure MicroStrategy Intelligence Sever.
- In the MicroStrategy Intelligence Server Configuration editor, expand Governing Rules, expand Default, and select Import Data.
-
In the Number of connections by priority section, enter the number of connections in the Low field.

- Click OK.
Other external sources: Facebook, Google Analytics, Google Big Query, Drop Box, Google Drive, Salesforce, Twitter
Each pool of Data Import processes can have up to 20 threads.
Query execution time
The Query execution time setting needs to be set appropriately to ensure that each process trying to fetch data in-parallel has enough time to fetch data completely. Values of 0 or -1 indicate infinite time (no limit).
For OLAP and MTDI: Database, Hadoop, OLAP, Search index
- In MicroStrategy Developer, expand Administration, expand Configuration Managers, and select Database Instances.
- Right-click the database instance for which you want to define job prioritization and choose Edit.
- In the Database Instance editor, select the database connection and click Modify…
- In the Database Connections dialog box, click the Advanced tab.
-
Set the Maximum query execution time (sec) field. This field defines the maximum amount of time a single pass of SQL can execute on the database.
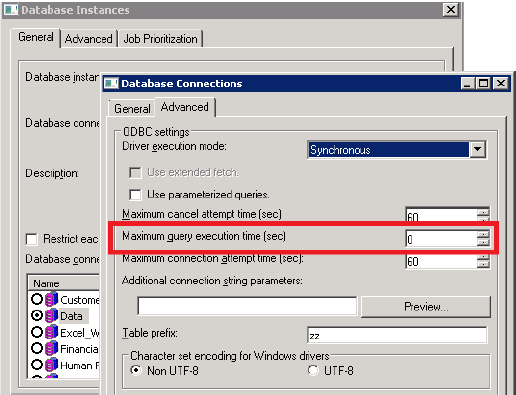
- Click OK to close the Database Connections dialog box.
- Click OK to close the Database Instance editor.
For other sources
The Query execution timeout is internally set to 0 (infinite).
Project configuration
For project configuration, see
Result sets
- In MicroStrategy Developer, right-click on the project and choose Project Configuration…
- In the Project Configuration editor, expand Governing Rules, expand Default, and choose Result sets.
- Verify that the fields are set appropriately. The following figure shows a sample from a standard project.

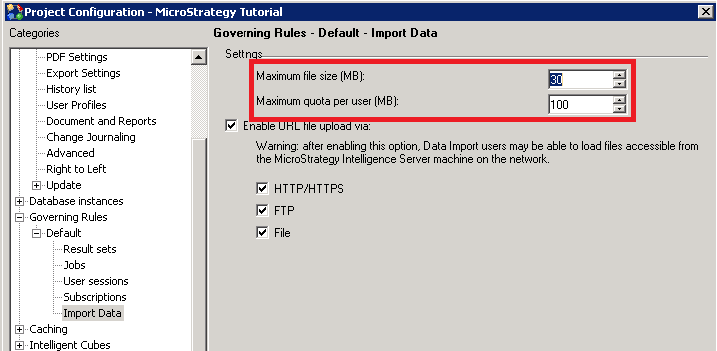
Data import specific
- In MicroStrategy Developer, right-click on the project and choose Project Configuration…
- In the Project Configuration editor, expand Governing Rules, expand Default, and choose Import Data.
- Verify that the fields are set appropriately. The following figure shows a sample from a standard project.
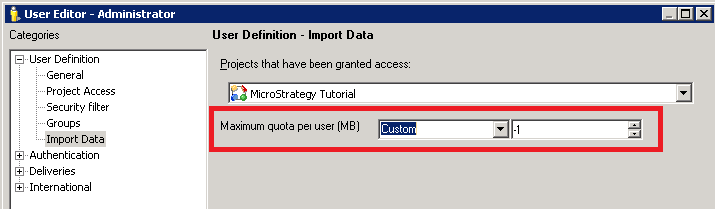
User specific (if needed)