MicroStrategy ONE
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (ADLS2) is a data lake platform that is fully integrated with Azure Blob Storage. MicroStrategy Cloud Object Connector provides access to ADLS2 to quickly browse folders and files and import them into MicroStrategy cubes.
Explore the following topics on this page:
Prepare Connection Parameters
For Cloud Object Connector to successfully browse the ADLS2 file system, you need a storage account with a hierarchical namespace. For more details on creating a storage account, please refer to the Microsoft documentation.
After the storage account is created, two access keys are granted. Either one can be used to create a connection.
Create a DBRole
Access the Azure Data Lake Storage Gen2 Cloud Object Connector in MicroStrategy Web or Workstation.
- Web
- Workstation
- Choose Add Data > New Data.
-
Find and select Azure Data Lake Storage Gen2 Cloud Object connector from the data source list.
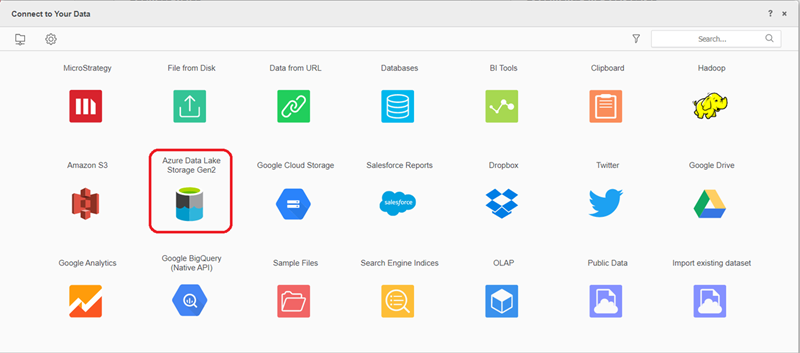
-
Next to Data Sources, click New Data Source
 to add a new connection.
to add a new connection. 
-
Enter your connection credentials.
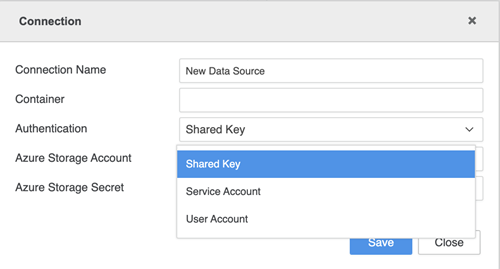
- Connection Name: A name for the new connection
- Container: The container you want access
- Authentication: The authentication method you want to use
- Directory (tenant) ID: The ID associated with each subscription
- Azure Storage Account: The storage account containing you Azure Storage data objects
- Azure Storage Secret: The secret associated with the Azure Storage
-
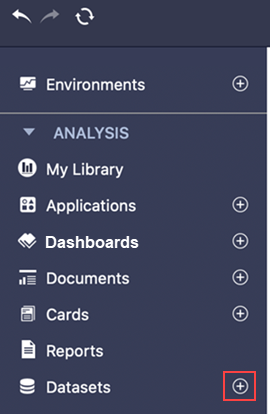
In the left panel, next to Datasets, click Create a new dataset
.
-
Find and select Azure Data Lake Storage Gen2 Cloud Object connector from the data source list.
-
Next to Data Sources, click New Data Source
to add a new connection.
-
Enter your connection credentials.
- Connection Name: A name for the new connection
- Directory (tenant) ID: The ID associated with each subscription
- Azure Storage Account: The storage account
- Container: The container you want access
- Client ID: The client ID used
- Client Secret: The client secret associated with the client ID
Import Data
Once you've successfully created the connector, you can import data into MicroStrategy.
- Select the newly created connection.
- Browse the folders or files under the specific container,
-
Double-click files or drag them into the right pane.
In the Preview pane, you can see the sample data and adjust the column type.
- Publish the cube to MicroStrategy with your selected data.
Limitations
Supported File Types
Only the following file types are supported:
- .json
- .parquet
- .avro
- .orc
- .csv
- Delta format
Select Folders
When selecting the entire folder, the folder must meet the following requirements:
- All files under the folder need to have the same file types. A dialog will prompt you to choose the file type
- All files share the same schema
-
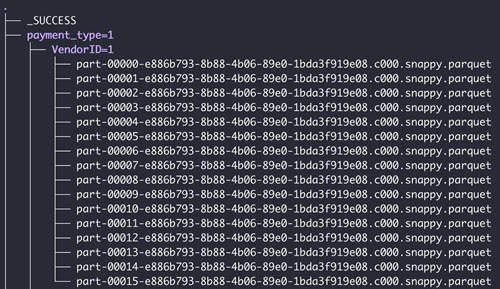
If the folder has sub-folders, the sub-folders should be in a valid partitioned format. The following is an example of a valid folder structure
Spark Limitations
- Only JSON files with each newline as a complete JSON can be read
- Parquet files that contain special characters (, ; { } \ = " .) cannot be read
- Parquet files with column data types as INT32(UINT_8)/(UNIT_16)/(UNIT_32)/(TIME_MILLIS) are not supported
- Columns with the binary type cannot be published in cube
- ORC files with field names prefixed with "_col" (e.g., _col0, _col1), where the file schema contains at least one nested structure, array, or map field, cannot be imported
Features
The following features are not supported:
- Uploading MicroStrategy files connecting to Cloud Object Connector
- Data wrangling in Data Import
- Defining geography in Data Import
- Advanced scheduling for Schedule Cube Publish
- Group tables in Data Import