Strategy ONE
Partitioning cubes
Before MicroStrategy 10.0, all datasets were non-partitioned. Starting in MicroStrategy 10.0, partitioning is optional. If you are not partitioning the data, the published cube consists of one table.
A major advantage of MicroStrategy 10.0 cubes is the ability to partition cubes. While OLAP cubes were limited to 2 billion rows, PRIME OLAP cubes can be divided into partitions and each partition can contain up 2 billion rows. This advantage allows PRIME OLAP cubes to increase in capacity and scalability through partitions.
For more information, see the following sections:
- Number of cube partitions
- Selection of partition key (distribution key)
- Notes about partitioning
- Where to define the partition
Number of cube partitions
The number of partitions that can be defined for a single cube depends on the number of cores used by Intelligence Server. If Intelligence Server is restricted to a certain number of cores, through CPU affinity, then the PRIME OLAP cube is restricted by the limit. Also note that partitioning is performed on a single attribute.
Selection of partition key (distribution key)
- MicroStrategy PRIME currently supports only one partitioning key/attribute for the entire dataset. All tables that have the partition attribute will have their data distributed along the elements of that attribute.
- MicroStrategy PRIME supports the following data types for partitioning:
- Numeric
- STRING/TEXT
- DATE
All data is distributed using HASH schemes.
- The partition attribute is typically dictated by specific application needs. Below are some general guidelines for identifying a good partition attribute.
- Partitioning is effective when each partition holds at least 250K rows.
- Some of the largest fact tables in the application are typically good candidates for partitioning and thus influence the choice of the partition attribute. They need to be partitioned to accommodate large data sizes and to take advantage of the PRIME parallel processing architecture.
- Data should be partitioned in such a way that it allows for the most number of partitions to be involved in any question that is asked of the application. Attributes that are frequently used for filtering or selections do not make for good partition attributes, as they tend to push the analysis towards specific sets of partitions thus minimizing the benefits of parallel processing.
- The partition attribute should allow for near uniform distribution of data across the partitions, so that the workload on each partition is evenly distributed.
- Columns on which some of the larger tables in the application are joined make for good partition attributes.
- Typically, the number of partitions should be equal to half the number of logical cores available to the PRIME server. This maximizes CPU usage to offer the best possible performance during cube publishing. Setting the number of partitions larger than the total number of CPUs will hinder performance.
- Each partition can hold a maximum of 2 billion rows. Define the number of partitions accordingly.
- The minimum number of partitions is dictated by the number of rows in the largest table divided by 2 billion, since each partition can hold up to 2 billion records. The maximum number of partitions is dictated by the number of cores on the box. The number of partitions should typically be between the minimum and maximum, and closer to half the number of logical cores.
- In some cases, it is possible that a single column does not meet these criteria, in which case either the dataset/application is not a good fit for partitioning or a new column needs to be added to the largest table. Such an approach can generally be applied to partition only the single largest fact table in the dataset.
Notes about partitioning
- Partitioning limits the types of aggregations that can be quickly performed on the raw data. Functions that can be handled include distributive functions (such as SUM, MIN, MAX, COUNT, PRODUCT), or semi-distributive functions (such as STD DEV, VARIANCE) that can be re-written using distributive functions.
- Scalar functions (such as Add, Greatest Date/Time Functions, String manipulation functions) are supported.
- DISTINCT COUNTs on the partition attribute are supported.
- Derived metrics using any of the MicroStrategy 250+ functions are supported.
- For non-distributive functions, you may encounter high CPU and memory consumption.
- MicroStrategy 10.2 supports automatic in-memory partitioning for super cubes.
Where to define the partition
MicroStrategy 10.0 supports one partitioning key (attribute) for the entire dataset.
The minimum number of partitions is dictated by the number of rows in the largest table divided by 2 billion, since each partition can hold up to 2 billion records. The maximum number of partitions is dictated by the number of cores used by Intelligence Server.
Defining the partition for OLAP Cubes
- In MicroStrategy Developer, right-click on the intelligent cube and select Edit.
- In the Intelligent Cube Editor, choose Data > Configure Intelligent Cube…
-
In the Intelligent Cube Options dialog box, expand Options and select Data Partition.
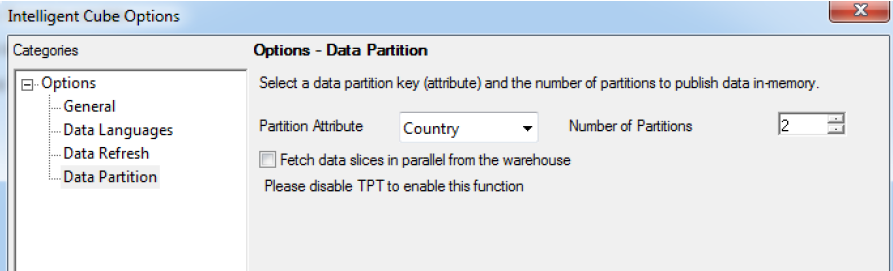
Defining the partition for Super Cubes
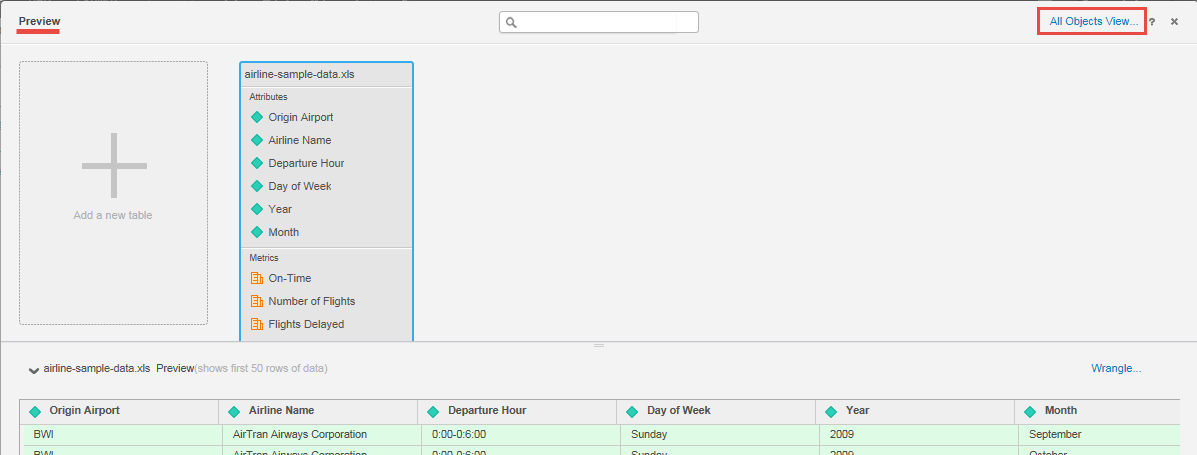
- Select the data set and click Prepare Data.
-
Click All Objects View.
By default, the Partition Attribute pull-down menu is set to Automatic, which allows MicroStrategy Web to set the number of partitions.
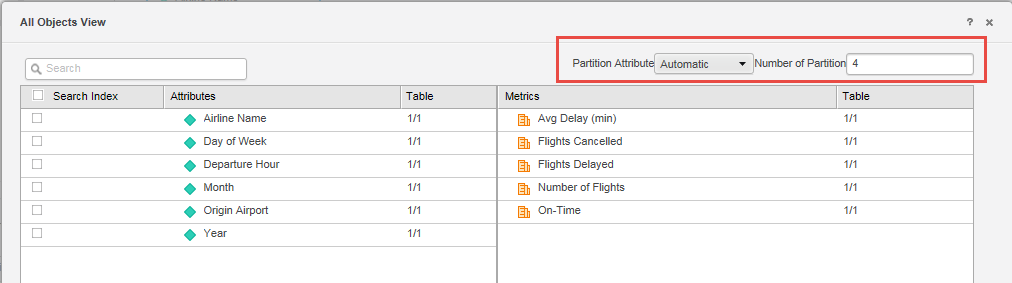
By choosing Automatic, if the largest table is >= 1M rows, MicroStrategy will choose the attribute with highest cardinality attribute in the largest table and do the partitioning accordingly. Otherwise, there will be no partition for this data import cube.
To improve performance, MicroStrategy suggests modifying the default value (4) to be the half of the number of Intelligence Server CPU cores.